DeepSpeed Sparse Attention
Attention-based deep learning models such as the transformers are highly effective in capturing the relationship between tokens in an input sequence, even across long distances. As a result, they are used with text, image, and sound-based inputs, where the sequence length can be in thousands of tokens. However, despite the effectiveness of attention modules to capture long term dependencies, in practice, their application to long sequence input is limited by compute and memory requirements of the attention computation that grow quadratically, O(n^2), with the sequence length n.
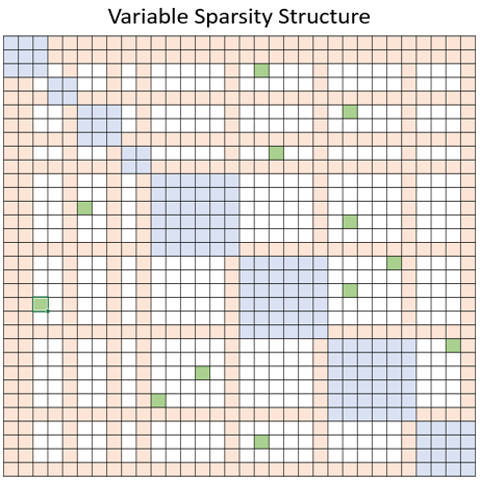
To address this limitation, DeepSpeed offers a suite of sparse attention kernels –an instrumental technology that can reduce the compute and memory requirement of attention computation by orders-of-magnitude via block-sparse computation. The suite not only alleviates the memory bottleneck of attention calculation, but also performs sparse computation efficiently. Its APIs allow convenient integration with any transformer-based models. Along with providing a wide spectrum of sparsity structures, it has the flexibility of handling any user-defined block-sparse structures. More specifically, sparse attention (SA) can be designed to compute local attention between nearby tokens, or global attention via summary tokens computed with local attention. Moreover, SA can also allow random attention, or any combination of local, global, and random attention as shown in the following figure with blue, orange, and green blocks, respectively. As a result, SA decreases the memory footprint to O(wn), in which 1 < w < n is a parameter, whose value depends on the attention structure.
This library is PyTorch based and develops required kernels through Triton platform; kernels are not written in CUDA, which leaves the door open for CPU/OpenCL/Vulkan support in the future. The library is an extension to DeepSpeed and can be used through DeepSpeed as well as stand alone.
Block-sparse computations handled by DeepSpeed Sparse Attention kernels are illustrated in following figures for forward and backward passes respectively. In the figures, S stands for a block-sparse matrix and D a dense matrix.
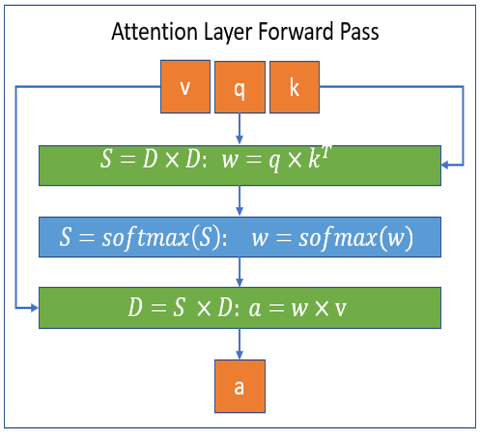
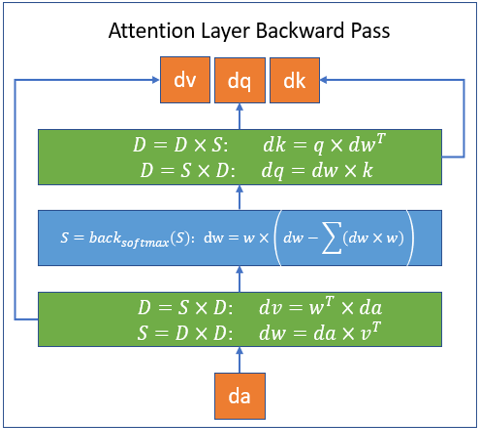
To learn more about Sparsity Config, and also how to use this library, please check our tutorial that provides detailed information about it.
Performance Results
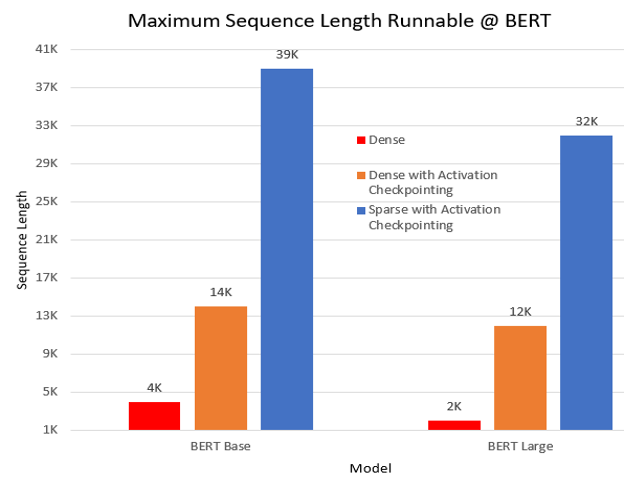
- Power over 10x longer sequences In a pre-training experiment, we ran BERT model under three settings: dense, dense with activation checkpoint, and sparse (SA) with activation checkpoint. SA empowers 10x and 16x longer sequences comparing with dense for BERT base and large, respectively. Following figure shows the longest sequence length runnable in BERT base and large model; experiment is performed with batch size 1 on a single NVIDIA V100 GPU-32GB memory.
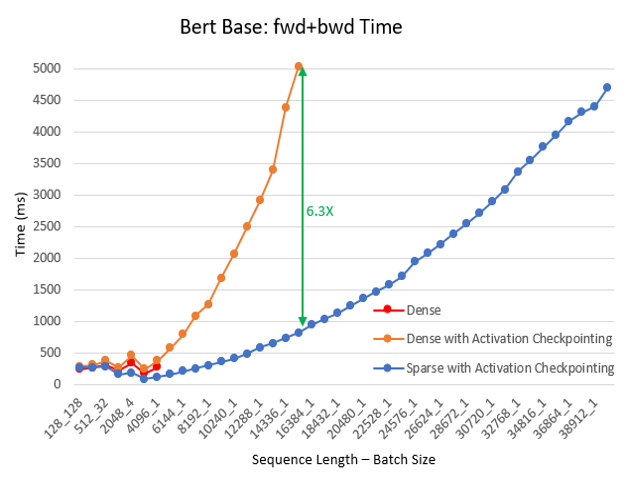
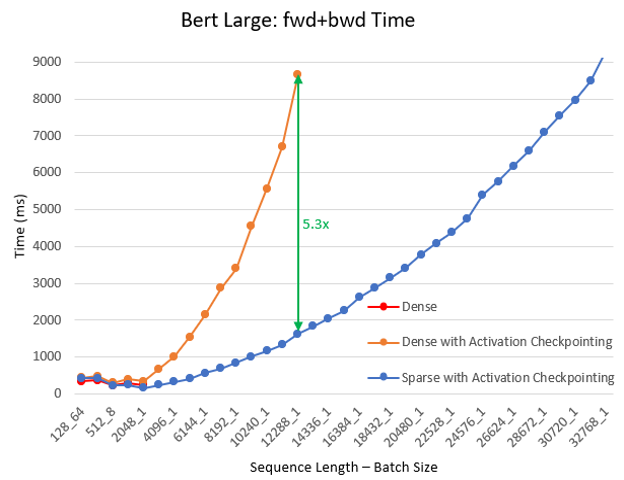
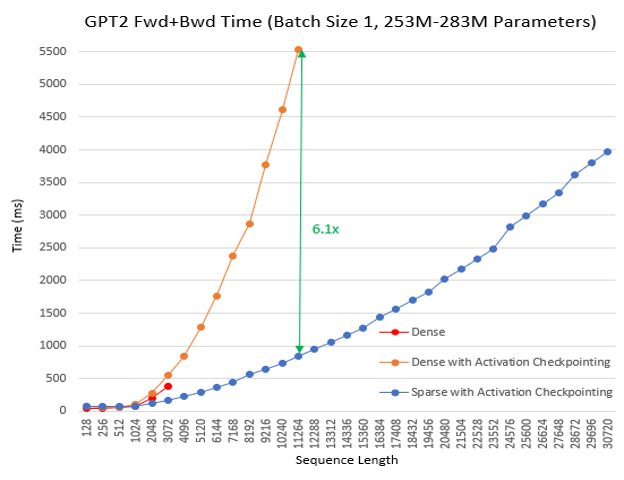
- Up to 6.3x faster computation We continued the pre-training experiment for different batch sizes and sequence lengths, using BERT base/large and Megatron GPT2. In this experiment we let the training to continue for 100 iteration and recorded the average time per last 30 iterations. SA reduces total computation comparing with dense and improves training speed: the boost is higher with increased sequence length and it is up to 6.3x faster for BERT base, 5.3x for BERT large, and 6.1x for GPT2. Following charts show these results.
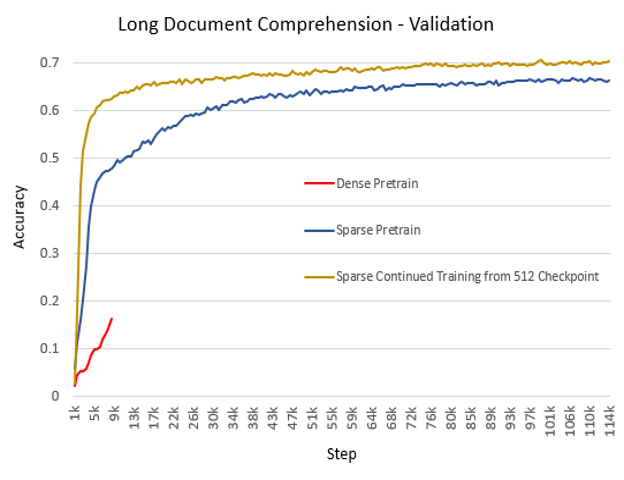
- Higher accuracy Related works along the line of sparse attention (Sparse Transformer, Longformer, BigBird) have shown comparable or higher accuracy than full attention. Our experience is well aligned. In addition to lower memory overhead and faster computation, we also observe cases in production where SA reaches higher accuracy and faster convergence. The following chart illustrates accuracy of training a production model based on BERT for long document comprehension (2,048 sequence length). The experiment is performed in three settings: dense starting from scratch, SA starting from scratch, and SA continued training from a checkpoint of using dense with sequence length of 512. We have observed that, for pre-training from scratch, SA converges faster with higher accuracy comparing with dense. Furthermore, SA continuing training from a pre-trained checkpoint performs even better, with respect to both time and accuracy.
- Comparison with state of the art, Longformer
We compared SA with Longformer, a state-of-the-art sparse structure and implementation. In our experiment, SA uses
Fixedsparsity, and two implementations have comparable accuracy. On system performance, SA outperforms Longformer both in training and inference:- 1.47x faster execution pre-training MLM on Wikitext103 We ran an experiment following the notebook offered by Longformer. In this experiment, we pre-train an MLM model using RoBERTa-base checkpoint. This is done on 8 V100-SXM2 GPU. Following table shows the details of the result in which using DeepSpeed Sparse Attention shows 1.47x speed up.
| Model | Local Window Size | BPC | Train Step | Time Per Iteration | Time Improvement | Accuracy improvement |
|---|---|---|---|---|---|---|
| RoBERTa Checkpoint | 2.5326 | |||||
| Longformer | 512 | 2.6535 | 0 | 1.47 | 1.01 | |
| Sparse Attention | 2.6321 | |||||
| Longformer | 1.6708 | 3k | 1.6280 | 1.01 | ||
| Sparse Attention | 1.6613 | 1.1059 | ||||
| Longformer | 64 | 5.7840 | 0 | 1.31 | 1.46 | |
| Sparse Attention | 3.9737 | |||||
| Longformer | 2.0466 | 3k | 1.4855 | 1.09 | ||
| Sparse Attention | 1.8693 | 1.1372 |
- 3.13x faster execution inference on BERT-Base
Through our Long Document Comprehension application we described above, we also checked the inference time for different window sizes testing BERT model on a
2,048Sequence Length and batch size1. In this experiment, we noticed up to3.13Xspeed up replacing Bert Attention with DeepSpeed Sparse Attention instead of Longformer Attention. Following table shows the complete result.
| Local Window Size | Time Improvement |
|---|---|
| 512 | 3.13 |
| 256 | 2.29 |
| 128 | 2.16 |
| 64 | 1.5 |
| 32 | 1.24 |
| 16 | 1.23 |
- Flexibility to handle any block-sparse structure
DeepSpeed Sparse Attention suite does not target at any specific sparse structure but enables model scientists to explore any block sparse structure with efficient system support. Currently, we have added popular sparse structure like:
- Fixed (from OpenAI Sparse Transformer)
- BigBird (from Google)
- BSLongformer (Block-Sparse implementation of Longformer from AI2)
We also define a template to have variable structure (top figure), which can be used to simply customize any block-sparse random/local/global attention pattern. In addition to this list, user can add any other sparsity structure as described in tutorial section.