ZeRO-Offload
ZeRO-3 Offload consists of a subset of features in our newly released ZeRO-Infinity. Read our ZeRO-Infinity blog to learn more!
We recommend that you read the tutorials on Getting Started and ZeRO before stepping through this tutorial.
ZeRO-Offload is a ZeRO optimization that offloads the optimizer memory and computation from the GPU to the host CPU. ZeRO-Offload enables large models with up to 13 billion parameters to be efficiently trained on a single GPU. In this tutorial we will use ZeRO-Offload to train a 10-billion parameter GPT-2 model in DeepSpeed. Furthermore, using ZeRO-Offload in a DeepSpeed model is quick and easy because all you need is to change a few configurations in the DeepSpeed configuration json. No code changes are needed.
ZeRO-Offload Overview
For large model training, optimizers such as Adam, can consume a significant amount of GPU compute and memory. ZeRO-Offload reduces the GPU compute and memory requirements of such models by leveraging compute and memory resources on the host CPU to execute the optimizer. Furthermore, to prevent the optimizer from becoming a bottleneck, ZeRO-Offload uses DeepSpeed’s highly optimized CPU implementation of Adam called DeepSpeedCPUAdam. DeepSpeedCPUAdam is 5X–7X faster than the standard PyTorch implementation. To deep dive into the design and performance of ZeRO-Offload, please see our blog post.
Training Environment
For this tutorial, we will configure a 10 billion parameter GPT-2 model using the DeepSpeed Megatron-LM GPT-2 code. We advise stepping through the Megatron-LM tutorial if you have not previously done so. We will use a single NVIDIA Tesla V100-SXM3 Tensor Core GPU with 32GB RAM for this exercise.
Training a 10B parameter GPT-2 on a single V100 GPU
We need to make changes to the Megatron-LM launch script and to the DeepSpeed configuration json.
Megatron-LM GPT-2 launch script changes
We need to apply two changes to the launch script for the DeepSpeed Megatron-LM GPT-2 model. The first change is to configure a 10B parameter GPT-2 model with activation checkpointing enabled, which can be achieved by the following set of changes:
--model-parallel-size 1 \
--num-layers 50 \
--hidden-size 4096 \
--num-attention-heads 32 \
--batch-size 10 \
--deepspeed_config ds_zero_offload.config \
--checkpoint-activations
Most of the flags in the changes above should be familiar if you have stepped through the Megatron-LM tutorial.
Second, we need to apply the following changes to ensure that only one GPU is used for training.
deepspeed --num_nodes 1 --num_gpus 1 ...
DeepSpeed Configuration Changes
ZeRO-Offload leverages many ZeRO stage 1 and 2 mechanisms, and so the configuration changes to enable ZeRO-Offload are an extension of those required to enable ZeRO stage 1 or 2. The zero_optimization configuration to enable ZeRO-Offload is shown below:
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
}
"contiguous_gradients": true,
"overlap_comm": true
}
}
As seen above, in addition to setting the stage field to 2 (to enable ZeRO stage 2, but stage 1 also works), we also need to set the offload_optimizer device to cpu to enable ZeRO-Offload optimizations. In addition, we can set other ZeRO stage 2 optimization flags, such as overlap_comm to tune ZeRO-Offload performance. With these changes we can now run the model. We share some screenshots of the training below.
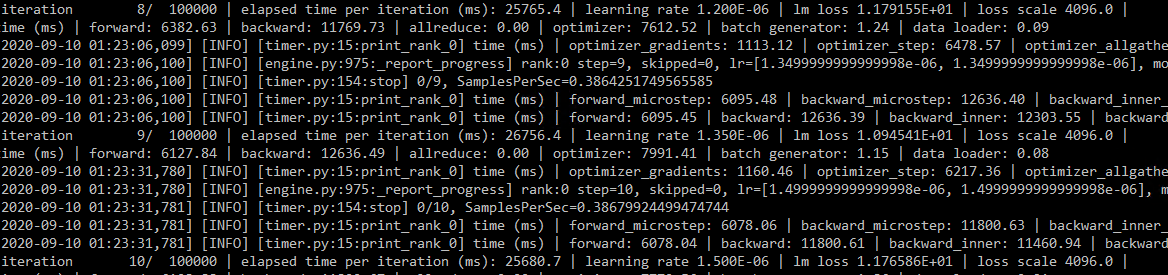
Here is a screenshot of the training log:
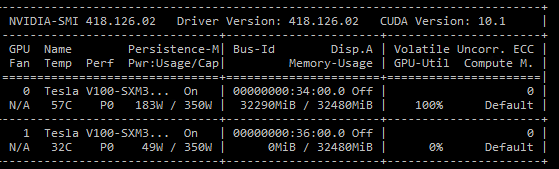
Here is a screenshot of nvidia-smi showing that only GPU 0 is active during training:
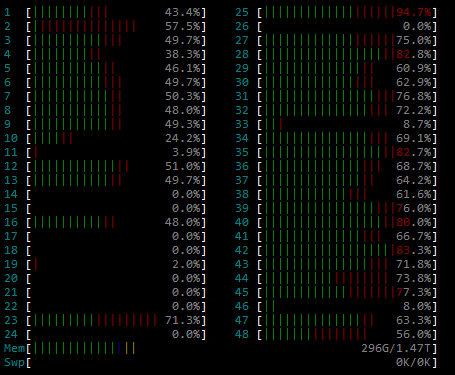
Finally, here is a screenshot of htop showing host CPU and memory activity during optimizer computation:
CPU Adam perf tuning
ZeRO offload already support multi-gpu training. If the workload is using CPU optimizer, the workload can be further tuned by passing --bind_cores_to_rank to the deepspeed launch command. This switch will mainly do two things:
- Divide physical CPU cores evenly among ranks, make each rank to have a dedicated set of CPU cores to run CPU optimizer.
- Set OMP_NUM_THREADS environment variable to the number of CPU cores assigned to each rank, so OpenMP code in CPU optimizer will have near optimal performance.
ZeRO offload is a hybrid workload that is both heavy on GPU and CPU, and DeepSpeed is optimized for both GPU and CPU performance. Refer to How to launch DeepSpeed on Intel Architecture CPU for more details on how to tune core bindings for CPU performance.
Congratulations! You have completed the ZeRO-Offload tutorial.