BERT Pre-training
Note: On 08/15/2022 we have added another BERT pre-training/fine-tuning example at github.com/deepspeedai/Megatron-DeepSpeed/tree/main/examples_deepspeed/bert_with_pile, which includes a README.md that describes how to use it. Compared to the example described below, the new example in Megatron-DeepSpeed adds supports of ZeRO and tensor-slicing model parallelism (thus support larger model scale), uses a public and richer Pile dataset (user can also use their own data), together with some changes to the model architecture and training hyperparameters as described in this paper. As a result, the BERT models trained by the new example is able to provide better MNLI results than original BERT, but with a slightly different model architecture and larger computation requirements. If you want to train a larger-scale or better quality BERT-style model, we recommend to follow the new example in Megatron-DeepSpeed. If your goal is to strictly reproduce the original BERT model, we recommend to follow the example under DeepSpeedExamples/bing_bert as described below. On the other hand, the tutorial below helps explaining how to integrate DeepSpeed into a pre-training codebase, regardless of which BERT example you use.
In this tutorial we will apply DeepSpeed to pre-train the BERT (Bidirectional Encoder Representations from Transformers), which is widely used for many Natural Language Processing (NLP) tasks. The details of BERT can be found here: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
We will go through how to setup the data pipeline and how to run the original BERT model. Then we will show step-by-step how to modify the model to leverage DeepSpeed. Finally, we demonstrate the performance evaluation and memory usage reduction from using DeepSpeed.
Pre-training Bing BERT without DeepSpeed
We work from adaptations of huggingface/transformers and NVIDIA/DeepLearningExamples. We have forked this repo under DeepSpeedExamples/bing_bert and made several modifications in their script:
- We adopted the modeling code from NVIDIA’s BERT under
bing_bert/nvidia/. - We extended the data pipeline from Project Turing
under
bing_bert/turing/.
Training Data Setup
Note: Downloading and pre-processing instructions are coming soon.
Download the Wikipedia and BookCorpus datasets and specify their paths in the
model config file DeepSpeedExamples/bing_bert/bert_large_adam_seq128.json:
{
...
"datasets": {
"wiki_pretrain_dataset": "/data/bert/bnorick_format/128/wiki_pretrain",
"bc_pretrain_dataset": "/data/bert/bnorick_format/128/bookcorpus_pretrain"
},
...
}
Running the Bing BERT model
From DeepSpeedExamples/bing_bert, run:
python train.py \
--cf bert_large_adam_seq128.json \
--train_batch_size 64 \
--max_seq_length 128 \
--gradient_accumulation_steps 1 \
--max_grad_norm 1.0 \
--fp16 \
--loss_scale 0 \
--delay_allreduce \
--max_steps 10 \
--output_dir <path-to-model-output>
Enabling DeepSpeed
To use DeepSpeed we need to edit two files :
train.py: Main entry point for trainingutils.py: Training parameters and checkpoints saving/loading utilities
Argument Parsing
We first need to add DeepSpeed’s argument parsing to train.py
using deepspeed.add_config_arguments(). This step allows the application to
recognize DeepSpeed specific configurations.
def get_arguments():
parser = get_argument_parser()
# Include DeepSpeed configuration arguments
parser = deepspeed.add_config_arguments(parser)
args = parser.parse_args()
return args
Initialization and Training
We modify the train.py to enable training with DeepSpeed.
Initialization
We use deepspeed.initialize() to create the model, optimizer, and learning
rate scheduler. For the Bing BERT model, we initialize DeepSpeed in its
prepare_model_optimizer() function as below, to pass the raw model and
optimizer (specified from the command option).
def prepare_model_optimizer(args):
# Loading Model
model = BertMultiTask(args)
# Optimizer parameters
optimizer_parameters = prepare_optimizer_parameters(args, model)
model.network, optimizer, _, _ = deepspeed.initialize(args=args,
model=model.network,
model_parameters=optimizer_parameters,
dist_init_required=False)
return model, optimizer
Note that for Bing BERT, the raw model is kept in model.network, so we pass
model.network as a parameter instead of just model.
Training
The model returned by deepspeed.initialize is the DeepSpeed model
engine that we will use to train the model using the forward, backward and
step API. Since the model engine exposes the same forward pass API as
nn.Module objects, there is no change in the forward pass.
Thus, we only modify the backward pass and optimizer/scheduler steps.
Backward propagation is performed by calling backward(loss) directly with
the model engine.
# Compute loss
if args.deepspeed:
model.network.backward(loss)
else:
if args.fp16:
optimizer.backward(loss)
else:
loss.backward()
The step() function in DeepSpeed engine updates the model parameters as
well as the learning rate. Zeroing the gradients is handled automatically by
DeepSpeed after the weights have been updated after each step.
if args.deepspeed:
model.network.step()
else:
optimizer.step()
optimizer.zero_grad()
Checkpoints Saving & Loading
DeepSpeed’s model engine has flexible APIs for checkpoint saving and loading in order to handle the both the client model state and its own internal state.
def save_checkpoint(self, save_dir, tag, client_state={})
def load_checkpoint(self, load_dir, tag)
In train.py, we use DeepSpeed’s checkpointing API in the
checkpoint_model() function as below, where we collect the client model
states and pass them to the model engine by calling save_checkpoint():
def checkpoint_model(PATH, ckpt_id, model, epoch, last_global_step, last_global_data_samples, **kwargs):
"""Utility function for checkpointing model + optimizer dictionaries
The main purpose for this is to be able to resume training from that instant again
"""
checkpoint_state_dict = {'epoch': epoch,
'last_global_step': last_global_step,
'last_global_data_samples': last_global_data_samples}
# Add extra kwargs too
checkpoint_state_dict.update(kwargs)
success = model.network.save_checkpoint(PATH, ckpt_id, checkpoint_state_dict)
return
In the load_training_checkpoint() function, we use DeepSpeed’s loading
checkpoint API and return the states for the client model:
def load_training_checkpoint(args, model, PATH, ckpt_id):
"""Utility function for checkpointing model + optimizer dictionaries
The main purpose for this is to be able to resume training from that instant again
"""
_, checkpoint_state_dict = model.network.load_checkpoint(PATH, ckpt_id)
epoch = checkpoint_state_dict['epoch']
last_global_step = checkpoint_state_dict['last_global_step']
last_global_data_samples = checkpoint_state_dict['last_global_data_samples']
del checkpoint_state_dict
return (epoch, last_global_step, last_global_data_samples)
DeepSpeed JSON Config File
The last step to use DeepSpeed is to create a configuration JSON file (e.g.,
deepspeed_bsz4096_adam_config.json). This file provides DeepSpeed specific
parameters defined by the user, e.g., batch size per GPU, optimizer and its
parameters, and whether enabling training with FP16.
{
"train_batch_size": 4096,
"train_micro_batch_size_per_gpu": 64,
"steps_per_print": 1000,
"optimizer": {
"type": "Adam",
"params": {
"lr": 2e-4,
"max_grad_norm": 1.0,
"weight_decay": 0.01,
"bias_correction": false
}
},
"fp16": {
"enabled": true,
"loss_scale": 0,
"initial_scale_power": 16
}
}
In particular, this sample json is specifying the following configuration parameters to DeepSpeed:
train_batch_size: use effective batch size of 4096train_micro_batch_size_per_gpu: each GPU has enough memory to fit batch size of 64 instantaneouslyoptimizer: use Adam training optimizerfp16: enable FP16 mixed precision training with an initial loss scale factor 2^16.
That’s it! That’s all you need do in order to use DeepSpeed in terms of
modifications. We have included a modified train.py file called
DeepSpeedExamples/bing_bert/deepspeed_train.py with all of the changes
applied.
Enabling DeepSpeed’s Transformer Kernel
To enable the transformer kernel for higher performance, first add an argument
--deepspeed_transformer_kernel in utils.py, we can set it as False by
default, for easily turning on/off.
parser.add_argument('--deepspeed_transformer_kernel',
default=False,
action='store_true',
help='Use DeepSpeed transformer kernel to accelerate.')
Then in the BertEncoder class of the modeling source file, instantiate
transformer layers using DeepSpeed transformer kernel as below.
if args.deepspeed_transformer_kernel:
from deepspeed import DeepSpeedTransformerLayer, DeepSpeedTransformerConfig, DeepSpeedConfig
if hasattr(args, 'deepspeed_config') and args.deepspeed_config:
ds_config = DeepSpeedConfig(args.deepspeed_config)
else:
raise RuntimeError('deepspeed_config is not found in args.')
cuda_config = DeepSpeedTransformerConfig(
batch_size = ds_config.train_micro_batch_size_per_gpu,
max_seq_length = args.max_seq_length,
hidden_size = config.hidden_size,
heads = config.num_attention_heads,
attn_dropout_ratio = config.attention_probs_dropout_prob,
hidden_dropout_ratio = config.hidden_dropout_prob,
num_hidden_layers = config.num_hidden_layers,
initializer_range = config.initializer_range,
local_rank = args.local_rank if hasattr(args, 'local_rank') else -1,
seed = args.seed,
fp16 = ds_config.fp16_enabled,
pre_layer_norm=True,
attn_dropout_checkpoint=args.attention_dropout_checkpoint,
normalize_invertible=args.normalize_invertible,
gelu_checkpoint=args.gelu_checkpoint,
stochastic_mode=True)
layer = DeepSpeedTransformerLayer(cuda_config)
else:
layer = BertLayer(config)
self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(config.num_hidden_layers)])
All configuration settings come from the DeepSpeed configuration file and
command arguments and thus we must pass the args variable to here in this model.
Note:
batch_sizeis the maximum bath size of input data, all fine-tuning training data or prediction data shouldn’t exceed this threshold, otherwise it will throw an exception. In the DeepSpeed configuration file micro batch size is defined astrain_micro_batch_size_per_gpu, e.g. if it is set as 8 and prediction uses batch size of 12, we can use 12 as transformer kernel batch size, or using “–predict_batch_size” argument to set prediction batch size to 8 or a smaller number.local_rankin DeepSpeedTransformerConfig is used to assign the transformer kernel to the correct device. Since the model already runs set_device() before here, so does not need to be set here.stochastic_modehas higher performance when it is enabled, we enable it in pre-training, and disable it in fine-tuning.- The transformer kernel has its own parameters and so the checkpoint files generated with transformer kernel must to be loaded by the model with transformer kernel enabled (such as in fine-tuning).
For more details about the transformer kernel, please see DeepSpeed Transformer Kernel and DeepSpeed Fast-Bert Training.
Start Training
An example of launching deepspeed_train.py on four nodes with four GPUs each would be:
deepspeed --num_nodes 4 \
deepspeed_train.py \
--deepspeed \
--deepspeed_config deepspeed_bsz4096_adam_config.json \
--cf /path-to-deepspeed/examples/tests/bing_bert/bert_large_adam_seq128.json \
--train_batch_size 4096 \
--max_seq_length 128 \
--gradient_accumulation_steps 4 \
--max_grad_norm 1.0 \
--fp16 \
--loss_scale 0 \
--delay_allreduce \
--max_steps 32 \
--print_steps 1 \
--deepspeed_transformer_kernel \
--output_dir <output_directory>
See the Getting Started guide for more information on launching DeepSpeed.
Reproducing Fastest BERT Training Results with DeepSpeed
We achieve the fastest BERT training time while remaining competitive across the industry in terms of achieving F1 score of 90.5 or better on the SQUAD 1.1 dev set. Please follow the BERT fine-tuning tutorial to fine-tune your model that was pre-trained by transformer kernel and reproduce the SQUAD F1 score.
- We complete BERT pre-training in 44 minutes using 1024 V100 GPUs (64 NVIDIA DGX-2 nodes). In comparison, the previous SOTA from NVIDIA takes 47 mins using 1472 V100 GPUs. DeepSpeed is not only faster but also uses 30% less resources. Using the same 1024 GPUS, NVIDIA BERT is 52% slower than DeepSpeed, taking 67 minutes to train.
- Comparing with the original BERT training time from Google in which it took about 96 hours to reach parity on 64 TPU2 chips, we train in less than 9 hours on 4 DGX-2 nodes of 64 V100 GPUs.
- On 256 GPUs, it took us 2.4 hours, faster than state-of-art result (3.9 hours) from NVIDIA using their superpod on the same number of GPUs (link).
| Number of nodes | Number of V100 GPUs | Time |
|---|---|---|
| 1 DGX-2 | 16 | 33 hr 13 min |
| 4 DGX-2 | 64 | 8 hr 41 min |
| 16 DGX-2 | 256 | 144 min |
| 64 DGX-2 | 1024 | 44 min |
Our configuration for the BERT training result above can be reproduced with
the scripts/json configs in our DeepSpeedExamples repo. Below is a table containing a
summary of the configurations. Specifically see the
ds_train_bert_bsz64k_seq128.sh and ds_train_bert_bsz32k_seq512.sh scripts
for more details in
DeepSpeedExamples.
| Parameters | 128 Sequence | 512 Sequence |
|---|---|---|
| Total batch size | 64K | 32K |
| Train micro batch size per gpu | 64 | 8 |
| Optimizer | Lamb | Lamb |
| Learning rate | 11e-3 | 2e-3 |
Initial learning rate (lr_offset) |
10e-4 | 0.0 |
| Min Lamb coefficient | 0.01 | 0.01 |
| Max Lamb coefficient | 0.3 | 0.3 |
| Learning rate scheduler | warmup_exp_decay_exp |
warmup_exp_decay_exp |
| Warmup proportion | 0.02 | 0.02 |
| Decay rate | 0.90 | 0.90 |
| Decay step | 250 | 150 |
| Max training steps | 7500 | 7500 |
| Rewarm learning rate | N/A | True |
| Output checkpoint number | 150 | 160-162 |
| Sample count | 403M | 18-22M |
| Epoch count | 150 | 160-162 |
DeepSpeed Single GPU Throughput Results
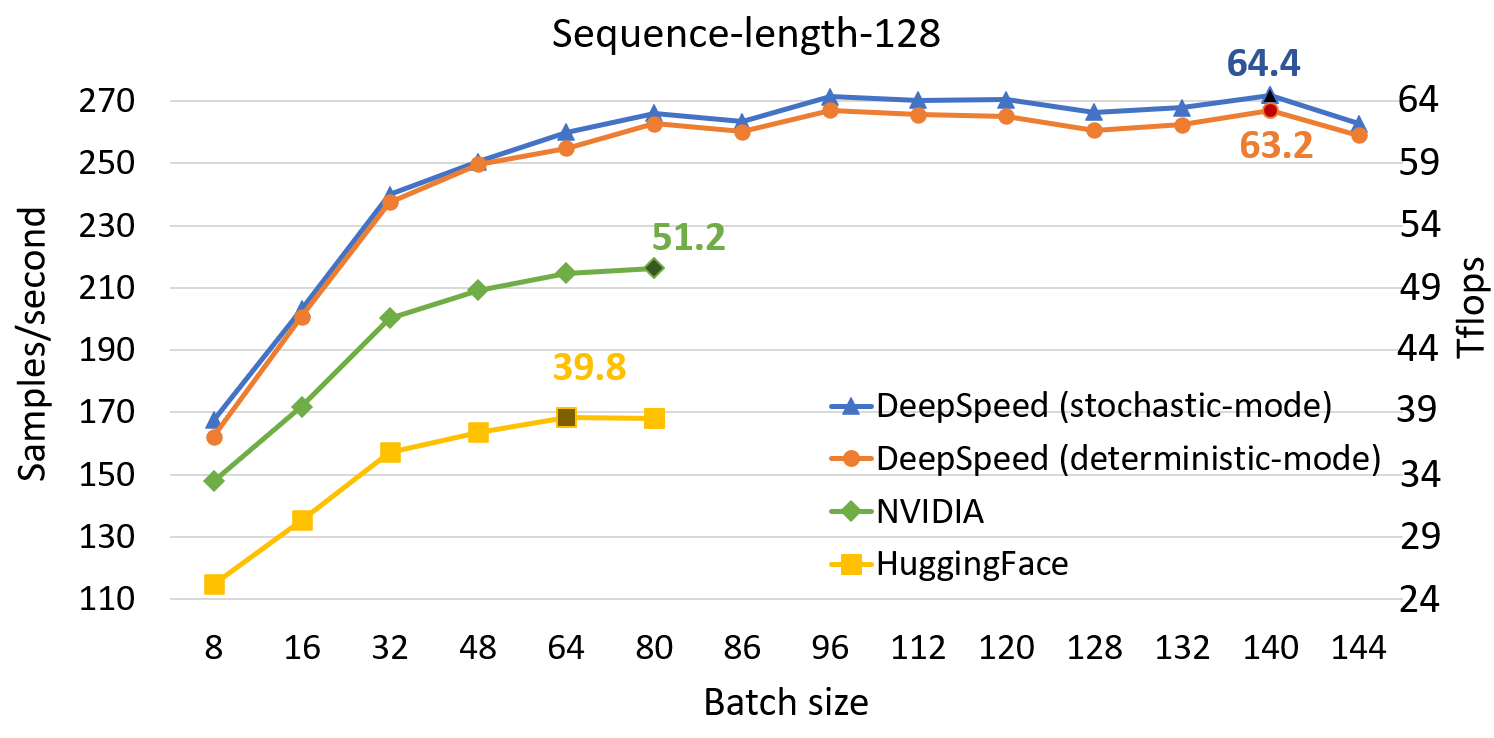
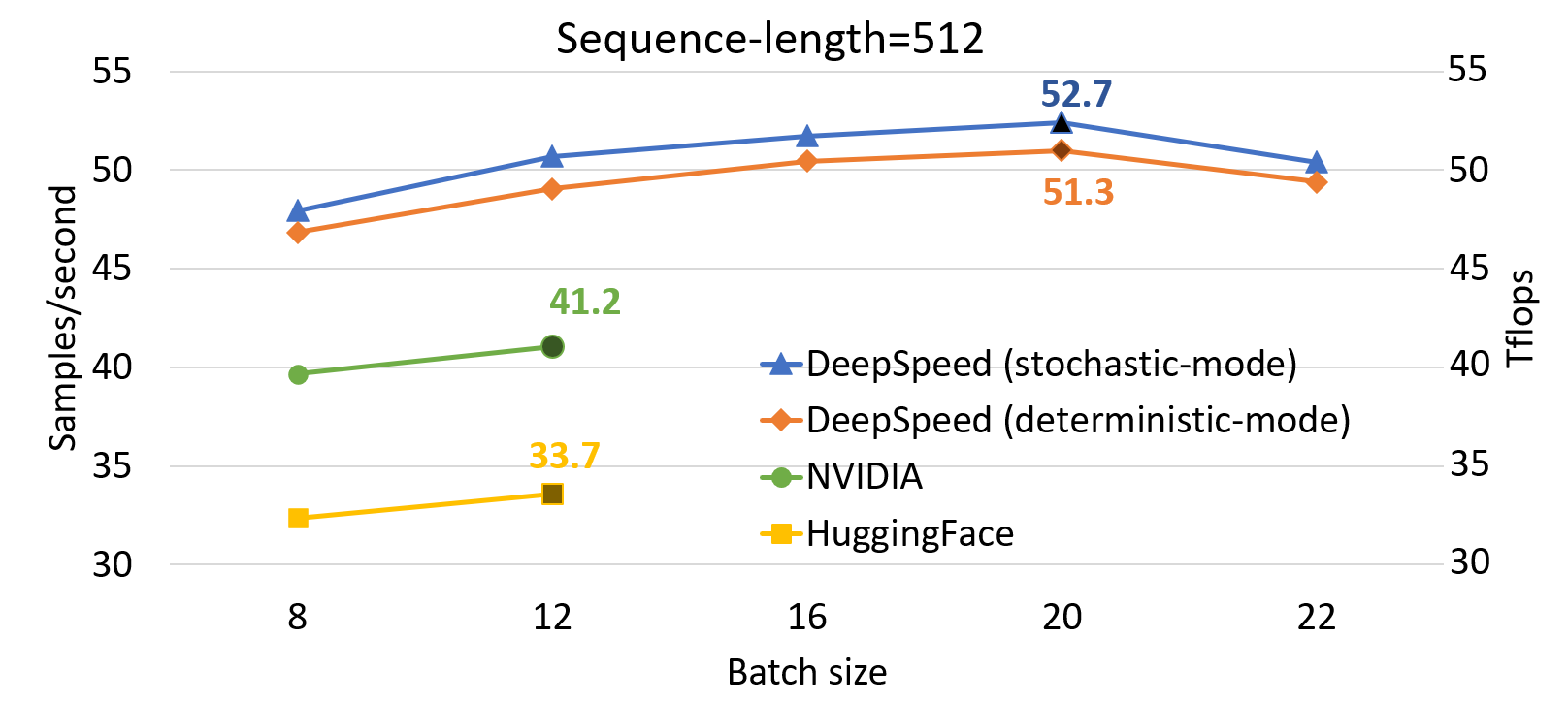
Compared to SOTA, DeepSpeed significantly improves single GPU performance for transformer-based model like BERT. Figure above shows the single GPU throughput of training BertBERT-Large optimized through DeepSpeed, compared with two well-known Pytorch implementations, NVIDIA BERT and HuggingFace BERT. DeepSpeed reaches as high as 64 and 53 teraflops throughputs (corresponding to 272 and 52 samples/second) for sequence lengths of 128 and 512, respectively, exhibiting up to 28% throughput improvements over NVIDIA BERT and up to 62% over HuggingFace BERT. We also support up to 1.8x larger batch size without running out of memory.
For more details on how we achieve the record breaking BERT training time please check out deep dive into DeepSpeed BERT Fastest BERT Training