Microsoft DeepSpeed achieves the fastest BERT training time
Good news! DeepSpeed obtains the fastest BERT training record: 44 minutes on 1024 NVIDIA V100 GPU. This is a 30% improvement over the best published result of 67 mins in end-to-end training time to achieve the same accuracy on the same number and generation of GPUs. This improvement does not come at the cost of excessive hardware resources but comes from improved software efficiency. For example, DeepSpeed can attain a staggering 64 teraflops of single GPU performance on a NVIDIA V100 GPU which is over 50% of the hardware peak.
In this blog post, we will discuss four technological improvements that enable DeepSpeed to achieve this record-breaking BERT training time.
- Highly optimized transformer kernels to improve compute efficiency
- Overlapping I/O with computation through asynchronous prefetching queue
- Sparse output processing to eliminate wasteful computation
- Layer-norm reordering for training stability and faster convergence
These optimizations not only benefit BERT; they are also applicable to many other transformer-based models such as RoBERTa, XLNet, and UniLM. Furthermore, besides the improvements mentioned for pre-training, DeepSpeed achieves up to 1.5x speedups for the downstream tasks, such as the fine-tuning for Bing-BERT SQuAD.
Performance Results for BERT Pretraining
Compared to SOTA, DeepSpeed significantly improves single GPU performance for transformer-based model like BERT. Figure 1 shows the single GPU throughput of training BERT-Large optimized through DeepSpeed, comparing with the two well-known PyTorch implementations from NVIDIA BERT and Hugging Face BERT. DeepSpeed reaches as high as 64 and 53 teraflops throughputs (corresponding to 272 and 52 samples/second) for sequence lengths 128 and 512, respectively, exhibiting up to 28% throughput improvements over NVIDIA BERT and up to 62% over HuggingFace BERT. We also support up to 1.8x larger batch size without running out of memory.
To achieve this performance, DeepSpeed implements a stochastic transformer which exhibits some level of non-deterministic noise without affecting overall convergence. In addition, DeepSpeed also implements a deterministic transformer kernel that is completely reproducible at the expense of a small performance regression of approximately 2% on average. Users can easily choose and switch between the two versions depending on their usage scenarios: Stochastic version pursues ultimate training performance goal, and deterministic version may save development time by better facilitating experimentation and debugging. We report performance numbers for both these kernels in Figure 1. The performance numbers were collected with a gradient accumulation step of 10 for all batch sizes and configurations, since on average an overall batch size used in practical scenarios range from a few hundred to a few thousand.
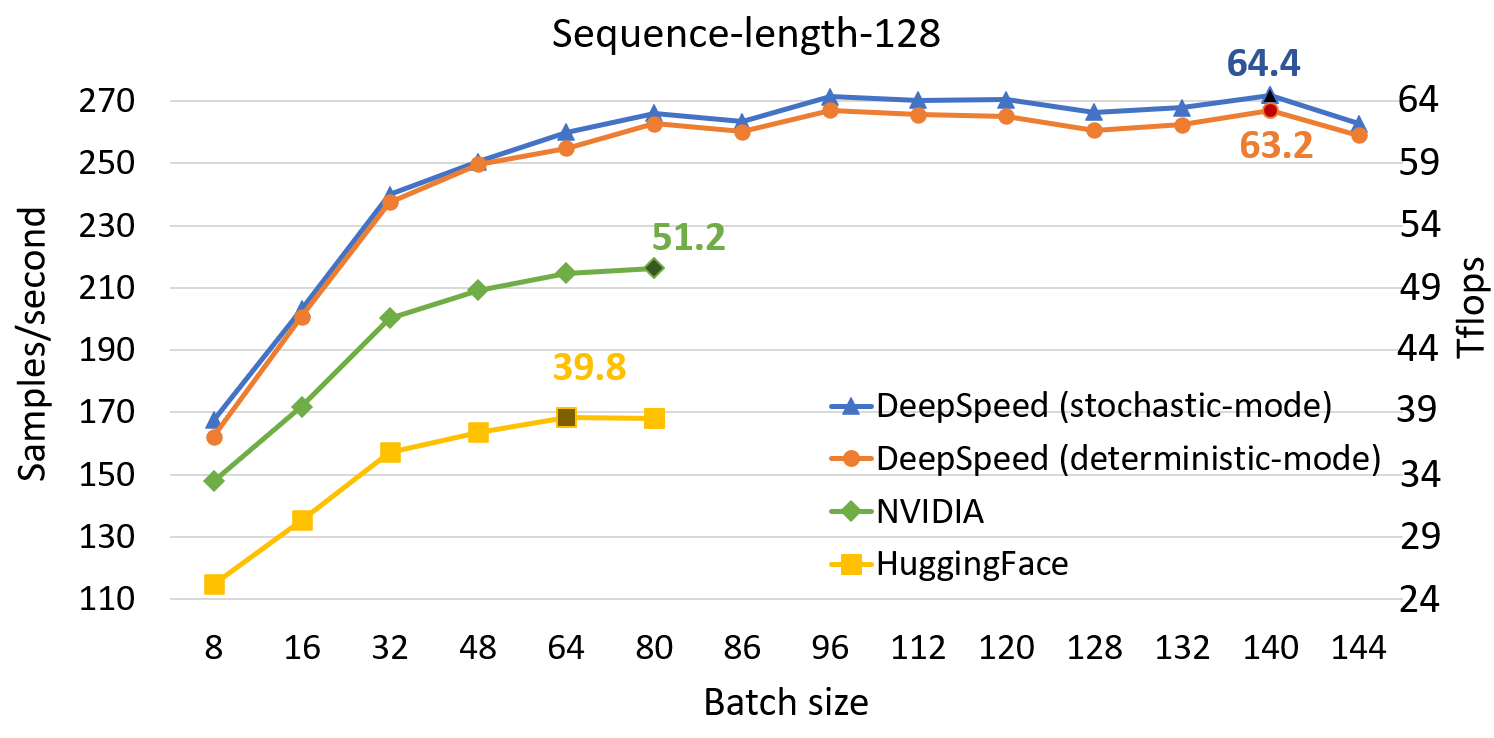
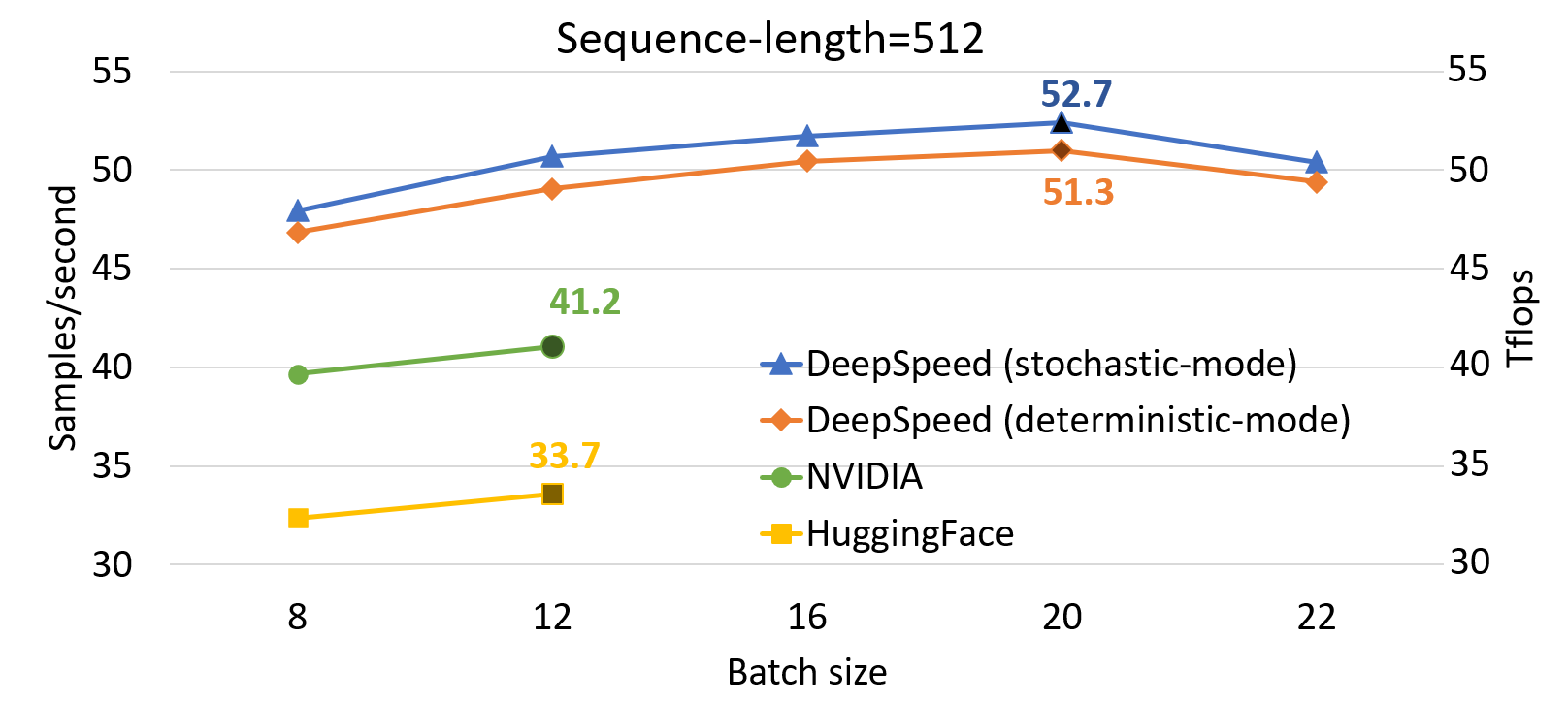
Figure 1: Performance evaluation of BERT-Large on a single V100 GPU, comparing DeepSpeed with NVIDIA and HuggingFace versions of BERT in mixed-sequence length training. The labeled points show the highest throughput of each implementation in teraflops (Tflops). DeepSpeed boosts throughput and allows for higher batch sizes without running out-of-memory.
Looking at distributed training across GPUs, Table 1 shows our end-to-end BERT-Large pre-training time (F1 score of 90.5 for SQUAD) using 16 to 1024 GPUs. We complete BERT pre-training in 44 minutes using 1024 V100 GPUs (64 NVIDIA DGX-2 nodes). In comparison, the previous SOTA from NVIDIA takes 47 mins using 1472 V100 GPUs. DeepSpeed is not only faster but also uses 30% less resources. Using the same 1024 GPUS,NVIDIA BERT takes 67 minutes using the same 1024 GPUs [1] BERT, whereas DeepSpeed takes 44 minutes, reducing training time by 30%. Similarly, on 256 GPUs, NVIDIA BERT takes 236 minutes while DeepSpeed takes 144 minutes (39% faster).
| Number of nodes | Number of V100 GPUs | Time |
|---|---|---|
| 1 DGX-2 | 16 | 33 hr 13 min |
| 4 DGX-2 | 64 | 8 hr 41 min |
| 16 DGX-2 | 256 | 144 min |
| 64 DGX-2 | 1024 | 44 min |
Table 1: BERT-Large training time using 1 to 64 DGX-2’s with DeepSpeed.
At the recent GTC 2020, NVIDIA announced the next generation hardware A100, which now offers 2.5X hardware peak performance over the V100 GPU. Assuming the A100 GPU allows us to obtain the same percentage of hardware peak performance (50%) as we obtained on V100 GPUs, we expect to obtain even higher throughput by combining our software optimizations with the new hardware. We project it would reduce BERT training time further to less than 25 minutes on a cluster of 1024 A100 GPUs.
Performance Results for Fine-Tuning Tasks
In addition to the performance benefits we show for the pre-training, we have evaluated the performance of our customized kernel for fine-tuning the downstream tasks. Tables 2 and 3 show the samples-per-second achieved when running Bing-BERT SQuAD on NVIDIA V100 using 16 and 32 GB of memory, using PyTorch and DeepSpeed transformer kernels. For the 16-GB V100, we can achieve up to 1.5x speedup while supporting 2x larger batch size per GPU. On the other hand, we can support as large as 32 batch size (2.6x more than Pytorch) using 32GB of memory, while providing 1.3x speedup for the end-to-end fine-tune training. Note, that we use the best samples-per-second to compute speedup for the cases that PyTorch runs out-of-memory (OOM).
| Micro batch size | PyTorch | DeepSpeed | Speedup (x) |
|---|---|---|---|
| 4 | 36.34 | 50.76 | 1.4 |
| 6 | OOM | 54.28 | 1.5 |
| 8 | OOM | 54.16 | 1.5 |
Table 2. Samples/second for running SQuAD fine-tuning on NVIDIA V100 (16-GB) using PyTorch and DeepSpeed transformer kernels.
| Micro batch size | PyTorch | DeepSpeed | Speedup (x) |
|---|---|---|---|
| 4 | 37.78 | 50.82 | 1.3 |
| 6 | 43.81 | 55.97 | 1.3 |
| 12 | 49.32 | 61.41 | 1.2 |
| 24 | OOM | 60.70 | 1.2 |
| 32 | OOM | 63.01 | 1.3 |
Table 3: Samples/second for running SQuAD fine-tuning on NVIDIA V100 (32-GB) using PyTorch and DeepSpeed transformer kernels.
BERT Highly Optimized Transformer Kernels
GPUs have very high peak floating-point throughput, but the default Transformer blocks in most framework implementations are far from reaching this peak. Figure 2 shows the structure of a Transformer block with the LayerNorm placed on the input stream of the two sublayers: Attention and Feed-Forward. To approach the GPU peak performance, we employ two lines of optimizations in our own Transformer kernel implementation: advanced fusion, and invertible operators.
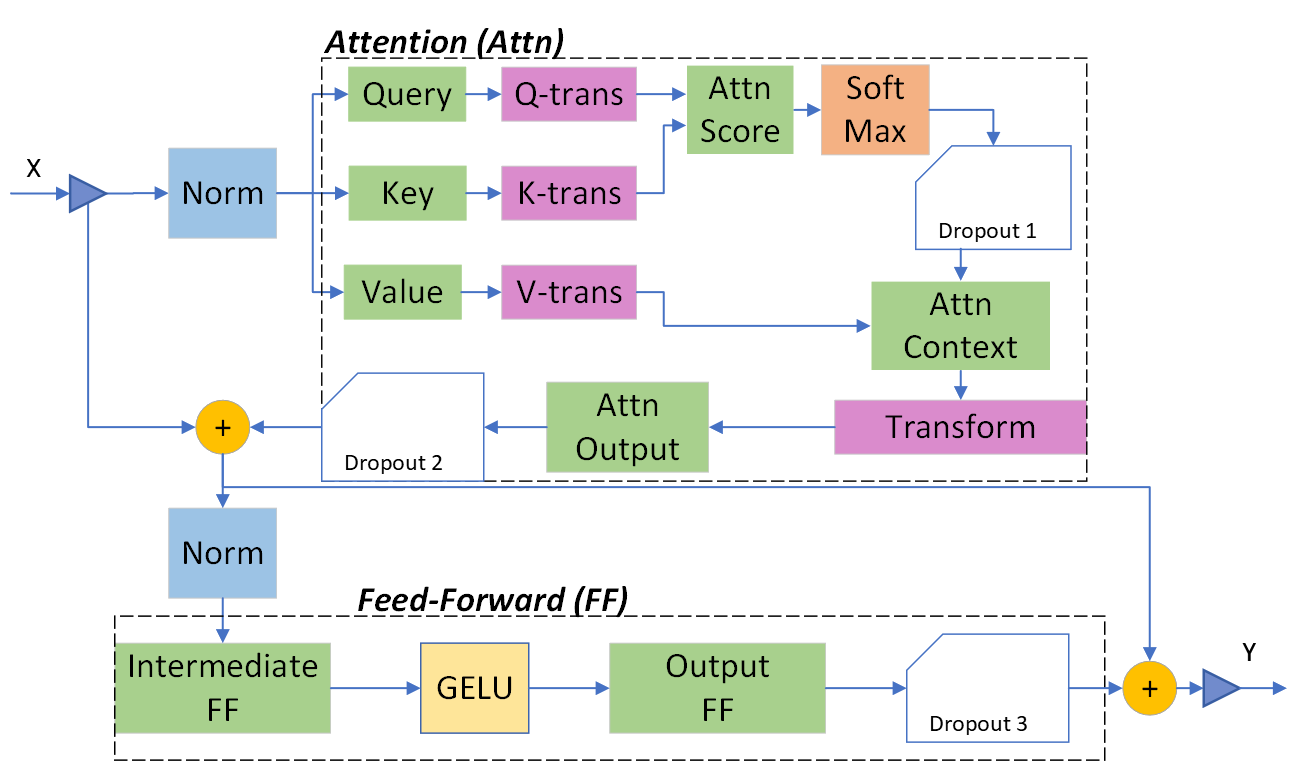
Figure 2: Transformer Layer with Pre-LayerNorm Architecture
(a) Advanced fused kernels to reduce data movement
We observe that transformer-based networks trigger many invocations of CUDA kernels operating in a producer-consumer fashion, adding a lot of cost for transferring data to and from global memory and overhead from kernel launching. Existing compiler-based approaches perform fine-grained fusion (e.g., fusion of element-wise operations), leading to missed fusion opportunities. In contrast, we fully exploit both fine-grain and coarse-grained fusion, tailored for Transformer blocks.
QKV and various fusions. We merge the three Query (Q), Key (K), and Value (V) weight matrices to dispatch a larger QKV GEMM to expose more parallelism and improve data locality on GPU’s shared memory and register files, as shown in Figure 3. Next, we combine the data-layout transformation of the QKV’s output matrix with the bias addition. We then partition the large QKV matrix into three transformed ones, used for the following self-attention computation.
As Figure 3 illustrates, we read the QKV matrix in consecutive rows (shown by red box), and write them in the three transformed Q, K, and V matrices. Since each matrix starts from a different offset, we may have uncoalesced access to the main memory. Thus, we use the shared memory as an intermediate buffer, in order to rearrange the data in a way that we can put the data in consecutive parts of memory. Even though we produce an uncoalesced pattern when accessing shared memory, we reduce the cost of uncoalesced access to main memory to better exploit memory bandwidth, resulting in 3% to 5% performance improvement in the end-to-end training.
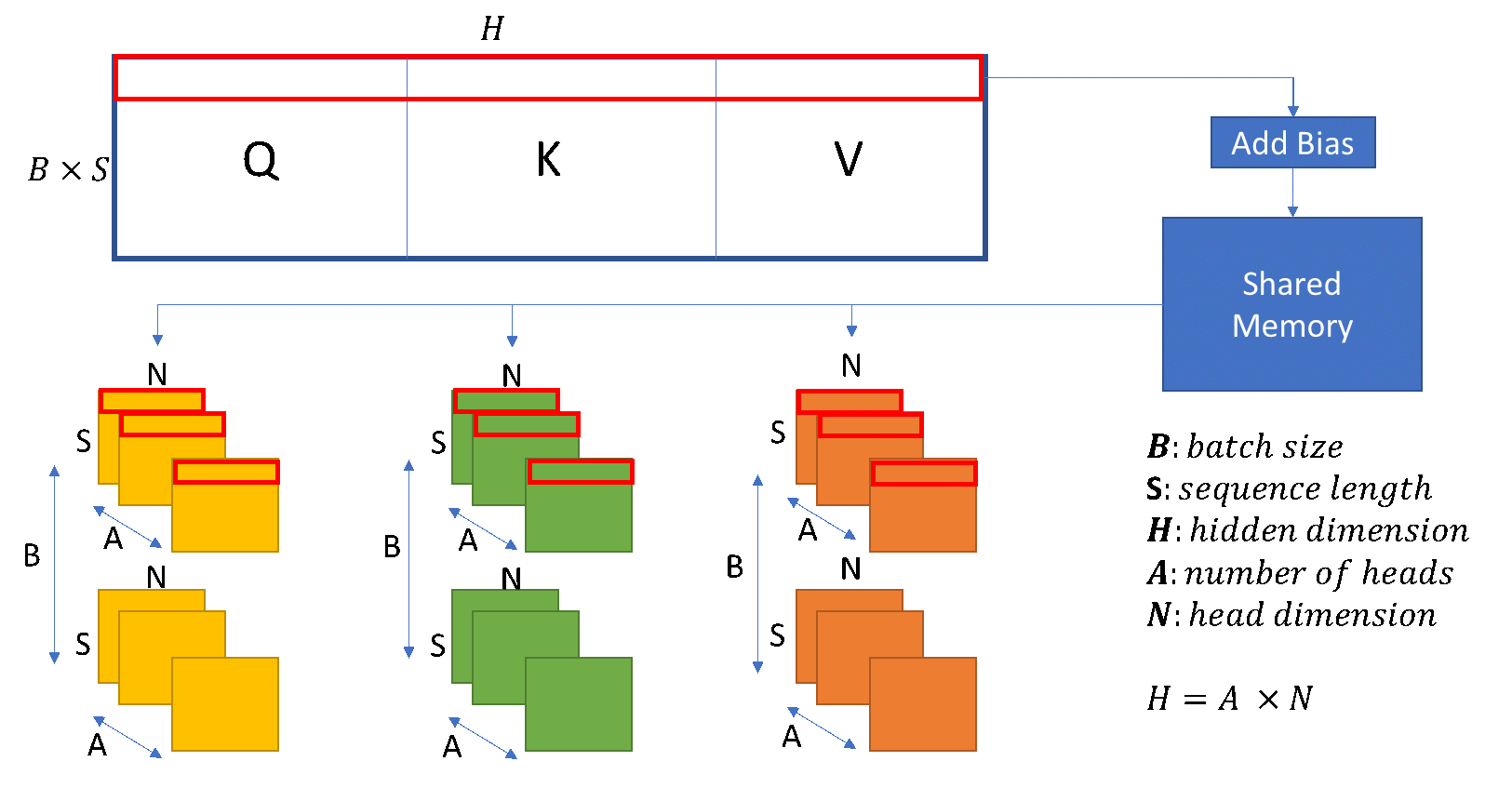
Figure 3: QKV’s GEMM and transform Kernel-Fusion
We perform additional fusions such as merging the addition of bias from the attention-output GEMM with the addition from the residual connection and also dropout, which allows accesses to happen in the register files and shared memory, which are orders of magnitude faster than the expensive write-back to the global memory.
Warp-level communication. To alleviate the synchronization overhead among parallel GPU cores and further increase the resource utilization of the fused kernels, we use the warp-level (data shuffle instructions) instead of the default inter-warp communication. Take the layer-normalization and SoftMax kernel as examples, we perform each reduction operation inside a warp, while distributing different reductions across different warps. This way, we alleviate the synchronization among the parallel threads and further increase the GPU resource utilization.
Stochastic vs deterministic kernels. DL training is generally robust to some level of stochasticity, and in some cases, controlled noises such as dropouts act as regularizer which improve generalization. In designing our transformer kernel, we embrace some level of stochasticity to improve throughput by allowing for limited data race conditions to exist in the kernel: We leverage implicit warp synchronous programming to achieve higher performance for the warp-level cooperative operations [3]. The lack of explicit warp level synchronization act as non-deterministic noise without affecting the overall convergence behavior of the transformer kernels while giving a decent throughput boost.
In addition, DeepSpeed also implements a non-stochastic transformer kernel with explicit warp synchronization that produces deterministic results at the expense of a small performance regression. Users can easily choose and switch between the two versions depending on their usage scenarios: Stochastic version pursues ultimate training performance goal, and deterministic version may save development time by better facilitating experimentation and debugging.
In our experiments, we use stochastic kernels for the pre-training BERT, while using non-stochastic kernels for fine-tuning to achieve fully reproducible results. We recommend using stochastic kernels for training tasks involving massive amounts of data such as pre-training, while using non-stochastic version when training with limited data such as in the case of fine-tuning for more consistent results.
Cost-effective rematerialization. When fusing kernels of the different operations, we observe that some operators are inexpressive to compute but incur expensive data movement cost, such as addition of bias and dropout. For these operations, we avoid saving their results in the forward pass, but instead recompute them during the backward pass, which turns out to be much faster than having their results written and reloaded from the main memory.
(b) Invertible operators to save memory and run large batches
We also observe that the intermediate activations from several operators in the Transformer blocks incur a large memory consumption, such as SoftMax and Layer Norm. For these operators, we drop the inputs to these layers to reduce the footprint of activation memory, by leveraging the fact that they are invertible functions, which are functions whose backward pass is independent of the inputs and can be formulated based only on the outputs [2]. Figure 4 and Figure 5 show the examples of the original implementation of SoftMax and Layer-Norm in PyTorch versus the invertible SoftMax implementation in DeepSpeed. Through this optimization, we are able to reduce the activation memory of the operator by half, and the reduced memory allows us to train with larger batch sizes, which once again improves GPU efficiency.
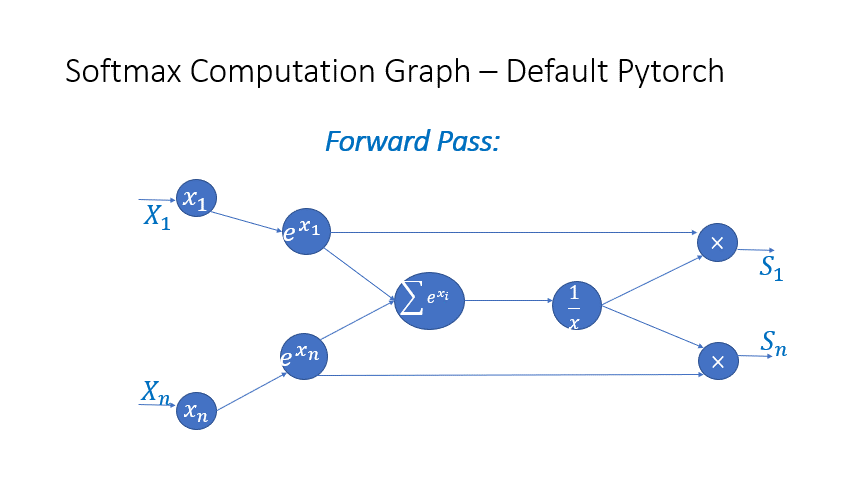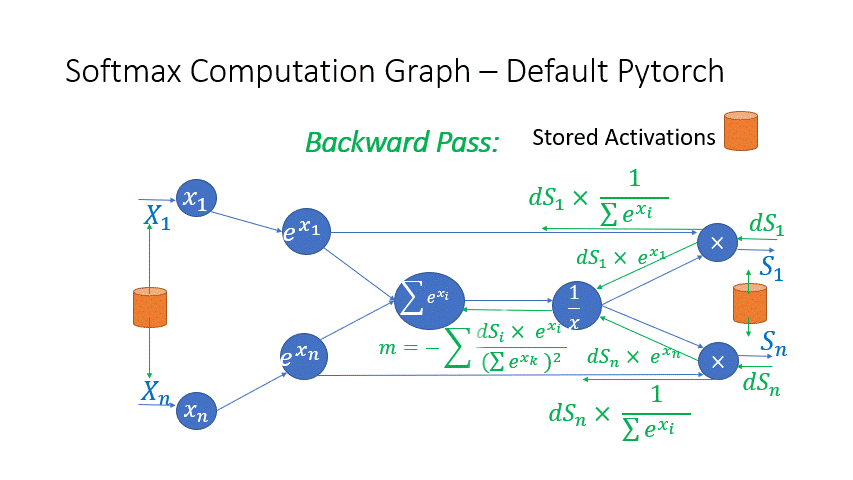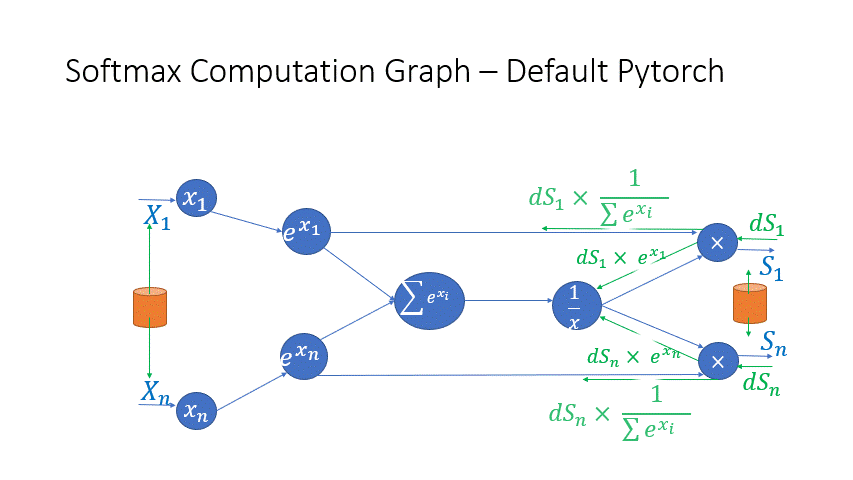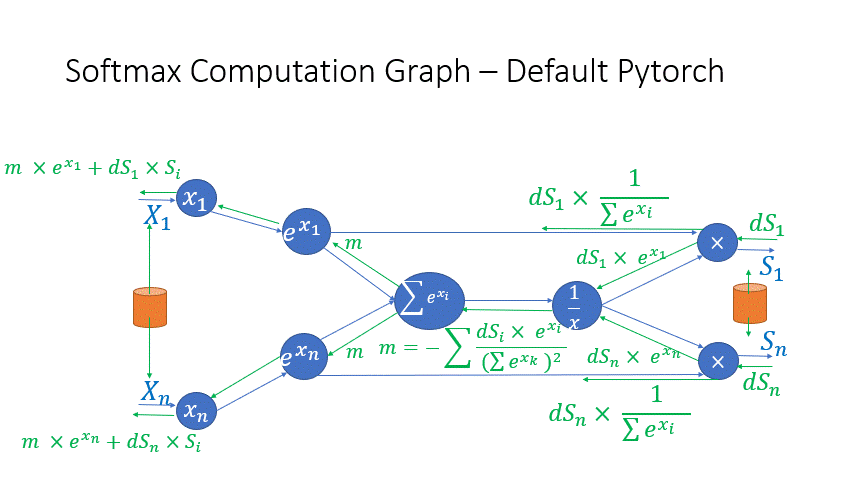
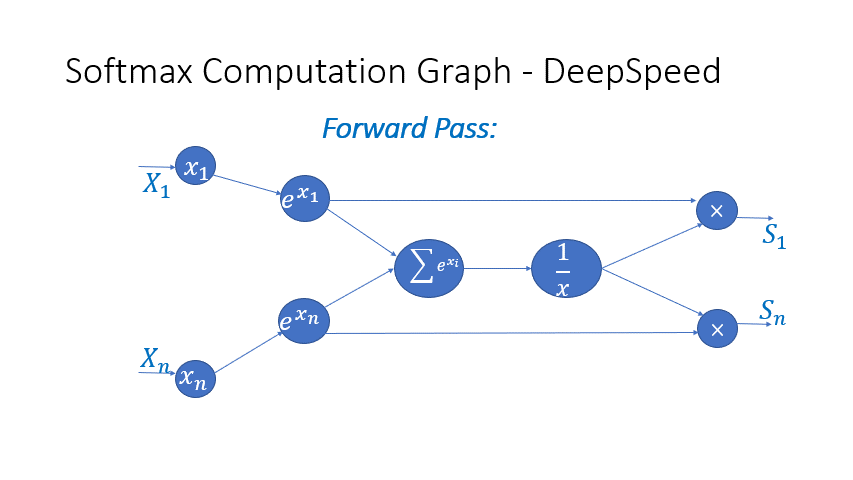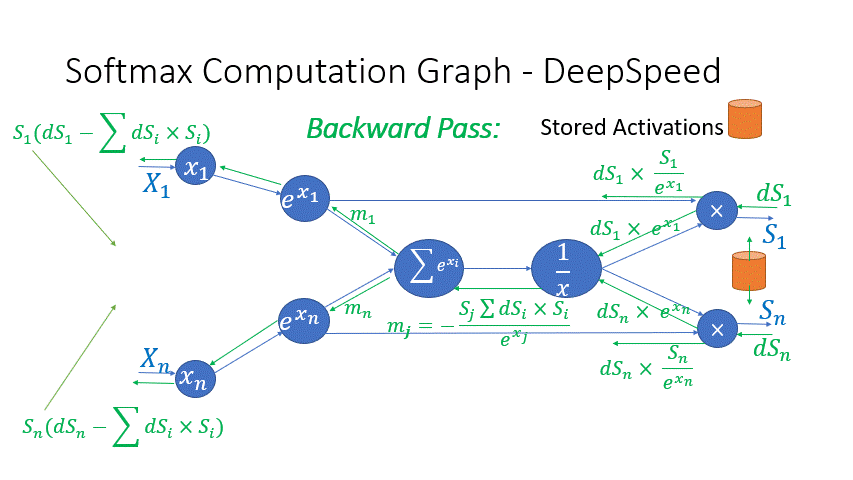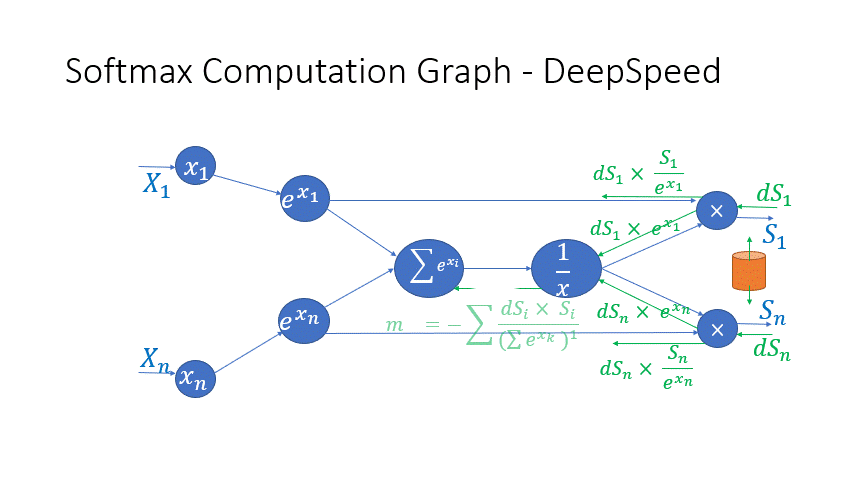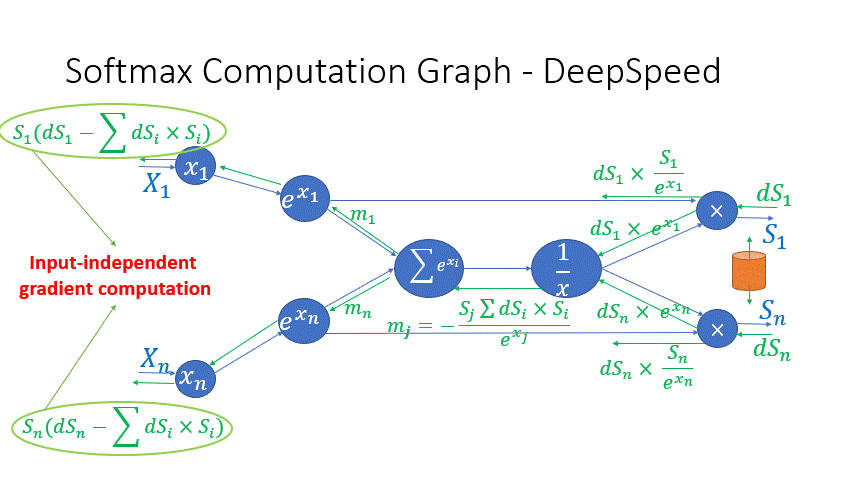
Figure 4: DeepSpeed invertible SoftMax operation versus Default PyTorch SoftMax operation
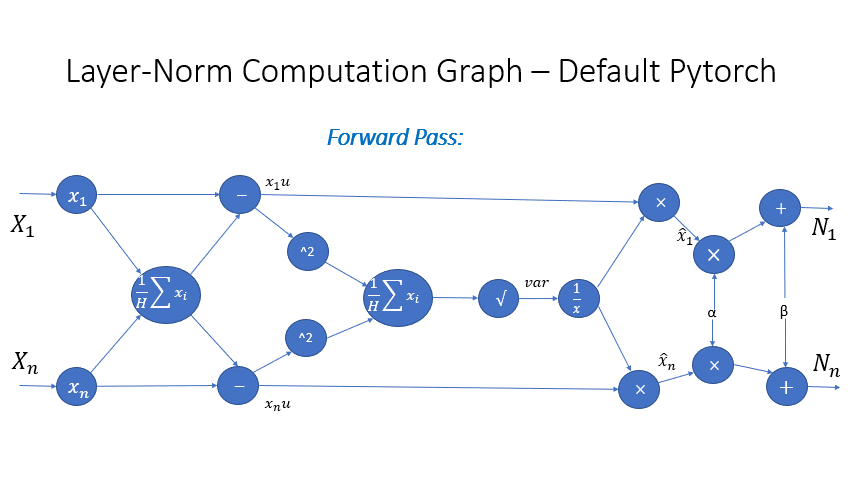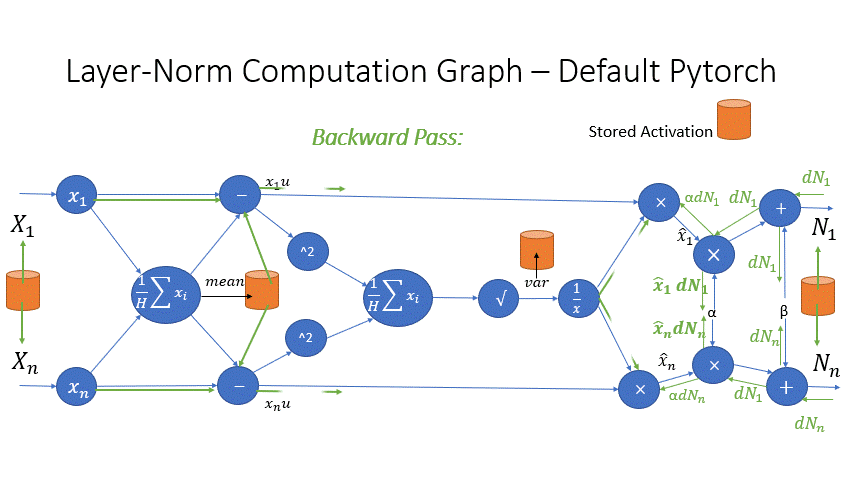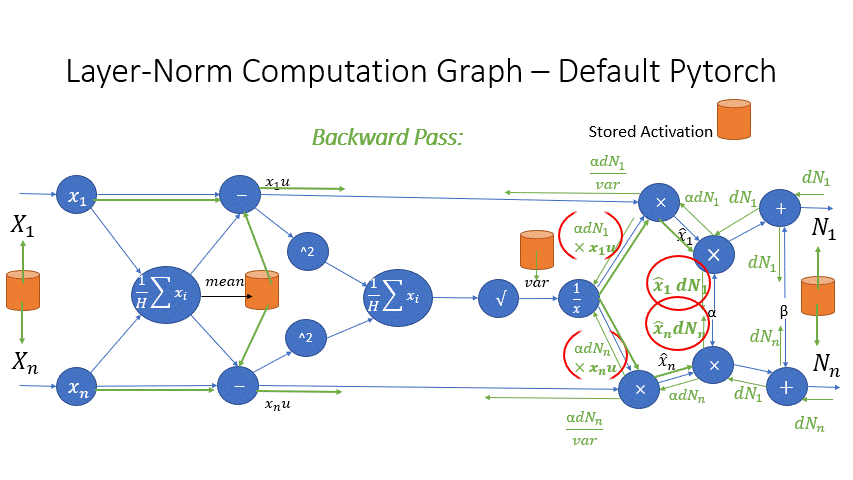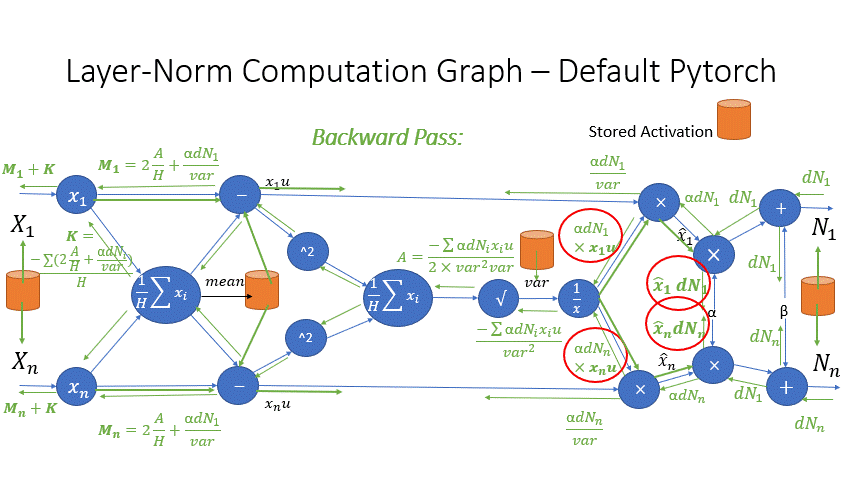
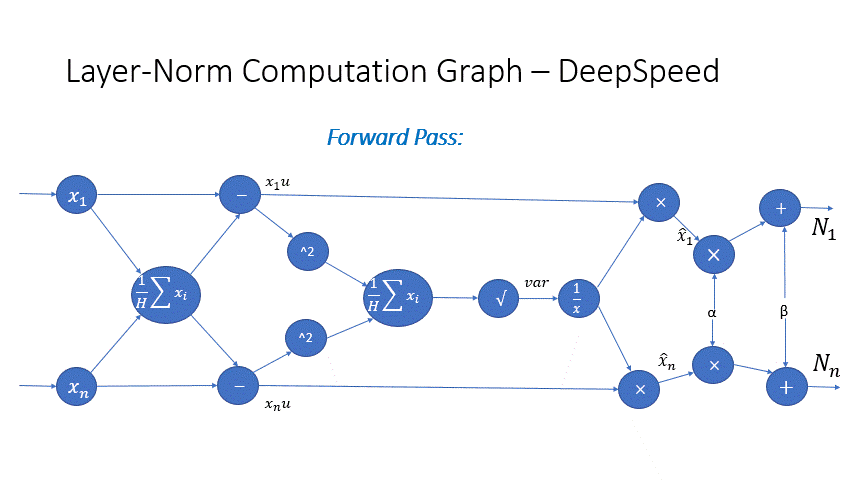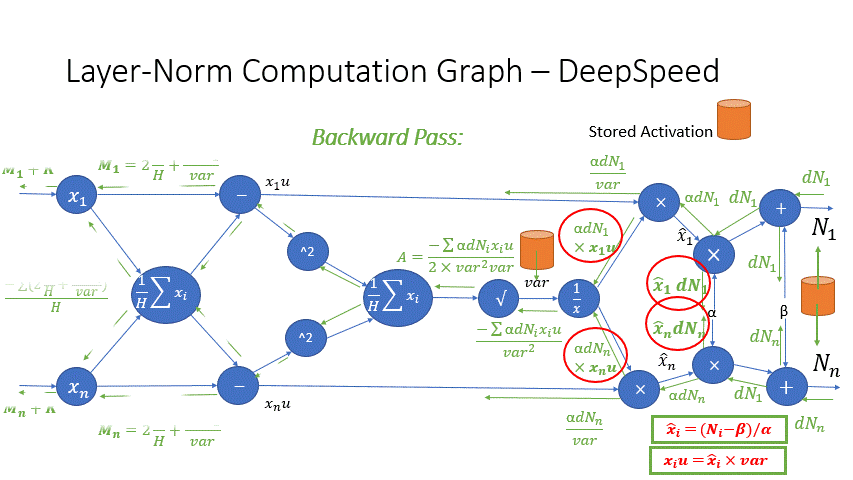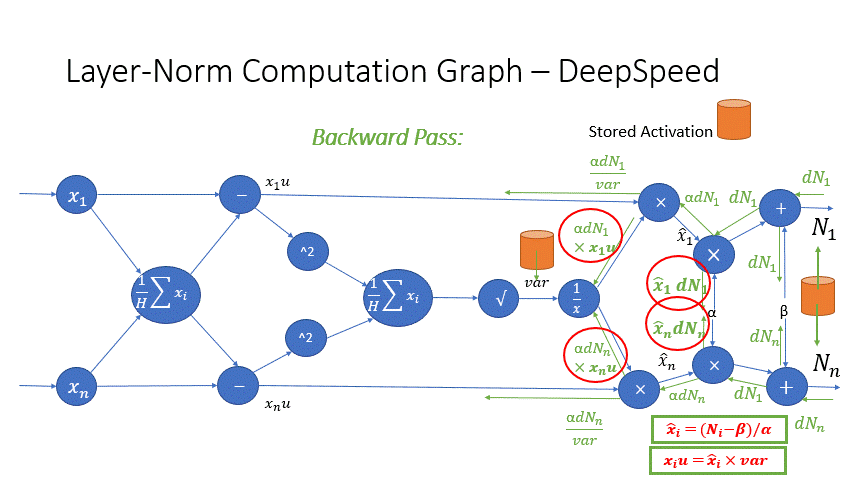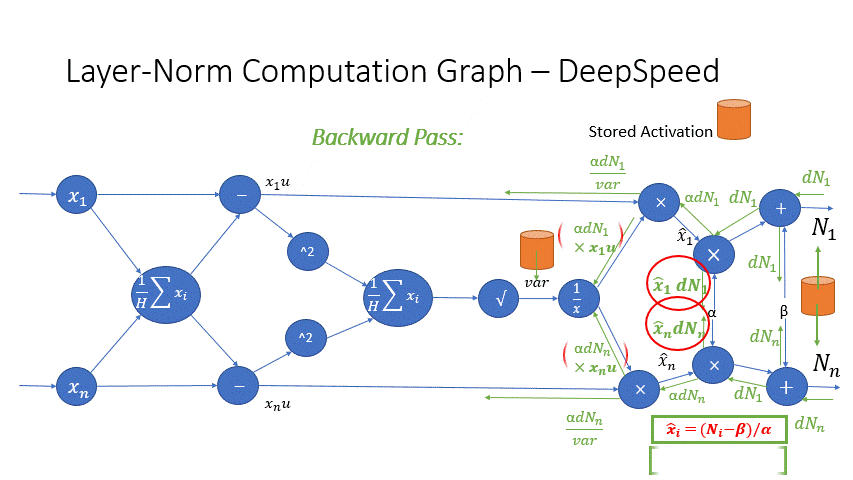
Figure 5: DeepSpeed invertible LayerNorm operation versus Default PyTorch LayerNorm operation
Overlapping I/O with Computation through Asynchronous Prefetching Queue
Beyond highly optimized transformer kernels, the BERT training has other performance limiting factors, e.g., data loading. We develop our own asynchronous worker which prefetches batches of data into a queue only at “safe points” – points when the CPUs are idle (e.g., right after asynchronously launching the forward pass). In this way, we make sure that there is no dequeuing and copying data from CPU to GPU when there is computation on the CPU side. This is different from the default PyTorch data loader, which can prefetch data at any points and cause performance interference. By using this method, we hide almost all I/O overhead, which accounts for 4% of the original training time.
Exploiting Sparsity of BERT’s Output Processing
We improve the end-to-end training time by 5.4% by recognizing and exploiting sparsity in BERT’s output processing. The output processing involves two steps: i) BERT projection from the hidden output dimension of the final transformer layer to the language vocabulary, using a matrix-matrix multiplication, and ii) a cross-entropy of the masked output tokens to the get each sequence’s prediction error. The cost of the first step is proportional to the vocabulary size, hidden output dimension and the sequence length, and can be as expensive as a transformer layer computation or more. However, only about 15% of the tokens are masked, and we only need the cross-entropy for the masked tokens. Therefore, the projection can be done as an efficient sparse computation. To do so, we discard the rows of the final transformer layer that corresponding to the non-masked tokens before doing the projection, reducing the computation cost of output processing by 85%.
Pre-LayerNorm vs Post-LayerNorm Architecture
We observe that with large batch size (e.g., 64K) the default BERT pre-training suffers from training instability, which can result in model divergence or convergence to bad/suspicious local optima. Further investigation shows that the default BERT has vanishing gradients issue. To mitigate the issue, we changed the placement of LayerNorm (Post-LayerNorm) by placing it only on the input stream of the sublayers in the Transformer block (called Pre-LayerNorm), a modification described by several recent works for neural machine translation. The Pre-LayerNorm results in several useful characteristics such as avoiding vanishing gradient, stable optimization, and performance gain. It allows us to train at aggregated batch size of 64K with increased learning rate and faster convergence.
To try out these optimizations and training recipe, please check out our BERT training tutorial and source code at the DeepSpeed GitHub repo.
References
[1] “NVIDIA Clocks World’s Fastest BERT Training Time and Largest Transformer Based Model, Paving Path For Advanced Conversational AI” https://devblogs.nvidia.com/training-bert-with-gpus/.
[2] S. R. Bulo, L. Porzi, and P. Kontschieder, “In-place activated batch norm for memory-optimized training of dnns” 2017. http://arxiv.org/abs/1712.02616.
[3] Mark Harris and Kyrylo Perelygin, “Cooperative Groups: Flexible CUDA Thread Programming”, https://devblogs.nvidia.com/cooperative-groups/.