Megatron-LM GPT2
If you haven’t already, we advise you to first read through the Getting Started guide before stepping through this tutorial.
In this tutorial we will be adding DeepSpeed to Megatron-LM GPT2 model, which is a large, powerful transformer. Megatron-LM supports model-parallel and multi-node training. Please see the corresponding paper for more details: Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.
First, we discuss data and environment setup and how to train the GPT-2 model with the original Megatron-LM. Next, we proceed step-by-step in enabling this model to run with DeepSpeed. Finally, we demonstrate the performance gains, and memory footprint reduction from using DeepSpeed.
Training GPT-2 with the Original Megatron-LM
We’ve copied the original model code from Megatron-LM into DeepSpeed Megatron-LM and made it available as a submodule. To download, execute:
git submodule update --init --recursive
Training Data Setup
- Follow Megatron’s instructions
to download the
webtextdata and place a symbolic link underDeepSpeedExamples/Megatron-LM/data:
Running Unmodified Megatron-LM GPT2 model
- For a single GPU run:
- change
examples/pretrain_gpt.sh, set its--train-dataargument as"webtext". - run
bash examples/pretrain_gpt.sh
- change
- For multiple GPUs and/or nodes run:
- change
examples/pretrain_gpt_distributed_with_mp.sh- set its
--train-dataargument as"webtext" GPUS_PER_NODEindicates how many GPUs per node involved in the testingNNODESindicates how many nodes involved in the testing
- set its
- run
bash examples/pretrain_gpt_distributed_with_mp.sh
- change
Enabling DeepSpeed
To use DeepSpeed we will modify three files :
megatron/arguments.py: Arguments configurationspretrain_gpt.py: Main entry point for trainingmegatron/utils.py: Checkpoint saving and loading utilities
Argument Parsing
The first step is adding DeepSpeed arguments to
Megatron-LM GPT2 model, using deepspeed.add_config_arguments() in
megatron/arguments.py.
def get_args():
"""Parse all the args."""
parser = argparse.ArgumentParser(description='PyTorch BERT Model')
parser = add_model_config_args(parser)
parser = add_fp16_config_args(parser)
parser = add_training_args(parser)
parser = add_evaluation_args(parser)
parser = add_text_generate_args(parser)
parser = add_data_args(parser)
# Include DeepSpeed configuration arguments
parser = deepspeed.add_config_arguments(parser)
Initialization and Training
We will modify pretrain.py to enable training with DeepSpeed.
Initialization
We use deepspeed.initialize to create model_engine, optimizer and LR
scheduler. Below is its definition:
def initialize(args,
model,
optimizer=None,
model_parameters=None,
training_data=None,
lr_scheduler=None,
mpu=None,
dist_init_required=True,
collate_fn=None):
For the Megatron-LM GPT2 model, we initialize DeepSpeed in its
setup_model_and_optimizer() function as below, to pass the raw model,
optimizer, args, lr_scheduler and mpu.
def setup_model_and_optimizer(args):
"""Setup model and optimizer."""
model = get_model(args)
optimizer = get_optimizer(model, args)
lr_scheduler = get_learning_rate_scheduler(optimizer, args)
if args.deepspeed:
import deepspeed
print_rank_0("DeepSpeed is enabled.")
model, optimizer, _, lr_scheduler = deepspeed.initialize(
model=model,
optimizer=optimizer,
args=args,
lr_scheduler=lr_scheduler,
mpu=mpu,
dist_init_required=False
)
Note that when FP16 is enabled, Megatron-LM GPT2 adds a wrapper to the Adam
optimizer. DeepSpeed has its own FP16 Optimizer, so we need to pass the Adam
optimizer to DeepSpeed directly without any wrapper. We return the unwrapped
Adam optimizer from get_optimizer() when DeepSpeed is enabled.
def get_optimizer(model, args):
"""Setup the optimizer."""
......
# Use Adam.
optimizer = Adam(param_groups,
lr=args.lr, weight_decay=args.weight_decay)
if args.deepspeed:
# fp16 wrapper is not required for DeepSpeed.
return optimizer
Using the Training API
The model returned by deepspeed.initialize is the DeepSpeed Model Engine
that we will use to train the model using the forward, backward and step API.
Forward Propagation
The forward propagation API is compatible to PyTorch and no change is required.
Backward Propagation
Backward propagation is done by calling backward(loss) directly on the model engine.
def backward_step(optimizer, model, lm_loss, args, timers):
"""Backward step."""
# Total loss.
loss = lm_loss
# Backward pass.
if args.deepspeed:
model.backward(loss)
else:
optimizer.zero_grad()
if args.fp16:
optimizer.backward(loss, update_master_grads=False)
else:
loss.backward()
Zeroing the gradients is handled automatically by DeepSpeed after the weights have been updated using a mini-batch.
Furthermore, DeepSpeed addresses distributed data parallel and FP16 under the hood, simplifying code in multiple places.
(A) DeepSpeed also performs gradient averaging automatically at the gradient accumulation boundaries. So we skip the allreduce communication.
if args.deepspeed:
# DeepSpeed backward propagation already addressed all reduce communication.
# Reset the timer to avoid breaking timer logs below.
timers('allreduce').reset()
else:
torch.distributed.all_reduce(reduced_losses.data)
reduced_losses.data = reduced_losses.data / args.world_size
if not USE_TORCH_DDP:
timers('allreduce').start()
model.allreduce_params(reduce_after=False,
fp32_allreduce=args.fp32_allreduce)
timers('allreduce').stop()
(B) We also skip updating master gradients, since DeepSpeed addresses it internally.
# Update master gradients.
if not args.deepspeed:
if args.fp16:
optimizer.update_master_grads()
# Clipping gradients helps prevent the exploding gradient.
if args.clip_grad > 0:
if not args.fp16:
mpu.clip_grad_norm(model.parameters(), args.clip_grad)
else:
optimizer.clip_master_grads(args.clip_grad)
return lm_loss_reduced
Updating the Model Parameters
The step() function in DeepSpeed engine updates the model parameters as well
as the learning rate.
if args.deepspeed:
model.step()
else:
optimizer.step()
# Update learning rate.
if not (args.fp16 and optimizer.overflow):
lr_scheduler.step()
else:
skipped_iter = 1
Loss Scaling
The GPT2 training script logs the loss scaling value during training. Inside
the DeepSpeed optimizer, this value is stored as cur_scale instead of
loss_scale as in Megatron’s optimizer. Therefore, we appropriately replace it in
the logging string.
if args.fp16:
log_string += ' loss scale {:.1f} |'.format(
optimizer.cur_scale if args.deepspeed else optimizer.loss_scale)
Checkpoint Saving & Loading
The DeepSpeed engine has flexible APIs for checkpoint saving and loading, to handle the states from both the client model and its own internal.
def save_checkpoint(self, save_dir, tag, client_state={})
def load_checkpoint(self, load_dir, tag)
To use DeepSpeed, we need to update utils.py in which Megatron-LM GPT2 saves and
loads checkpoints.
Create a new function save_ds_checkpoint() as shown below. The new function
collects the client model states and passes them to the DeepSpeed engine by calling
DeepSpeed’s save_checkpoint().
def save_ds_checkpoint(iteration, model, args):
"""Save a model checkpoint."""
sd = {}
sd['iteration'] = iteration
# rng states.
if not args.no_save_rng:
sd['random_rng_state'] = random.getstate()
sd['np_rng_state'] = np.random.get_state()
sd['torch_rng_state'] = torch.get_rng_state()
sd['cuda_rng_state'] = get_accelerator().get_rng_state()
sd['rng_tracker_states'] = mpu.get_cuda_rng_tracker().get_states()
model.save_checkpoint(args.save, iteration, client_state = sd)
In Megatron-LM GPT2’s save_checkpoint() function, add the following lines to
invoke the above function for DeepSpeed.
def save_checkpoint(iteration, model, optimizer,
lr_scheduler, args):
"""Save a model checkpoint."""
if args.deepspeed:
save_ds_checkpoint(iteration, model, args)
else:
......
In the load_checkpoint() function, use DeepSpeed checkpoint loading API as below,
and return the states for the client model.
def load_checkpoint(model, optimizer, lr_scheduler, args):
"""Load a model checkpoint."""
iteration, release = get_checkpoint_iteration(args)
if args.deepspeed:
checkpoint_name, sd = model.load_checkpoint(args.load, iteration)
if checkpoint_name is None:
if mpu.get_data_parallel_rank() == 0:
print("Unable to load checkpoint.")
return iteration
else:
......
DeepSpeed Activation Checkpoints (Optional)
DeepSpeed can reduce the activation memory during model parallel training by partitioning activation checkpoints across model parallel GPUs, or offloading them to CPU. These optimizations are optional, and can be skipped unless activation memory becomes a bottleneck. To enable partition activation, we use the deepspeed.checkpointing API to replace Megatron’s activation checkpointing and random state tracker APIs. The replacement should happen before the first invocation of these APIs.
a) Replace in pretrain_gpt.py :
# Optional DeepSpeed Activation Checkpointing Features
#
if args.deepspeed and args.deepspeed_activation_checkpointing:
set_deepspeed_activation_checkpointing(args)
def set_deepspeed_activation_checkpointing(args):
deepspeed.checkpointing.configure(mpu,
deepspeed_config=args.deepspeed_config,
partition_activation=True)
mpu.checkpoint = deepspeed.checkpointing.checkpoint
mpu.get_cuda_rng_tracker = deepspeed.checkpointing.get_cuda_rng_tracker
mpu.model_parallel_cuda_manual_seed =
deepspeed.checkpointing.model_parallel_cuda_manual_seed
b) Replace in mpu/transformer.py:
if deepspeed.checkpointing.is_configured():
global get_cuda_rng_tracker, checkpoint
get_cuda_rng_tracker = deepspeed.checkpoint.get_cuda_rng_tracker
checkpoint = deepspeed.checkpointing.checkpoint
With these replacements, various DeepSpeed activation checkpointing optimizations such as activation partitioning, contiguous checkpointing, and CPU checkpointing, can be specified either with deepspeed.checkpointing.configure or in the deepspeed_config file.
Train scripts
We assume that the webtext data was prepared in the previous step. To start training
Megatron-LM GPT2 model with DeepSpeed applied, execute the following command to
start training.
- Single GPU run
- run
bash scripts/ds_pretrain_gpt.sh
- run
- Multiple GPUs/Nodes run
- run
bash scripts/ds_zero2_pretrain_gpt_model_parallel.sh
- run
DeepSpeed Evaluation using GPT-2
DeepSpeed enables training very large models effectively via the advanced ZeRO optimizer. In February 2020, we released a sub-set of optimizations from ZeRO in DeepSpeed that perform optimizer state partitioning. We refer to them as ZeRO-1. In May 2020, we extended ZeRO-1 in DeepSpeed to include additional optimizations from ZeRO including gradient and activation partitioning, as well as contiguous memory optimizations. We refer to this release as ZeRO-2.
ZeRO-2 significantly reduces the memory footprint for training large models which means large models can be trained with i) less model parallelism and ii) larger batch sizes. A lower model parallelism degree improves training efficiency by increasing the granularity of computations such as matrix multiplications where performance is directly related to the size of the matrices. Furthermore, less model parallelism also results in less communication between model parallel GPUs, which further boosts performance. Larger batch size has a similar effect of increasing the computational granularity as well as reducing communication, also resulting in better performance. Therefore, with DeepSpeed and ZeRO-2 integration into Megatron, we elevate the model scale and speed to an entirely new level compared to Megatron alone.
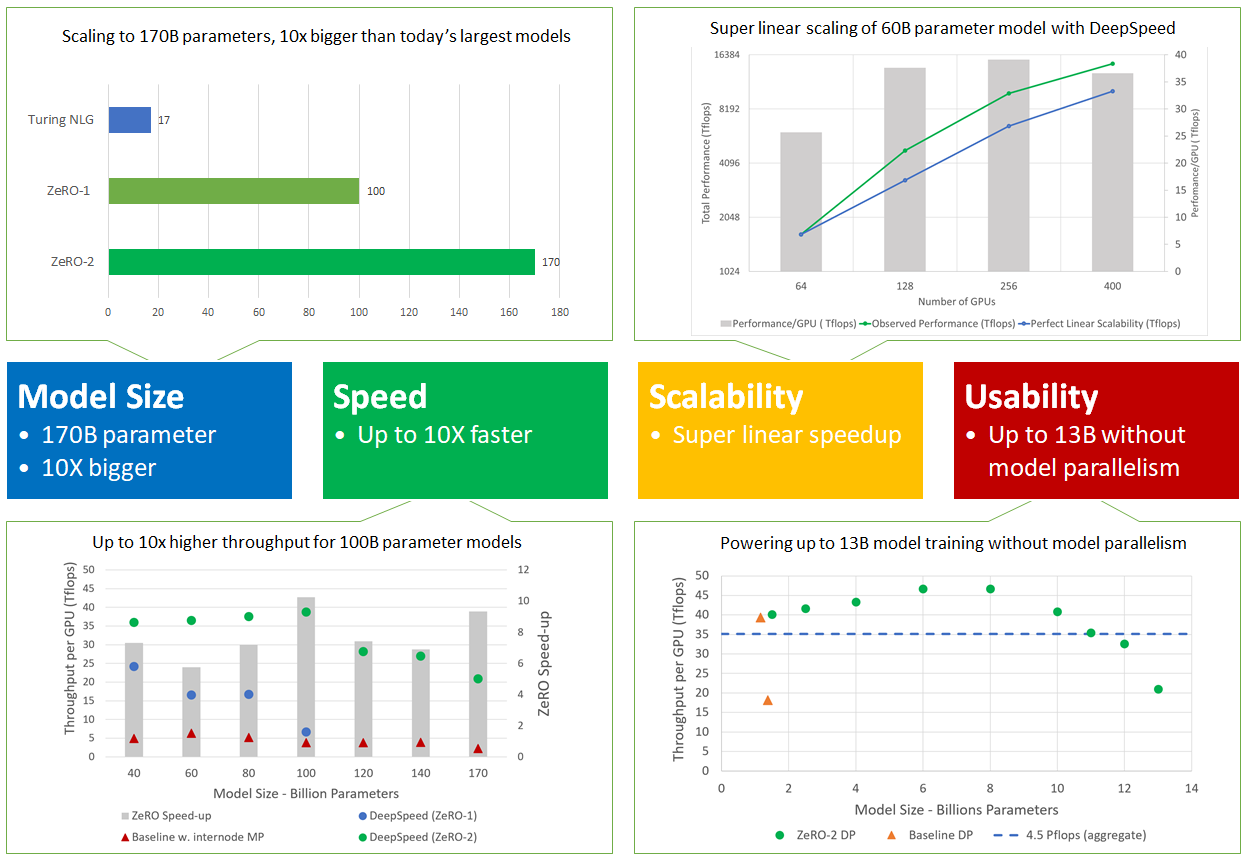
Figure 2: ZeRO-2 scales to 170 billion parameters, has up to 10x higher throughput, obtains super linear speedup, and improves usability by avoiding the need for code refactoring for models up to 13 billion parameters.
More concretely, DeepSpeed and ZeRO-2 excel in four aspects (as visualized in Figure 2), supporting an order-of-magnitude bigger models, up to 10x faster, with superlinear scalability, and improved usability to democratize large model training. These four aspects are detailed below.
Model size: State-of-the-art large models such as OpenAI GPT-2, NVIDIA Megatron-LM, Google T5, and Microsoft Turing-NLG have sizes of 1.5B, 8.3B, 11B, and 17B parameters respectively. ZeRO-2 provides system support to efficiently run models of 170 billion parameters, an order-of-magnitude bigger than these largest models (Figure 2, top left).
Speed: Improved memory efficiency powers higher throughput and faster training. Figure 2 (bottom left) shows system throughput of ZeRO-2 and ZeRO-1 (both combining ZeRO-powered data parallelism with NVIDIA Megatron-LM model parallelism) as well as using the state-of-the-art model parallelism approach Megatron-LM alone (baseline in Figure 2, bottom left). ZeRO-2 runs 100-billion-parameter models on a 400 NVIDIA V100 GPU cluster with over 38 teraflops per GPU and aggregated performance over 15 petaflops. For models of the same size, ZeRO-2 is 10x faster in training speed when compared with using Megatron-LM alone and 5x faster when compared with ZeRO-1.
Scalability: We observe superlinear speedup (Figure 2, top right), where the performance more than doubles when the number of GPUs are doubled. ZeRO-2 reduces the memory footprint of the model states as we increase the data parallelism degree, allowing us to fit larger batch sizes per GPU and resulting in better performance.
Democratizing large model training: ZeRO-2 empowers model scientists to train models up to 13 billion parameters efficiently without any model parallelism that typically requires model refactoring (Figure 2, bottom right). 13 billion parameters is larger than most of the largest state-of-the-art models (such as Google T5, with 11 billion parameters). Model scientists can therefore experiment freely with large models without worrying about model parallelism. In comparison, the implementations of classic data-parallelism approaches (such as PyTorch Distributed Data Parallel) run out of memory with 1.4-billion-parameter models, while ZeRO-1 supports up to 6 billion parameters for comparison.
Furthermore, in the absence of model parallelism, these models can be trained on low bandwidth clusters while still achieving significantly better throughput compared to using model parallelism. For example, the GPT-2 model can be trained nearly 4x faster with ZeRO powered data parallelism compared to using model parallelism on a four node cluster connected with 40 Gbps Infiniband interconnect, where each node has four NVIDIA 16GB V100 GPUs connected with PCI-E. Therefore, with this performance improvement, large model training is no longer limited to GPU clusters with ultra fast interconnect, but also accessible on modest clusters with limited bandwidth.