DeepSpeed4Science Overview and Tutorial
In line with Microsoft’s mission to solve humanity’s most pressing challenges, the DeepSpeed team at Microsoft is responding to this opportunity by launching a new initiative called DeepSpeed4Science, aiming to build unique capabilities through AI system technology innovations to help domain experts to unlock today’s biggest science mysteries. This page serves as an overview page for all technologies released (or to be released in the future) as part of the DeepSpeed4Science initiative, making it easier for scientists to shop for techniques they need. Details of the DeepSpeed4Science initiative can be found at our website. For each technique we will introduce what is it for, when to use it, links to how to use it, and existing scientific applications of the techniques (we welcome users to contribute more showcases if you apply our techniques in your scientific research).
To cite DeepSpeed4Science, please cite our white paper:
@article{song2023deepspeed4science,
title={DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies},
author={Song, Shuaiwen Leon and Kruft, Bonnie and Zhang, Minjia and Li, Conglong and Chen, Shiyang and Zhang, Chengming and Tanaka, Masahiro and Wu, Xiaoxia and Rasley, Jeff and Awan, Ammar Ahmad and others},
journal={arXiv preprint arXiv:2310.04610},
year={2023}
}
- [2023/09] We are releasing two techniques: DeepSpeed4Science large-scale training framework, DS4Sci_EvoformerAttention and their scientific applications in structural biology research.
New Megatron-DeepSpeed for Large-Scale AI4Science Model Training
We are proud to introduce new Megatron-DeepSpeed, which is an updated framework for large-scale model training. We rebased and enabled DeepSpeed with the newest Megatron-LM for long sequence support and many other capabilities. With the new Megatron-DeepSpeed, users can now train their large AI4Science models like GenSLMs with much longer sequences via a synergetic combination of ZeRO-style data parallelism, tensor parallelism, sequence parallelism, pipeline parallelism, model state offloading, and several newly added memory optimization techniques such as attention mask offloading and position embedding partitioning.
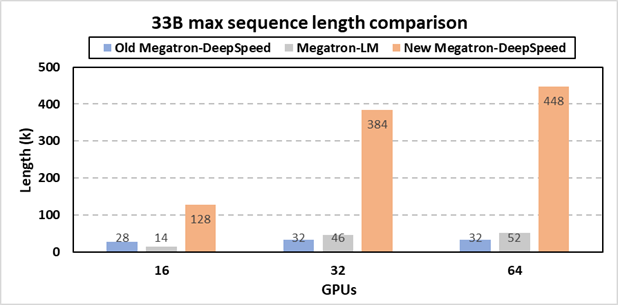
The figure depicts system capability in terms of enabling long sequence lengths for training a 33B parameter GPT-like model using our new Megatron-DeepSpeed framework. The results show that the new Megatron-DeepSpeed enables 9x longer sequence lengths than NVIDIA's Megatron-LM without triggering out-of-memory error.
To see how the new Megatron-DeepSpeed helps enabling new system capabilities, such as training models with massive sequences length, please read our tutorial.
Meanwhile, our new Megatron-DeepSpeed has been applied to genome-scale foundation model GenSLMs, which is a 2022 ACM Gordon Bell award winning genome-scale language model from Argonne National Lab. To achieve their scientific goal, GenSLMs and similar models require very long sequence support for both training and inference that is beyond generic LLM’s long-sequence strategies. By leveraging DeepSpeed4Science’s new Megatron-DeepSpeed, GenSLMs team is able to train their 25B model with 512K sequence length, much longer than their original 42K sequence length. Detailed information about the methodology can be found at our website. GenSLMs team also hosts an example about how to use DeepSpeed4Science in the GenSLMs repo.
Memory-Efficient EvoformerAttention Kernels
Evoformer is a key building block for scientific models such as DeepMind’s AlphaFold. However, EvoFormer’s multiple sequence alignment (MSA) attention frequently runs into memory explosion problems during training/inference, such as in protein structure prediction models. Existing techniques such as FlashAttention cannot effectively support Evoformer because EvoFormerAttention uses row-wise/column-wise/triangle attention, which are different from standard Transformer self-attention and cross-attention that require custom optimizations. To mitigate the memory explosion problem, we introduce DS4Sci_EvoformerAttention kernels, a collection of kernels that improve the memory efficiency of variants of EvoFormer. DS4Sci_EvoformerAttention is easy-to-use. To see how you can use it, please refer to our tutorial.
DS4Sci_EvoformerAttention has already been applied to OpenFold, which is a community reproduction of DeepMind’s AlphaFold2 that makes it possible to train or finetune AlphaFold2 on new datasets. With DS4Sci_EvoformerAttention kernels, OpenFold team is able to reduce the peak memory requirement by 13x without accuracy loss. Detailed information about the methodology can be found at our website.

The figure shows that DeepSpeed's EvoFormerAttention kernels help reduce OpenFold’s peak memory requirement for training by 13X.