Automatic Tensor Parallelism for HuggingFace Models
Note: This tutorial covers AutoTP for inference. For training with tensor parallelism and ZeRO optimization, see Automatic Tensor Parallelism (Training).
Contents
Introduction
This tutorial demonstrates the new automatic tensor parallelism feature for inference. Previously, the user needed to provide an injection policy to DeepSpeed to enable tensor parallelism. DeepSpeed now supports automatic tensor parallelism for HuggingFace models by default as long as kernel injection is not enabled and an injection policy is not provided. This allows our users to improve performance of models that are not currently supported via kernel injection, without providing the injection policy. Below is an example of the new method:
# ---------------------------------------
# New automatic tensor parallelism method
# ---------------------------------------
import os
import torch
import transformers
import deepspeed
local_rank = int(os.getenv("LOCAL_RANK", "0"))
world_size = int(os.getenv("WORLD_SIZE", "1"))
# create the model pipeline
pipe = transformers.pipeline(task="text2text-generation", model="google/t5-v1_1-small", device=local_rank)
# Initialize the DeepSpeed-Inference engine
pipe.model = deepspeed.init_inference(
pipe.model,
mp_size=world_size,
dtype=torch.float
)
output = pipe('Input String')
Previously, to run inference with only tensor parallelism for the models that don’t have kernel injection support, you could pass an injection policy that showed the two specific linear layers on a Transformer Encoder/Decoder layer: 1) the attention output GeMM and 2) layer output GeMM. We needed these parts of the layer to add the required all-reduce communication between GPUs to merge the partial results across model-parallel ranks. Below, we show an example of this previous method:
# ----------------------------------
# Previous tensor parallelism method
# ----------------------------------
import os
import torch
import transformers
import deepspeed
from transformers.models.t5.modeling_t5 import T5Block
local_rank = int(os.getenv("LOCAL_RANK", "0"))
world_size = int(os.getenv("WORLD_SIZE", "1"))
# create the model pipeline
pipe = transformers.pipeline(task="text2text-generation", model="google/t5-v1_1-small", device=local_rank)
# Initialize the DeepSpeed-Inference engine
pipe.model = deepspeed.init_inference(
pipe.model,
mp_size=world_size,
dtype=torch.float,
injection_policy={T5Block: ('SelfAttention.o', 'EncDecAttention.o', 'DenseReluDense.wo')}
)
output = pipe('Input String')
With automatic tensor parallelism, we do not need to provide the injection policy for supported models. The injection policy will be determined at runtime and applied automatically.
Example Script
We can observe performance improvement with automatic tensor parallelism using the inference test suite. This script is for testing text-generation models and includes per token latency, bandwidth, throughput and memory checks for comparison. See the README for more information.
Launching
Use the following command to run without DeepSpeed and without tensor parallelism. Set the test_performance flag to collect performance data:
deepspeed --num_gpus <num_gpus> DeepSpeedExamples/inference/huggingface/text-generation/inference-test.py --name <model> --batch_size <batch_size> --test_performance
To enable tensor parallelism, you need to use the flag ds_inference for the compatible models:
deepspeed --num_gpus <num_gpus> DeepSpeedExamples/inference/huggingface/text-generation/inference-test.py --name <model> --batch_size <batch_size> --test_performance --ds_inference
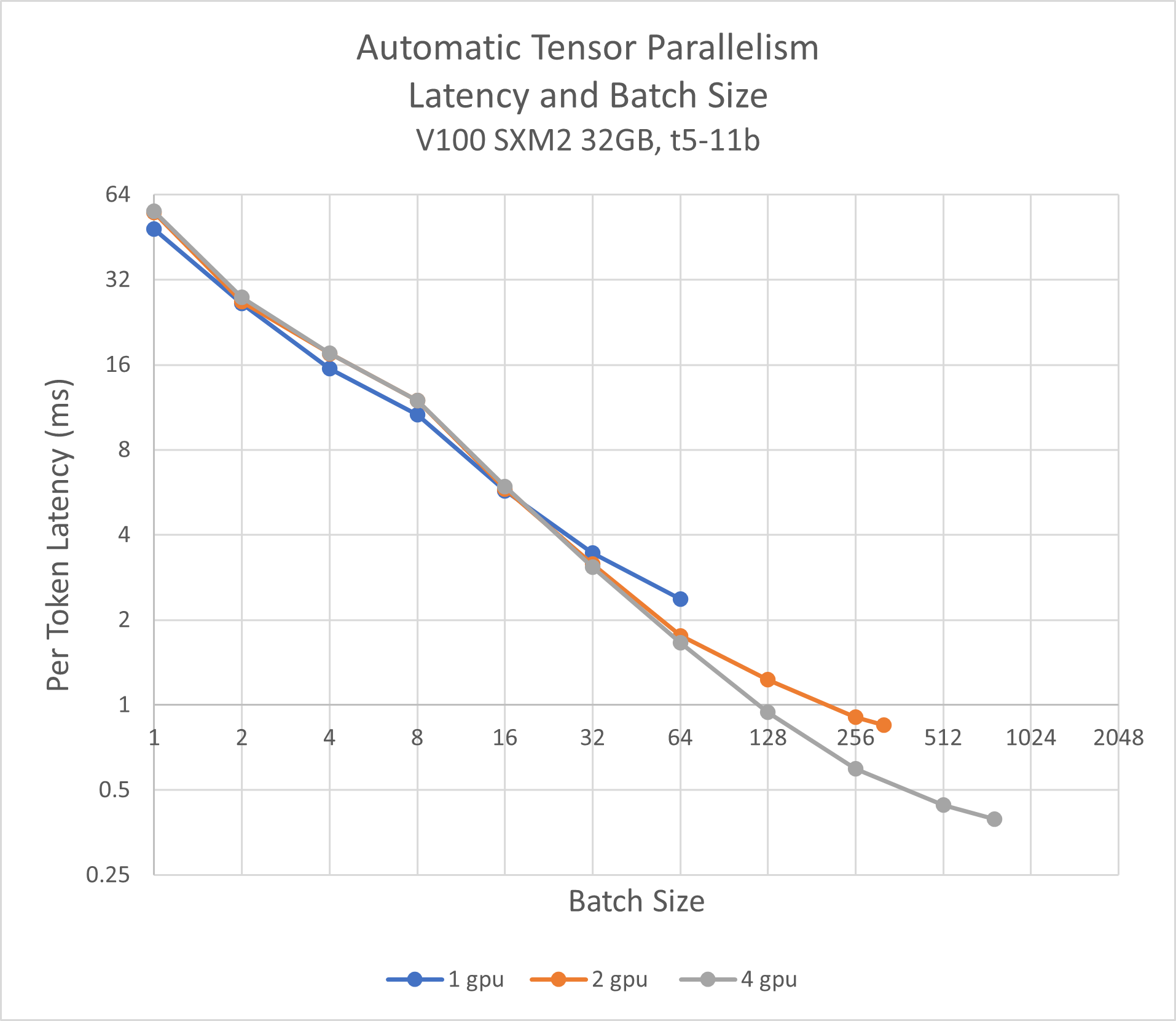
T5 11B Inference Performance Comparison
The following results were collected using V100 SXM2 32GB GPUs.
Latency
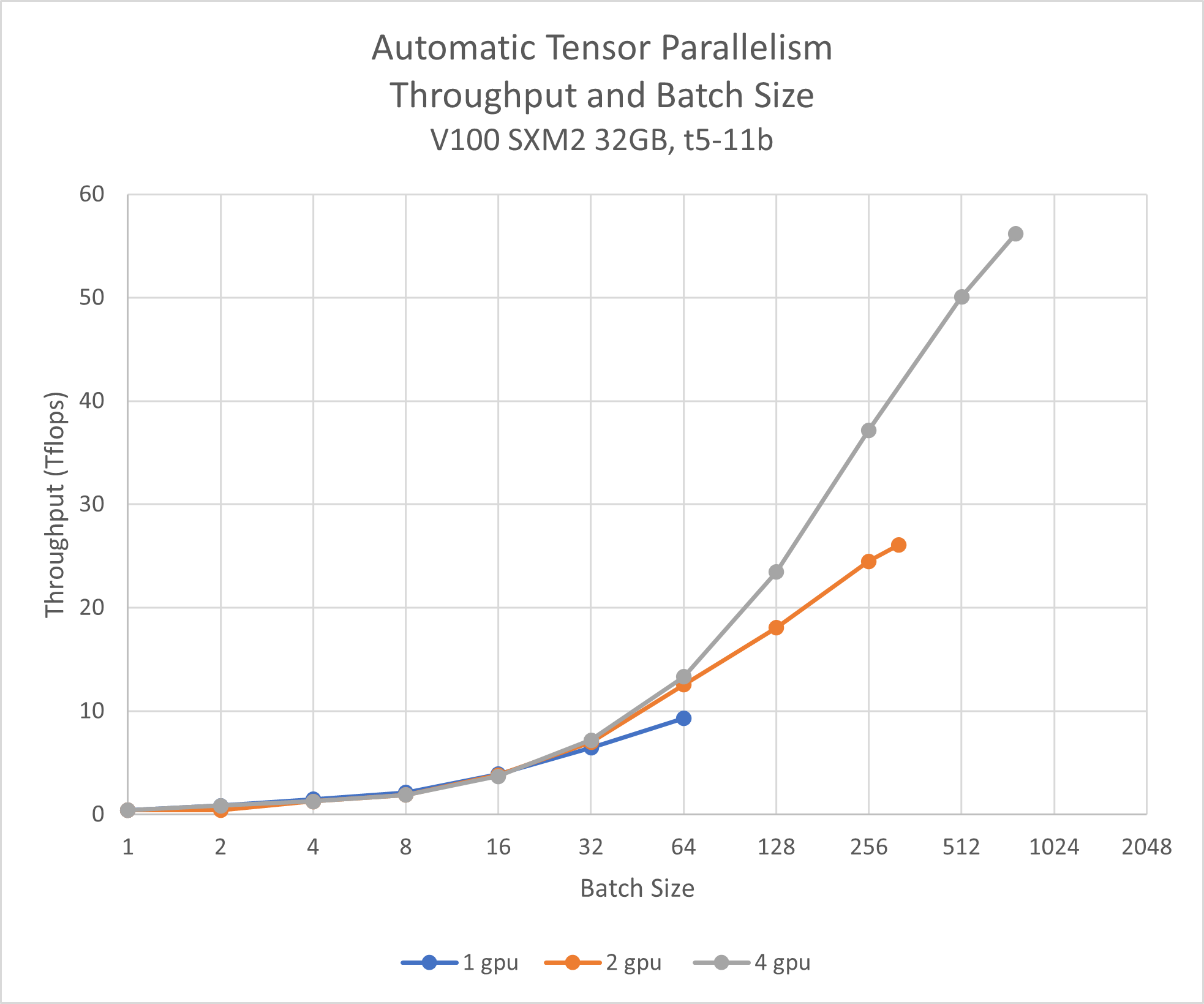
Throughput
Memory
| Test | Memory Allocated per GPU | Max Batch Size | Max Throughput per GPU |
|---|---|---|---|
| No TP or 1 GPU | 21.06 GB | 64 | 9.29 TFLOPS |
| 2 GPU TP | 10.56 GB | 320 | 13.04 TFLOPS |
| 4 GPU TP | 5.31 GB | 768 | 14.04 TFLOPS |
OPT 13B Inference Performance Comparison
The following results were collected using V100 SXM2 32GB GPUs.
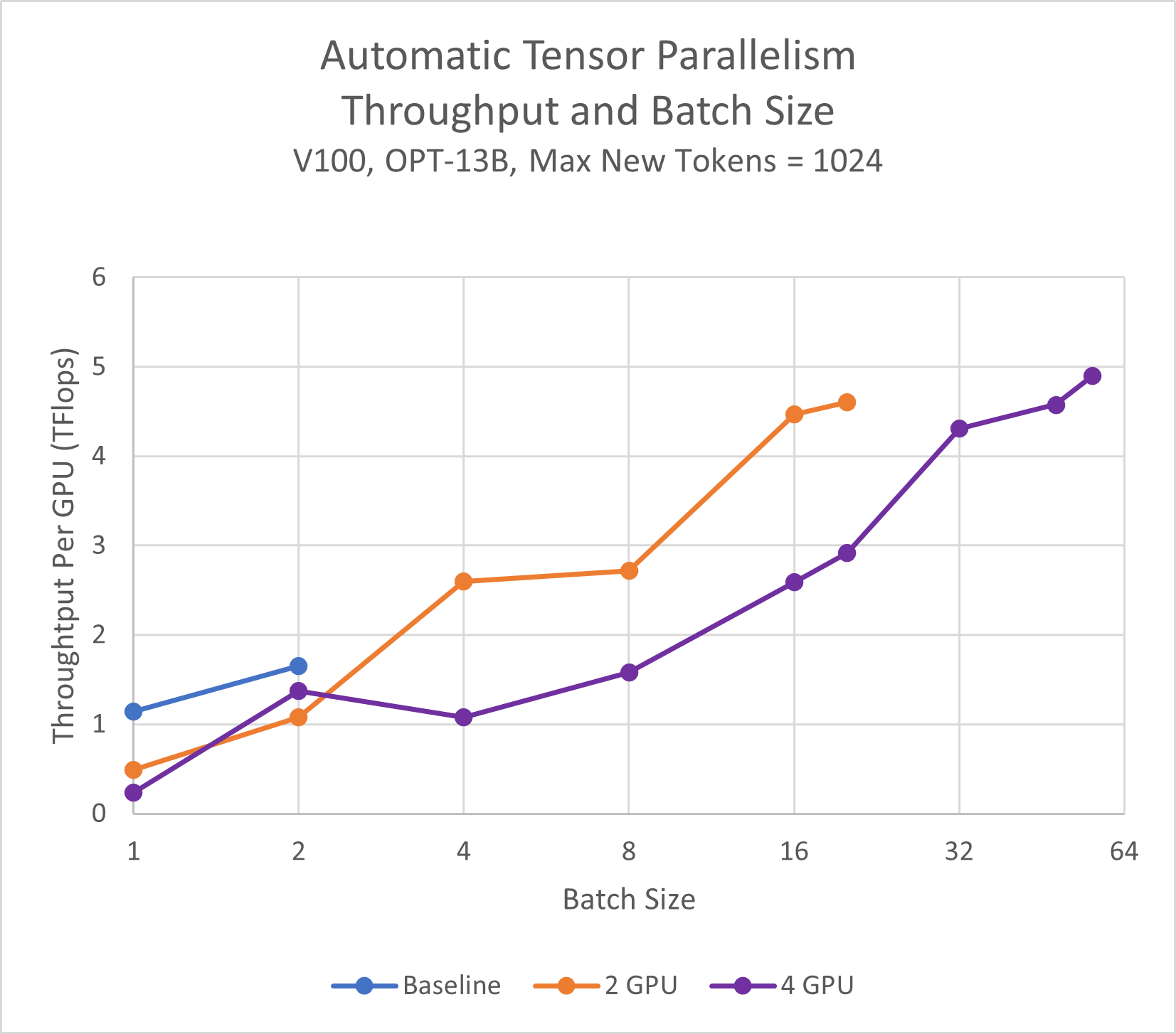
| Test | Memory Allocated per GPU | Max Batch Size | Max Throughput per GPU |
|---|---|---|---|
| No TP | 23.94 GB | 2 | 1.65 TFlops |
| 2 GPU TP | 12.23 GB | 20 | 4.61 TFlops |
| 4 GPU TP | 6.36 GB | 56 | 4.90 TFlops |
Supported Models
The following model families have been successfully tested with automatic tensor parallelism. Other models may work but have not been tested yet.
- albert
- arctic
- baichuan
- bert
- bigbird_pegasus
- bloom
- camembert
- chatglm2
- chatglm3
- codegen
- codellama
- deberta_v2
- electra
- ernie
- esm
- falcon
- glm
- gpt-j
- gpt-neo
- gpt-neox
- longt5
- luke
- llama
- llama2
- m2m_100
- marian
- mistral
- mixtral
- mpt
- mvp
- nezha
- openai
- opt
- pegasus
- perceiver
- phi
- plbart
- qwen
- qwen2
- qwen2-moe
- qwen2.5
- qwen3
- reformer
- roberta
- roformer
- splinter
- starcode
- t5
- xglm
- xlm_roberta
- yoso
- yuan
Unsupported Models
The following models are not currently supported with automatic tensor parallelism. They may still be compatible with other DeepSpeed features (e.g., kernel injection for Bloom):
- deberta
- flaubert
- fsmt
- gpt2
- led
- longformer
- xlm
- xlnet