DeepSpeed Inference: Multi-GPU inference with customized inference kernels and quantization support
While DeepSpeed supports training advanced large-scale models, using these trained models in the desired application scenarios is still challenging due to three major limitations in existing inference solutions: 1) lack of support for multi-GPU inference to fit large models and meet latency requirements, 2) limited GPU kernel performance when running inference with small batch sizes, and 3) difficulties in exploiting quantization, which includes both quantizing the model to reduce the model size and latency as well as supporting high-performance inference of quantized models without specialized hardware.
To handle these challenges, we introduce DeepSpeed Inference, which seamlessly adds high-performance inference support to large models trained in DeepSpeed with three key features: inference-adapted parallelism for multi-GPU inference, inference-optimized kernels tuned for small batch sizes, and flexible support for quantize-aware training and inference kernels for quantized models.
Multi-GPU Inference with Adaptive Parallelism
Parallelism is an effective approach to fit large models and reduce per-device memory consumption for both training and inference. However, simply applying training parallelism choices and degree to inference does not work well. The MP and PP configuration is normally set during the model training, apart from the data parallelism (DP), based on the memory footprint and computation style, and resource budget. On one hand, inference computation intrinsically requires less memory, so it can afford a larger partition per device. It helps reduce the degree of parallelism needed for model deployment. On the other hand, optimizing latency or meeting latency requirements is often a first-class citizen in inference while training optimizes throughput.
To obtain desired latency, DeepSpeed Inference automatically adapts MP as an effective approach to reduce model latency, and its parallelism degree is often determined first. With MP, we can split the mode and parallelize computational operations across multiple devices (GPUs) to reduce latency, but it reduces computation granularity and increases communication that may hurt throughput. Once the latency target has been met, DeepSpeed can apply pipeline parallelism to maximize the throughput. Overall, DeepSpeed Inference supports flexible adaptation of both parallelism approach and degree choices from training to inference, minimizing latency while saving deployment costs.
Customized Inference Kernels for Boosted Compute Efficiency of Transformer Blocks
To achieve high compute efficiency, DeepSpeed-inference offers inference kernels tailored for Transformer blocks through operator fusion, taking model-parallelism for multi-GPU into account. The main difference between our kernel-fusion scheme and similar approaches is that we not only fuse element-wise operations (such as bias-add, residual, and activation function), but also merge the General matrix multiply (GeMM) operations with other operations. To do this, we design an efficient implementation for the vector-matrix or skinny matrix-matrix multiplication that allows us to fuse more operations at the reduction boundary of GeMM operations.
Kernel-Fusion
We take two main policies for fusing operations: 1) keeping the access-pattern of inputs and outputs intact throughout the sequence of operations fused together; 2) fusing operations at each all-reduce boundary. The first policy ensures that different thread-blocks won’t encounter transferring data between Streaming-Multiprocessors (SMs). This is due to no straight-forward communication among SMs other than using the main memory which adds the block-synching overhead because of non-deterministic behavior of memory access. The reason behind the second policy is that we cannot continue the execution unless the partial results are reduced among the model-parallel GPUs.
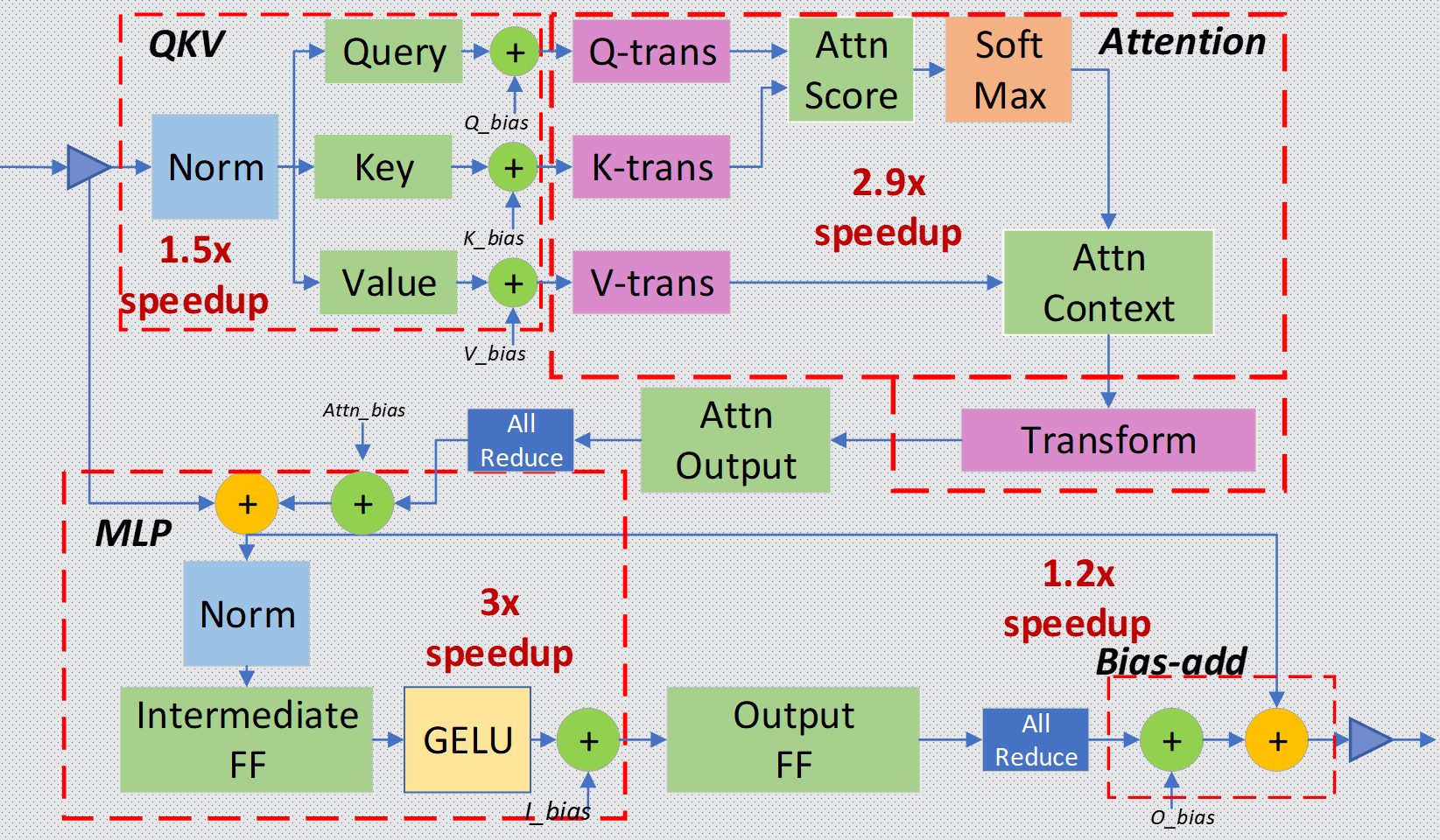
Figure 1: Transformer Layer with Megatron-style model-parallelism all-reduce components. The figure illustrates the parts of layer fused together with broken lines (width of line shows the fusion depth).
Figure 1 shows the different components of a Transformer layer, and the groups of operations considered for fusion in our inference optimization. We also consider the NVIDIA Megatron-LM style of parallelism that partitions attention (Attn) and feed-forward (FF) blocks across multiple GPUs. Thus, we include the two all-reduce operations that reduce the results among parallel GPUs after Attn and FF blocks. As Figure 1 shows, we fuse the operations inside a Transformer layer at four main regions:
- Input Layer-Norm plus Query, Key, and Value GeMMs and their bias adds.
- Transform plus Attention.
- Intermediate FF, Layer-Norm, Bias-add, Residual, and Gaussian Error Linear Unit (GELU).
- Bias-add plus Residual.
To fuse these operations, we exploit shared-memory as an intermediate cache for transferring data between reduction operations used in layer-norm and GeMM, and the element-wise operations. Moreover, we use the warp-level instructions to communicate data between threads when reducing partial computations. In addition, we use a new schedule for GeMM operations, which allows for fusing as many operations as needed for the third kernel-fusion. We also combine the GeMMs for the attention computation in the second kernel-fusion, by using an implicit matrix transformation in order to reduce the memory pressure. Compared to the unfused computation style using cuBLAS GeMM, we improve the performance by 1.5x, 2.9x. 3x, and 1.2x for all these kernel-fusions, respectively.
Seamless pipeline from training to inference with automatic kernel-injection
To run the model in Inference mode, DeepSpeed simply requires the location of the model checkpoints and the desired parallelism configuration, i.e., MP/PP degree. DeepSpeed Inference kernels can also be enabled for many well-known model architectures such as HuggingFace (Bert and GPT-2) or Megatron GPT-based models using a pre-defined policy map that maps the original parameters to the parameters in the inference kernels. For other transformer-based models, user can specify their own policy map. Note that DS-Inference can run independent of the training pipeline as long as it receives all model checkpoints, and the DeepSpeed Transformer kernels for inference can be injected into any Transformer model if the right mapping policy is defined. For more information on how to enable Transformer inference kernel as well as specifying parallelism, please refer to out inference tutorial.
Flexible quantization support
To further reduce the inference cost for large-scale models, we created the DeepSpeed Quantization Toolkit, supporting flexible quantize-aware training and high-performance kernels for quantized inference.
For training, we introduce a novel approach called Mixture of Quantization (MoQ), which is inspired by mixed-precision training while seamlessly applying quantization. With MoQ, we can control the precision of the model by simulating the impact of quantization when updating the parameters at each step of training. Moreover, it supports flexible quantization policies and schedules—we find that by dynamically adjusting the number of quantization bits during training, the final quantized model provides higher accuracy under the same compression ratio. To adapt to different tasks, MoQ can also leverage the second order information of models to detect their sensitivity to precision and adjust the quantization schedule and target accordingly.
To maximize the performance gains from the quantization model, we provide inference kernels tailored for quantized models that reduce latency through optimizing data movement but do not require specialized hardware. Finally, our toolkit does not require any code changes on the client side, making it easy to use.
Performance results
Boosting throughput and reducing inference cost. Figure 3 shows the inference throughput per GPU for the three model sizes corresponding to the three Transformer networks, GPT-2, Turing-NLG, and GPT-3. DeepSpeed Inference increases in per-GPU throughput by 2 to 4 times when using the same precision of FP16 as the baseline. By enabling quantization, we boost throughput further. We reach a throughput improvement of 3x for GPT-2, 5x for Turing-NLG, and 3x for a model that is similar in characteristics and size to GPT-3, which directly translates to 3–5x inference cost reduction on serving these large models. In addition, we achieve these throughput and cost improvements without compromising latency as shown in Figure 5.
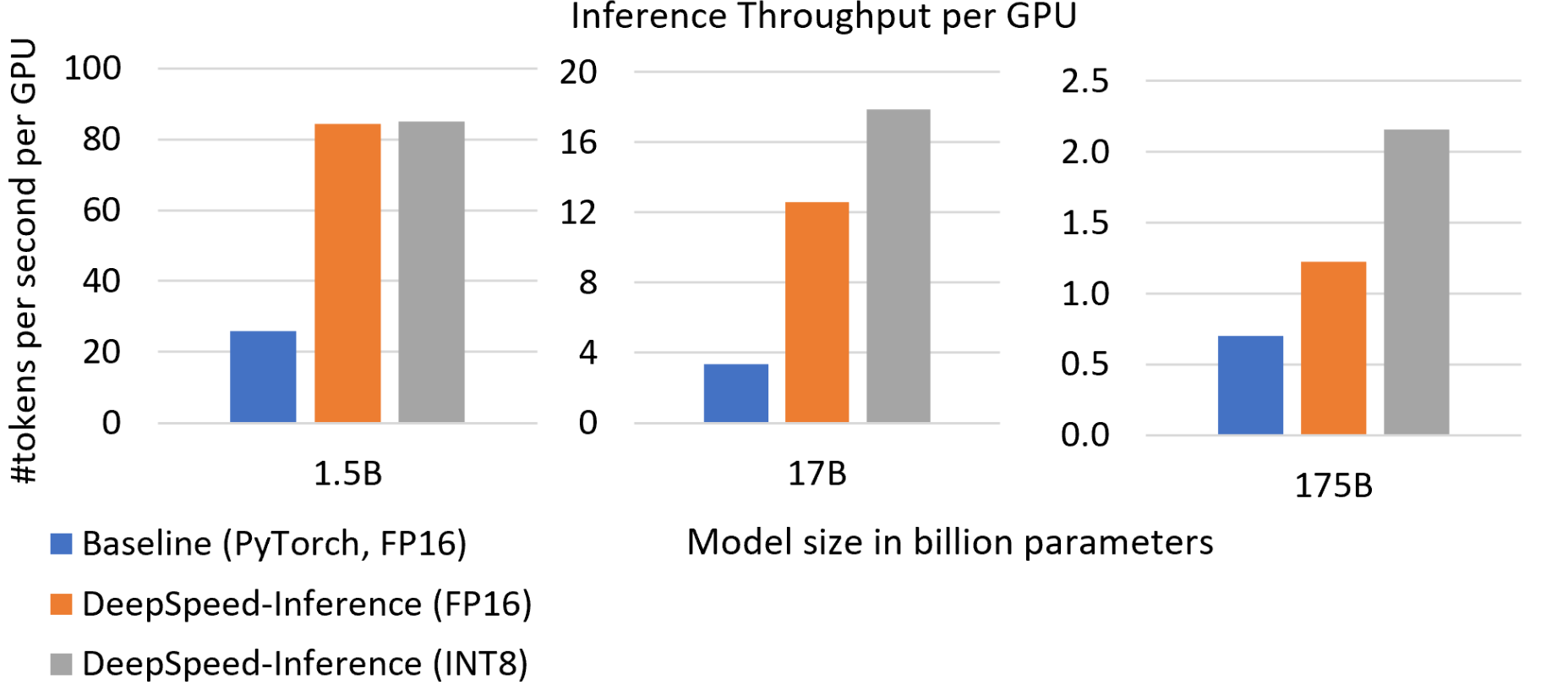
Figure 3: Inference throughput for different model sizes. DeepSpeed Inference achieves 3x to 5x higher throughput than baseline.
One source of inference cost reduction is through reducing the number of GPUs for hosting large models as shown in Figure 4. The optimized GPU resources comes from 1) using inference-adapted parallelism, allowing users to adjust the model and pipeline parallelism degree from the trained model checkpoints, and 2) shrinking model memory footprint by half with INT8 quantization. As shown in this figure, we use 2x less GPUs to run inference for the 17B model size by adapting the parallelism. Together with INT8 quantization through DeepSpeed MoQ, we use 4x and 2x fewer GPUs for 17B and 175B sizes respectively.
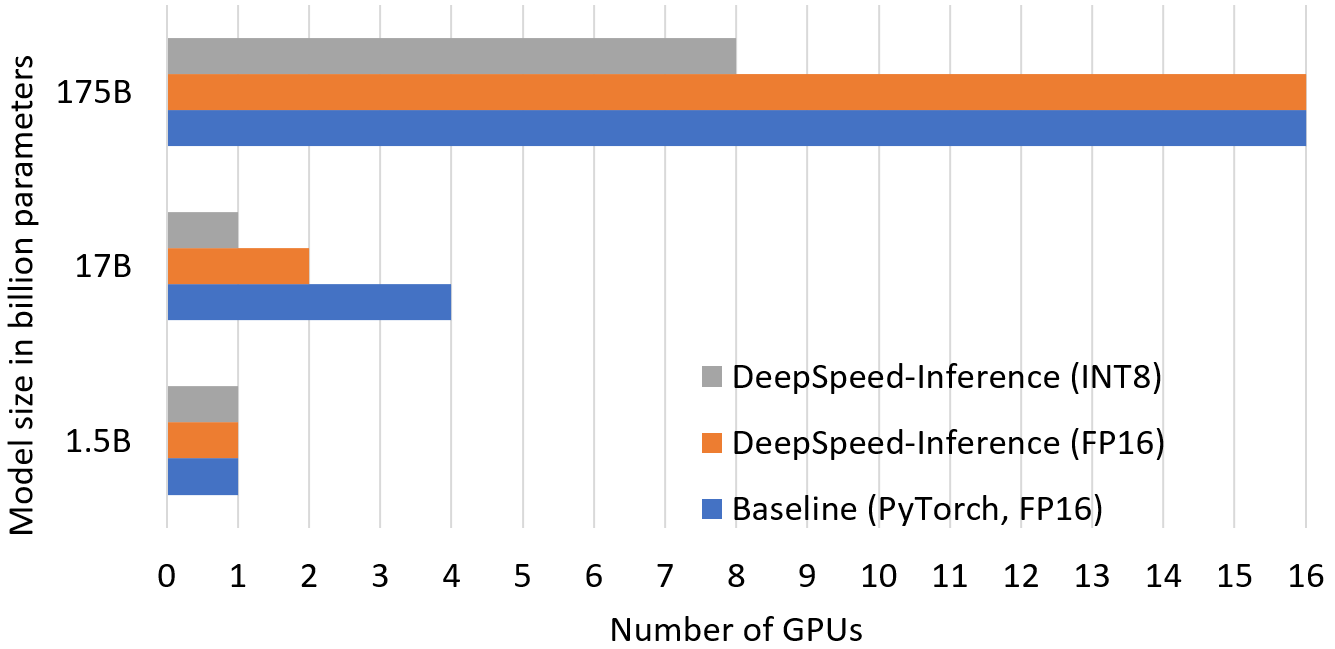
Figure 4: Number of GPUs used for running inference on the different model sizes shown in Figure 4.
Reducing inference latency. For the application scenarios where inference latency is critical, we can increase model parallelism degree in DeepSpeed Inference to reduce inference latency further. As Figure 5 depicts, we can reduce the latency by 2.3x compared to PyTorch as we increase the model-parallelism size to 4. Furthermore, we can still have high latency improvement with a fewer number of GPUs by adapting the parallelism at inference and using MoQ to quantize the model. We obtain 1.3x and 1.9x speedups while using 4x and 2x lower resources than baseline, respectively.
For the application scenarios where inference latency is critical, we can increase model parallelism degree in DeepSpeed Inference to reduce inference latency further. As Figure 5 depicts, we can reduce the latency by 2.3x compared to PyTorch as we increase the model-parallelism size to 4. Furthermore, we can still have high latency improvement with a fewer number of GPUs by adapting the parallelism at inference and using MoQ to quantize the model. We obtain 1.3x and 1.9x speedups while using 4x and 2x lower resources than baseline, respectively.
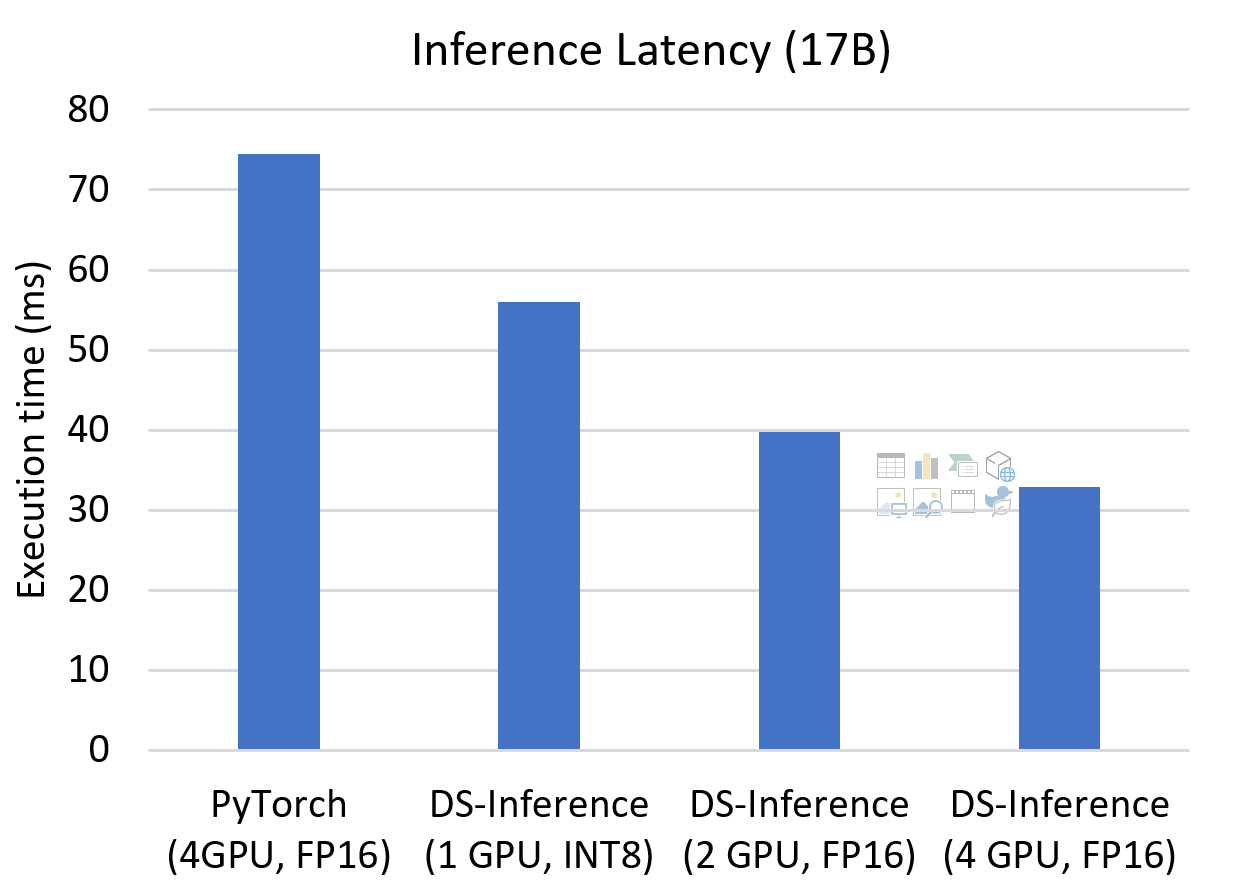
Figure 5. Inference latency for the 17B model using different parallelism configuration to optimize latency.