DeepSpeed Sparse Attention
In this tutorial we describe how to use DeepSpeed Sparse Attention (SA) and its building-block kernels. The easiest way to use SA is through DeepSpeed launcher. We will describe this through an example in How to use sparse attention with DeepSpeed launcher section. But before that, we introduce modules provided by DeepSpeed SA in the next section.
Note: Currently, DeepSpeed Sparse Attention can be used only on NVIDIA V100 or A100 GPUs using Torch >= 1.6 and CUDA 10.1, 10.2, 11.0, or 11.1.
Sparse attention modules
- MatMul: This module handles block-sparse matrix-matrix multiplication. Currently it supports SDD, DSD, and DDS as described in DeepSpeed Sparse Attention section.
- Softmax: This module applies block sparse softmax. It handles both forward and backward pass.
- SparseSelfAttention: This module uses MatMul and Softmax kernels and generates Context Layer output given Query, Keys and Values. It is a simplified version of common operations in any self-attention layer. It can also apply:
Relative position embeddingAttention maskKey padding maskon the intermediate attention scores. For more details about self attention, please check MultiHeadAttention.
- BertSparseSelfAttention: This module contains a simplified BertSelfAttention layer that can be used instead of original dense Bert Self-Attention layer. Our implementation is based on DeepSpeedExample.
- SparseAttentionUtils: This module provides few utility functions to handle adapting pre-trained model with sparse attention:
replace_model_self_attention_with_sparse_self_attention: If you have currently loaded a model and want to replace self-attention module with sparse self-attention, you can simply use this function to handle it for you. It currently handles BERT and RoBERTa based pre-trained models, but you can extend it base on your model type if it is different from these two. You also need to extend the position embedding to handle new sequence length; this can be done usingextend_position_embeddingfunction.update_tokenizer_model_max_length: This function simply updates maximum position embedding in your tokenizer with the new value.extend_position_embedding: This function extends the position embedding based on the current values. For example, if you have a 128 max sequence length model and extending it to a 1k sequence length, it replicates current embeddings 8 times to initialize new embedding. Experimentally we have seen such initialization works much better than initializing from scratch; leads to faster convergence.pad_to_block_size: This function pads input tokens and attention mask on sequence length dimension to be multiple of block size; this is a requirement for SA.unpad_sequence_output: This function unpads sequence output if inputs of the model were padded.
- SparsityConfig: this is an abstract class for sparsity structure. Any sparsity structure needs to extend this class and writes its own sparsity pattern construction;
make_layoutfunction. DeepSpeed currently provides the following structures that will be described in How to config sparsity structures section:FixedSparsityConfigBSLongformerSparsityConfigBigBirdSparsityConfigVariableSparsityConfigDenseSparsityConfig
Note: Currently DeepSpeed Transformer Kernels do not support Sparse Attention. To use Sparse Attention, you need to disable Transformer Kernels!
How to use sparse attention with DeepSpeed launcher
In this section we describe how to use DeepSpeed Sparse Attention through our bing_bert code.
- Update attention module: First, you need to update your attention module based on sparse computation. Here, we use BertSparseSelfAttention which is the sparse version of
BertSelfAttentionfrom our bing_bert code. It rewritesBertSelfAttentionwhere it replaces:
attention_scores = torch.matmul(query_layer, key_layer)
attention_scores = attention_scores / math.sqrt(
self.attention_head_size)
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
pdtype = attention_scores.dtype
# Normalize the attention scores to probabilities.
attention_probs = self.softmax(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)
with:
context_layer =
self.sparse_self_attention(
query_layer,
key_layer,
value_layer,
key_padding_mask=attention_mask)
in which sparse_self_attention is an instance of SparseSelfAttention. This module computes attention context through sparse attention replacing underlying matrix multiplications and softmax with their equivalent sparse version. You can update any other attention module similarly.
- Setup sparse attention config in the model: You need to setup the sparse attention config. In our example, this is done in the
BertModel.
self.pad_token_id = config.pad_token_id if hasattr(
config, 'pad_token_id') and config.pad_token_id is not None else 0
# set sparse_attention_config if it has been selected
self.sparse_attention_config = get_sparse_attention_config(
args, config.num_attention_heads)
self.encoder = BertEncoder(
config, args, sparse_attention_config=self.sparse_attention_config)
- Update encoder model: Further, you need to update your encoder model to use SA for the attention layer when SA is enabled. Please check our bing_bert example in which we use
BertSparseSelfAttentioninstead ofBertSelfAttentionwhen SA is enabled.
if sparse_attention_config is not None:
from deepspeed.ops.sparse_attention import BertSparseSelfAttention
layer.attention.self = BertSparseSelfAttention(
config, sparsity_config=sparse_attention_config)
- Pad and unpad input data: Also you may need to pad sequence dimension of
input_idsandattention_maskto be multiple of sparse block size. As mentioned in module section above, DeepSpeed provides utility functions for padding and unpadding. Please check our bing_bert example to see where and how pad and unpad the inputs or outputs of the model.
if self.sparse_attention_config is not None:
pad_len, input_ids, attention_mask, token_type_ids, position_ids, inputs_embeds = SparseAttentionUtils.pad_to_block_size(
block_size=self.sparse_attention_config.block,
input_ids=input_ids,
attention_mask=extended_attention_mask,
token_type_ids=token_type_ids,
position_ids=None,
inputs_embeds=None,
pad_token_id=self.pad_token_id,
model_embeddings=self.embeddings)
.
.
.
# If BertEncoder uses sparse attention, and input_ids were padded, sequence output needs to be unpadded to original length
if self.sparse_attention_config is not None and pad_len > 0:
encoded_layers[-1] = SparseAttentionUtils.unpad_sequence_output(
pad_len, encoded_layers[-1])
- *Enable sparse attention: To use DeepSpeed Sparse Attention, you need to enable it in the launcher script through
deepspeed_sparse_attentionargument:
--deepspeed_sparse_attention
Please check our bing_bert runner script as an example of how to enable SA with DeepSpeed launcher.
- Add sparsity config: The sparsity config can be set through the DeepSpeed JSON config file. In this example, we have used
fixedsparsity mode that will be described in How to config sparsity structures section.
"sparse_attention": {
"mode": "fixed",
"block": 16,
"different_layout_per_head": true,
"num_local_blocks": 4,
"num_global_blocks": 1,
"attention": "bidirectional",
"horizontal_global_attention": false,
"num_different_global_patterns": 4
}
How to use individual kernels
DeepSpeed Sparse Attention can be used as a feature through DeepSpeed, as described above, or simply integrated with any Transformer model as a self-attention module alone. Further, the building block kernels, matrix multiplication and softmax can be used separately. To use sparse attention alone, you can simply install DeepSpeed and import any of the modules described in modules section; example:
from deepspeed.ops.sparse_attention import SparseSelfAttention
Please refer to the Docstrings for details of how to use each module separately.
How to config sparsity structures
Following we describe supported sparsity structures, their parameter set and the flexibility of adding arbitrary sparsity pattern on the self-attention layer. You can update DeepSpeed config file using any of the supported sparsity structures and set the parameters accordingly.
- SparsityConfig:
This module, is the parent class for all sparsity structures and contains the shared features of all sparsity structures. It takes the following parameters:
num_heads: an integer determining number of attention heads of the layer.block: an integer determining the block size. Current implementation of sparse self-attention is based on blocked sparse matrices. In which this parameter defines size of such square blocks;Block X Block.different_layout_per_head: a boolean determining if each head should be assigned a different sparsity layout; default is false and this will be satisfied based on availability.
- Fixed (FixedSparsityConfig):
This structure is based on Generative Modeling with Sparse Transformers from OpenAI, in which local and global attention is fixed by the given parameters:
num_local_blocks: an integer determining the number of blocks in local attention window. As it is illustrated in the below figure (adapted from original paper), tokens in a local window, attend to all tokens local to them. In the case of autoregressive model, as in the figure, tokens attend to tokens appearing before them in the local window. And in the case of Masked model such as BERT, attention is bidirectional.num_global_blocks: an integer determining how many consecutive blocks in a local window is used as the representative of the window for global attention; illustrated in the figure below as well.attention: a string determining attention type. Attention can beunidirectional, such as autoregressive models, in which tokens attend only to tokens appear before them in the context. Considering that, the upper triangular of attention matrix is empty as above figure. Or it can bebidirectional, such as BERT, in which tokens can attend to any other tokens before or after them. Then, the upper triangular part of the attention matrix is mirror of the lower triangular in the above figure.horizontal_global_attention: a boolean determining if blocks that are global representative of a local window, also attend to all other blocks. This is valid only if attention type isbidirectional. Looking at the attention matrix, that means global attention not only includes the vertical blocks, but also horizontal blocks.num_different_global_patterns: an integer determining number of different global attentions layouts. While global attention can be fixed by which block/s are representative of any local window, since there are multi-heads, each head can use a different global representative. For example, with 4 blocks constructing local window and global attention size of a single block, we can have 4 different versions in which the first, second, third, or forth block of each local window can be global representative of that window. This parameter determines how many of such patterns we want. Of course, there is a limitation based onnum_local_blocksandnum_global_blocks. Further, if you set this to more than one, you need to setdifferent_layout_per_headtoTrue.
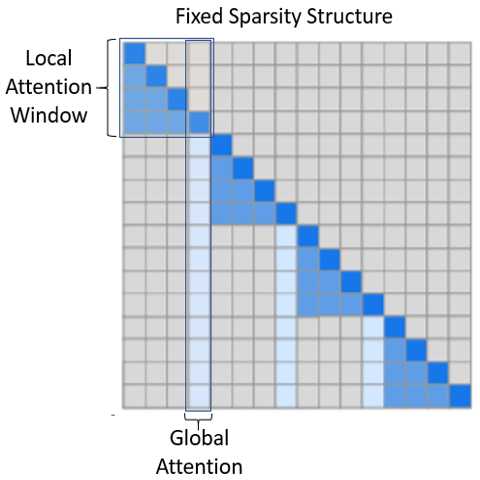
- BSLongformer (BSLongformerSparsityConfig):
This structure is an edited version of Longformer: The Long-Document Transformer, in which instead of single token-wise sparsity, we offer block of tokens sparsity. Parameters that define this patters are:
num_sliding_window_blocks: an integer determining the number of blocks in sliding local attention window.global_block_indices: a list of integers determining which blocks are considered as global attention. Given indices, determine the blocks that all other token blocks attend to and they attend to all other token blocks. Notice that ifglobal_block_end_indicesparameter is set, this parameter is used as starting index of each global window.global_block_end_indices: a list of integers determining end indices of global window blocks. By default this is not used. But if it is set, it must have the same size asglobal_block_indicesparameter, and combining this two parameters, for each indexi, blocks fromglobal_block_indices[i]toglobal_block_end_indices[i](exclusive) are considered as global attention block.
- BigBird (BigBirdSparsityConfig):
This structure is based on Big Bird: Transformers for Longer Sequences. It somehow combines the idea of
fixedandlongformerpatterns along with random attention. Following parameters define this structure:num_random_blocks: an integer determining how many blocks in each row block are attended randomly.num_sliding_window_blocks: an integer determining the number of blocks in sliding local attention window.num_global_blocks: an integer determining how many consecutive blocks, starting from index 0, are considered as global attention. Global block tokens will be attended by all other block tokens and will attend to all other block tokens as well.
- Variable (VariableSparsityConfig):
This structure also combines the idea of local, global and random attention. Further, it has the flexibility of defining variable size local windows. Following is the list of parameters that define this structure:
num_random_blocks: an integer determining how many blocks in each row block are attended randomly.local_window_blocks: a list of integers determining the number of blocks in each local attention window. It assumes first number determines # of blocks in the first local window, second number the second window, …, and the last number determines the number of blocks in the remaining local windows.global_block_indices: a list of integers determining which blocks are considered as global attention. Given indices, determine the blocks that all other token blocks attend to and they attend to all other token blocks. Notice that ifglobal_block_end_indicesparameter is set, this parameter is used as starting index of each global window.global_block_end_indices: a list of integers determining end indices of global window blocks. By default this is not used. But if it is set, it must have the same size asglobal_block_indicesparameter, and combining this two parameters, for each indexi, blocks fromglobal_block_indices[i]toglobal_block_end_indices[i](exclusive) are considered as global attention block.attention: a string determining attention type. Attention can beunidirectional, such as autoregressive models, in which tokens attend only to tokens appear before them in the context. Considering that, the upper triangular of attention matrix is empty as above figure. Or it can bebidirectional, such as BERT, in which tokens can attend to any other tokens before or after them. Then, the upper triangular part of the attention matrix is mirror of the lower triangular in the above figure.horizontal_global_attention: a boolean determining if blocks that are global representative of a local window, also attend to all other blocks. This is valid only if attention type isbidirectional. Looking at the attention matrix, that means global attention not only includes the vertical blocks, but also horizontal blocks Figure below illustrates an example ofvariablesparsity, in which blue, orange and green blocks illustrate local, global, and random attention blocks respectively.
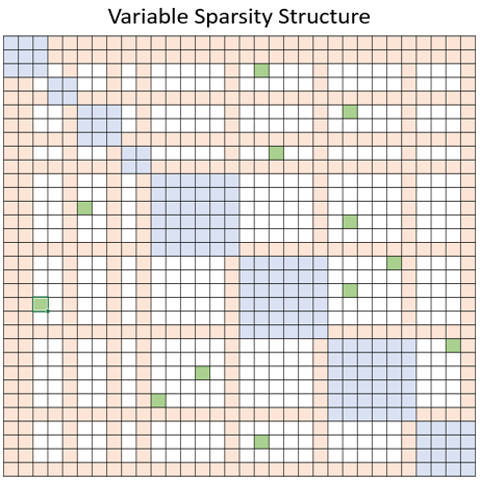
Further, we provide a dense pattern (DenseSparsityConfig), that can be used for the sake of testing while it represents the full attention.
How to support new user defined sparsity structures
Our building block kernels, block-based MatMul and Softmax, can accept any block-based sparsity. This provides the flexibility to apply any block-based sparsity pattern to attention score. To define and apply a new sparsity pattern, you can simply follow any of the above sparsity structures. You need to add a new class that expands SparsityConfig and define make_layout function based on how your sparsity is structured. You can add any extra parameters you may need or just use default parameters of the parent class.