Zero Redundancy Optimizer
If you have not done so already, we advise that you read the DeepSpeed tutorials on Getting Started and Megatron-LM GPT-2 before stepping through this tutorial.
In this tutorial, we will apply the ZeRO optimizer to the Megatron-LM GPT-2 model. ZeRO is a powerful set of memory optimization techniques that enable effective training of large models with trillions of parameters, such as GPT-2 and Turing-NLG 17B. Compared to the alternative model parallelism approaches for training large models, a key appeal of ZeRO is that no model code modifications are required. As this tutorial will demonstrate, using ZeRO in a DeepSpeed model is quick and easy because all you need is to change a few configurations in the DeepSpeed configuration JSON. No code changes are needed.
ZeRO Overview
ZeRO leverages the aggregate computation and memory resources of data parallelism to reduce the memory and compute requirements of each device (GPU) used for model training. ZeRO reduces the memory consumption of each GPU by partitioning the various model training states (weights, gradients, and optimizer states) across the available devices (GPUs and CPUs) in the distributed training hardware. Concretely, ZeRO is being implemented as incremental stages of optimizations, where optimizations in earlier stages are available in the later stages. To deep dive into ZeRO, please see our paper.
-
Stage 1: The optimizer states (e.g., for Adam optimizer, 32-bit weights, and the first, and second moment estimates) are partitioned across the processes, so that each process updates only its partition.
-
Stage 2: The reduced 16-bit gradients for updating the model weights are also partitioned such that each process retains only the gradients corresponding to its portion of the optimizer states.
-
Stage 3: The 16-bit model parameters are partitioned across the processes. ZeRO-3 will automatically collect and partition them during the forward and backward passes.
In addition, ZeRO-3 includes the infinity offload engine to form ZeRO-Infinity (paper), which can offload to both CPU and NVMe memory for huge memory savings.
Training environment
We use the DeepSpeed Megatron-LM GPT-2 code for this exercise. You can step through the Megatron-LM tutorial to familiarize yourself with the code. We will train the models in this tutorial on NVIDIA Tesla V100-SXM3 Tensor Core GPUs with 32GB RAM.
Enabling ZeRO Optimization
To enable ZeRO optimizations for a DeepSpeed model, we simply add the zero_optimization key to the DeepSpeed JSON configuration. A full description of configuration knobs of the zero_optimization key is available here.
Training a 1.5B Parameter GPT-2 model
We demonstrate the benefits of ZeRO stage 1 by showing that it enables data parallel training of a 1.5 billion parameter GPT-2 model on eight V100 GPUs. We configure training to use a batch size of 1 per device to ensure that the memory consumption is primarily due to model parameters and optimizer states. We create this training scenario by applying the following modifications to the deepspeed launch script:
--model-parallel-size 1 \
--num-layers 48 \
--hidden-size 1600 \
--num-attention-heads 16 \
--batch-size 1 \
--deepspeed_config ds_zero_stage_1.config \
Training this model without ZeRO fails with an out-of-memory (OOM) error as shown below:

A key reason why this model does not fit in GPU memory is that the Adam optimizer states for the model consume 18GB; a significant portion of the 32GB RAM. By using ZeRO stage 1 to partition the optimizer state among eight data parallel ranks, the per-device memory consumption can be reduced to 2.25GB, thus making the model trainable. To enable ZeRO stage 1, we simply update the DeepSpeed JSON config file as below:
{
"zero_optimization": {
"stage": 1,
"reduce_bucket_size": 5e8
}
}
As seen above, we set two fields in the zero_optimization key. Specifically we set the stage field to 1, and the optional reduce_bucket_size for gradient reduction to 500M. With ZeRO stage 1 enabled, the model can now train smoothly on 8 GPUs without running out of memory. Below we provide some screenshots of the model training:

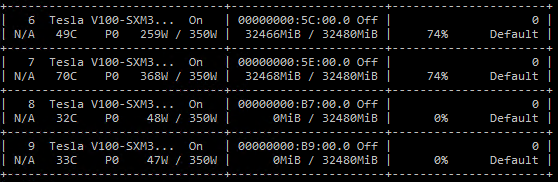
From the nvidia-smi screenshot above we can see that only GPUs 6-7 are being used for training the model. With ZeRO stage 1 we can further reduce the per-device memory consumption by increasing the data parallelism degree. These memory savings can be leveraged to either increase model size and/or batch size. In contrast, such benefits are not possible with data parallelism alone.
Training a 10B Parameter GPT-2 model
ZeRO stage 2 optimizations further increases the size of models that can be trained using data parallelism. We show this by training a model with 10B parameters using 32 V100 GPUs.
First, we need to configure a 10B parameter model with activation checkpointing enabled. This can be done by applying the following GPT-2 model configuration changes to the DeepSpeed launch script.
--model-parallel-size 1 \
--num-layers 50 \
--hidden-size 4096 \
--num-attention-heads 32 \
--batch-size 1 \
--deepspeed_config ds_zero_stage_2.config \
--checkpoint-activations
Next, we need to update the DeepSpeed JSON configuration, as shown below, to enable ZeRO stage 2 optimizations:
{
"zero_optimization": {
"stage": 2,
"contiguous_gradients": true,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"allgather_bucket_size": 5e8
}
}
In the above changes, we have set the stage field to 2, and configured other optimization knobs that are available in ZeRO stage 2. For example, we have enabled contiguous_gradients to reduce memory fragmentation during backward pass. A full description of these optimization knobs is available here. With these changes, we can now launch the training run.
Here is a screenshot of the training log:

Here is a screenshot of nvidia-smi showing GPU activity during training:
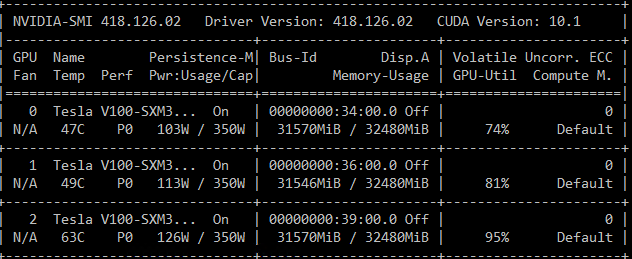
Training trillion-scale models with ZeRO-Infinity
ZeRO-3, the third stage of ZeRO, partitions the full model state (i.e., weights, gradients, and optimizer states) to scale memory savings linearly with the degree of data parallelism. ZeRO-3 can be enabled in the JSON configuration. A full description of these configurations is available here.
Offloading to CPU and NVMe with ZeRO-Infinity
ZeRO-Infinity uses DeepSpeed’s infinity offload engine to offload the full model state to CPU or NVMe memory, allowing for even larger model sizes. Offloading can be enabled inside the DeepSpeed configuration:
{
"zero_optimization": {
"stage": 3,
"contiguous_gradients": true,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_prefetch_bucket_size": 1e7,
"stage3_param_persistence_threshold": 1e5,
"reduce_bucket_size": 1e7,
"sub_group_size": 1e9,
"offload_optimizer": {
"device": "cpu"
},
"offload_param": {
"device": "cpu"
}
}
}
ZeRO-Infinity vs ZeRO-Offload: DeepSpeed first included offloading capabilities with ZeRO-Offload, a system for offloading optimizer and gradient states to CPU memory within ZeRO-2. ZeRO-Infinity is the next generation of offloading capabilities accessible to ZeRO-3. ZeRO-Infinity is able to offload more data than ZeRO-Offload and has more effective bandwidth utilization and overlapping of computation and communication.
Allocating Massive Megatron-LM Models
We make two further changes to model initialization in order to support models that exceed local system memory, but not total system memory.
-
Allocate the model in a memory-scalable fashion. The model parameters will be allocated and immediately partitioned across the data parallel group. If
remote_deviceis"cpu"or"nvme", the model will also be allocated in CPU/NVMe memory instead of GPU memory. Please see the full ZeRO-3 Init docs for more details.with deepspeed.zero.Init(data_parallel_group=mpu.get_data_parallel_group(), remote_device=get_args().remote_device, enabled=get_args().zero_stage==3): model = GPT2Model(num_tokentypes=0, parallel_output=True) -
Gather the embeddings weight for initialization. DeepSpeed will automatically gather a module’s parameters during its constructor and for its forward and backward pass. However, additional accesses must coordinate with DeepSpeed to ensure that parameter data is gathered and subsequently partitioned. If the tensor is modified, the
modifier_rankargument should also be used to ensure all ranks have a consistent view of the data. Please see the full GatheredParameters docs for more details.self.position_embeddings = torch.nn.Embedding(...) with deepspeed.zero.GatheredParameters(self.position_embeddings.weight, modifier_rank=0): # Initialize the position embeddings. self.init_method(self.position_embeddings.weight) ... self.tokentype_embeddings = torch.nn.Embedding(...) with deepspeed.zero.GatheredParameters(self.tokentype_embeddings.weight, modifier_rank=0): # Initialize the token-type embeddings. self.init_method(self.tokentype_embeddings.weight)
Memory-centric tiling
ZeRO-Infinity includes a replacement for Linear layers that further reduces memory.
We optionally tile the model parallel linear layers found in each Transformer layer. Note
that model parallelism and tiling can be combined by specifying the corresponding
base class when building the layer.
The deepspeed.zero.TiledLinear module exploits the data fetch and release
pattern of ZeRO-3 to reduce the working memory requirements by breaking down
a large operator into smaller tiles that can be executed sequentially.
We include the changes for one example from Megatron-LM’s ParallelMLP. Three more
model-parallel layers in transformer.py proceed similarly.
The model parallel layers of Megatron-LM have a special form in which the
additive bias of the layer is delayed and instead returned from forward()
to be fused with a later operator. DeepSpeed’s
deepspeed.zero.TiledLinearReturnBias subclass of TiledLinear simply also
forwards the returned bias parameter without accumulating.
@@ -1,6 +1,9 @@
-self.dense_h_to_4h = mpu.ColumnParallelLinear(
+self.dense_h_to_4h = deepspeed.zero.TiledLinearReturnBias(
args.hidden_size,
4 * args.hidden_size,
+ in_splits=args.tile_factor,
+ out_splits=4*args.tile_factor,
+ linear_cls=mpu.ColumnParallelLinear,
gather_output=False,
init_method=init_method,
skip_bias_add=True)
Note that we scale in_splits and out_splits proportionally with input_size and output_size. This
results in tiles of fixed size [hidden/tile_factor, hidden/tile_factor].
Registering external parameters
Deprecated:
DeepSpeed version 0.3.15 introduced automatic external parameter
registration and this step is no longer needed.
Extracting weights
If you need to take the pretrained weights out of Deepspeed here is what you can do for getting fp16 weights:
- under ZeRO-2,
state_dictcontains the fp16 model weights and these can be saved normally withtorch.save. - under ZeRO-3,
state_dictcontains just the placeholders since the model weights are partitioned across multiple GPUs. If you want to get to these weights enable:
"zero_optimization": {
"stage3_gather_16bit_weights_on_model_save": true
},
And then save the model using:
if self.deepspeed:
self.deepspeed.save_16bit_model(output_dir, output_file)
Because it requires consolidation of the weights on one GPU it can be slow and memory demanding, so only use this feature when needed.
Note that if stage3_gather_16bit_weights_on_model_save is False, no weights will be saved (again, because state_dict doesn’t have them).
You can use this method to save ZeRO-2 weights as well.
If you’d like to get the fp32 weights, we supply a special script that can do offline consolidation. It requires no configuration files or GPUs. Here is an example of its usage:
$ cd /path/to/checkpoint_dir
$ ./zero_to_fp32.py . pytorch_model.bin
Processing zero checkpoint at global_step1
Detected checkpoint of type zero stage 3, world_size: 2
Saving fp32 state dict to pytorch_model.bin (total_numel=60506624)
The zero_to_fp32.py script gets created automatically when you save a checkpoint.
Note: currently this script uses 2x memory (general RAM) of the size of the final checkpoint.
Alternatively, if you have plenty of spare CPU memory and instead of getting the file you want your model to be updated to its fp32 weights, you can do the following at the end of the training:
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
fp32_model = load_state_dict_from_zero_checkpoint(deepspeed.module, checkpoint_dir)
Beware, that the model will be good for saving, but no longer good for continuing the training and will require a deepspeed.initialize() anew.
If you just want the state_dict, you can do:
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir)
Congratulations! You have completed the ZeRO tutorial.