Azure empowers easy-to-use, high-performance, and hyperscale model training using DeepSpeed
Introduction
Large-scale transformer-based deep learning models trained on large amounts of data have shown great results in recent years in several cognitive tasks and are behind new products and features that augment human capabilities. These models have grown several orders of magnitude in size during the last five years. Starting from a few million parameters of the original transformer model all the way to the latest 530 billion-parameter Megatron-Turing model as shown in Figure 1. There is a growing need for customers to train and fine tune large models at an unprecedented scale.
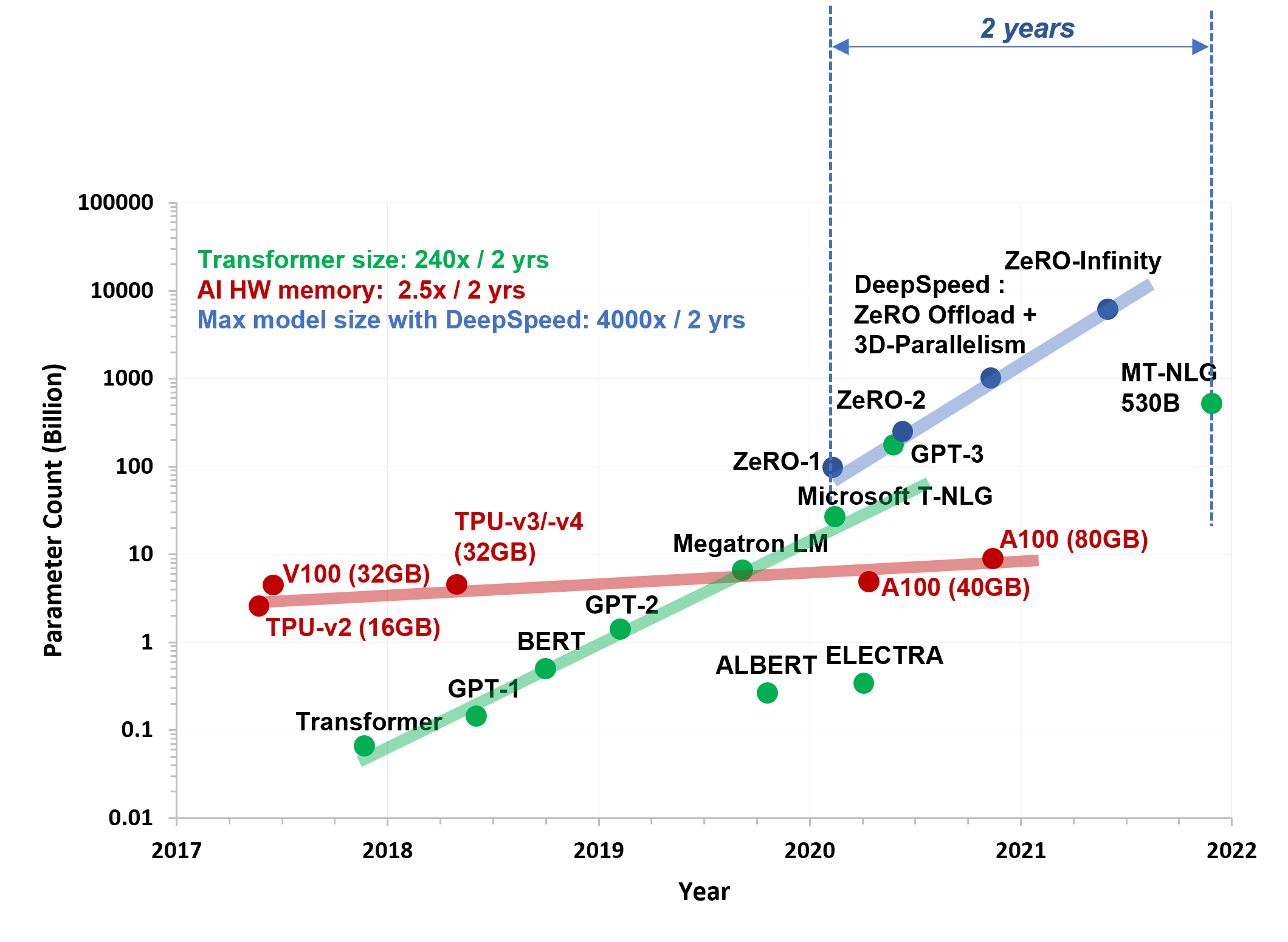
Figure 1: Landscape of large models and hardware capabilities
To train these models, users needed to set up and maintain a complex distributed training infrastructure that usually required several manual and error-prone steps. These lead to a subpar experience both in terms of usability and performance. We recently announced how we are making great strides to simplify this and enable easy-to-use and high-performance training at 1K+ GPU scale on Azure.
In this extended post, we share the details of how DeepSpeed users can train trillion-parameter models with a new easy-to-use, streamlined, scalable, and high-performance distributed training experience on Azure. We also share details of the experimental setup, model configurations, additional performance trends, and guide our users on how to run these experiments in their own environments.
Making distributed training faster and easier on Azure using DeepSpeed
We compare the existing manual and error-prone workflow with our proposed easy-to-use workflow for DeepSpeed on Azure in Figure 2. Customers can now use easy-to-use training pipelines to launch training jobs at scale. The new workflow reduces the number of steps from 11 to just 1 if users rely on the recommended AzureML recipes.
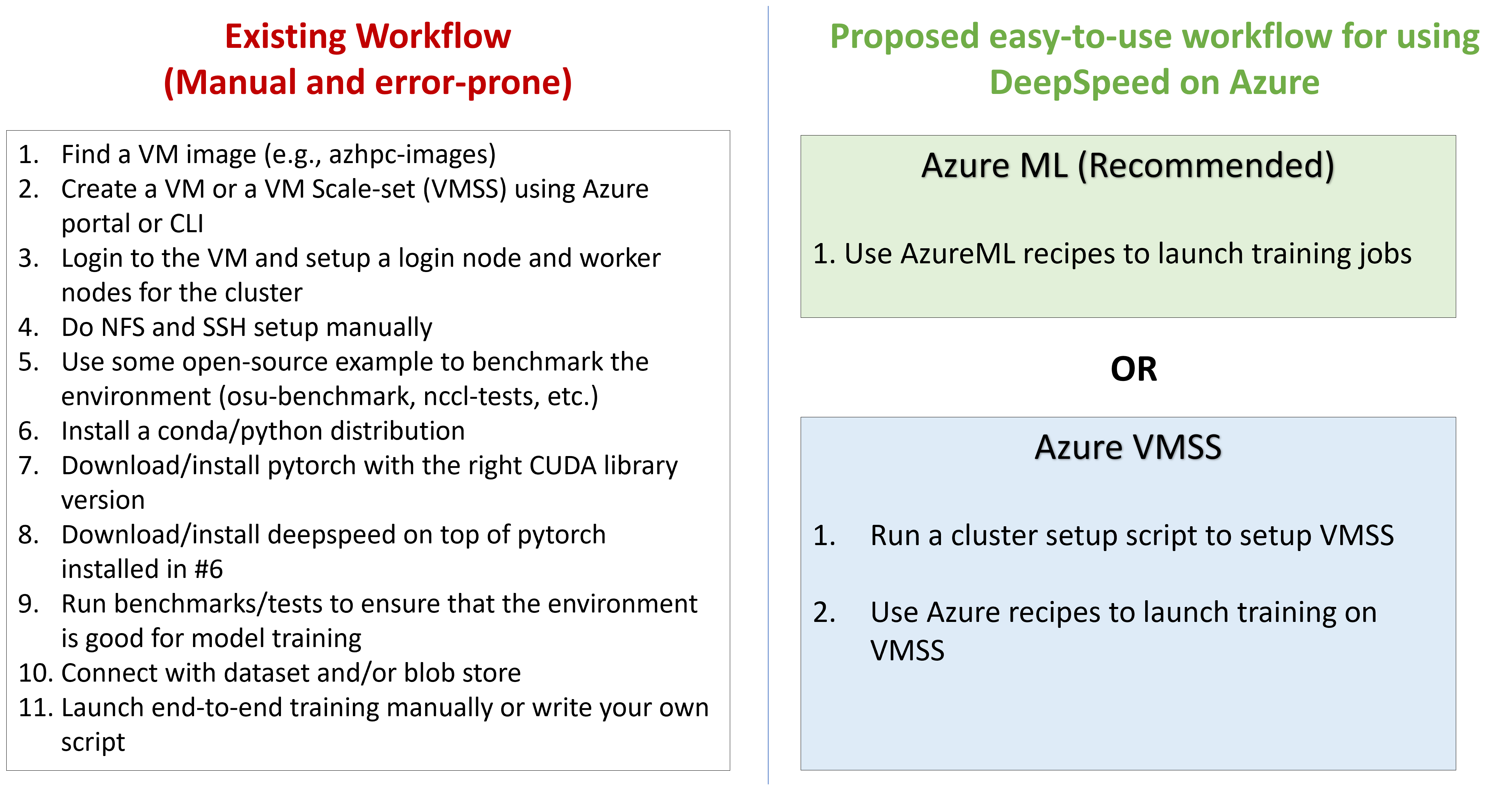
Figure 2: An easy-to-use and streamlined distributed training experience with DeepSpeed on Azure
For users who have custom environments built using Azure VMs or Azure VMSS, only two steps are needed:
- 1) Run the cluster setup script (to be released in the next few weeks)
- 2) Use the Azure VMSS recipes to launch training.
Key Performance Benefits
We already shared a summary of our key performance results in the Azure announcement. We enable the capability to train 2x larger model sizes (2 trillion vs. 1 trillion parameters), scale to 2x more GPUs (1024 vs. 512), and offer up to 1.8x higher compute throughput/GPU (150 TFLOPs vs. 81 TFLOPs) compared to other cloud providers.
DeepSpeed on Azure offers near-linear scalability both in terms of increase in model size as well as increase in number of GPUs. As shown in Figure 3a, together with the DeepSpeed ZeRO-3, its novel CPU offloading capabilities, and a high-performance Azure stack powered by InfiniBand interconnects and A100 GPUs, we were able to maintain an efficient throughput/GPU (>157 TFLOPs) in a near-linear fashion as the model size increases from 175 billion parameters to 2 trillion parameters. On the other hand, for a given model size, e.g., 175B, we achieve near-linear scaling as we increase the number of GPUs from 128 all the way to 1024 as shown in Figure 3b. The key takeaway is that Azure and DeepSpeed together are breaking the GPU memory wall and enabling our customers to easily and efficiently train trillion-parameter models at scale.
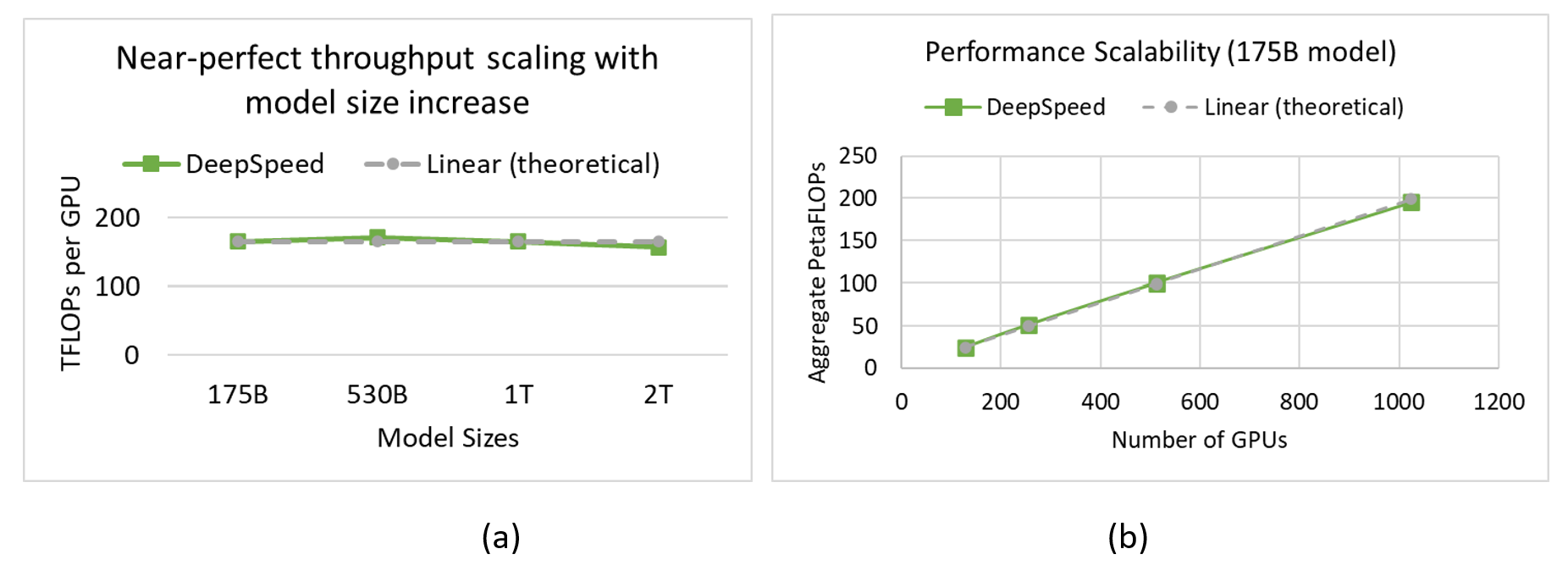
Figure 3: (a) Near-perfect throughput/GPU as we increase the model size from 175 billion to 2 trillion parameters (BS/GPU=8). (b) Near-perfect performance scaling with the increase in number of GPU devices for the 175B model (BS/GPU=16). The sequence length is 1024 for both cases.
Experimental Setup
We share the details of our experimental setup and some of the best practices we followed. The users can either directly use them to reproduce our results or modify them to fit their own setup in terms of model scale as well as the scale of Azure hardware being provisioned.
Hardware (Azure instances)
We used NDm A100 v4-series instances in our experiments. Each instance includes two socket AMD EPYC 7V12 64-Core CPUs, 1.7TB main memory and eight A100 80GB GPUs. The system has a balanced PCIe topology connecting 4 GPU devices to each CPU socket. Each GPU within the VM is provided with its own dedicated, topology-agnostic 200 Gb/s NVIDIA Mellanox HDR InfiniBand connection providing an accelerated 200 Gbps high speed fabric. The DeepSpeed library exploits offload capabilities where the activation and optimizer states are allocated in the main memory. Hence, 1.7TB memory capacity per node helps us to scale to large model sizes.
Training setup using AzureML
Users can directly use the AzureML studio and use our published recipes to run experiments without any additional setup. This is the easiest and recommended way of running experiments on Azure.
Training setup using Azure VMSS
Existing VMSS customers and others who have custom Azure VM based environments can follow the setup as follows. The scripts to make these steps easy will be released in the coming weeks. A cluster is created using Azure Virtual Machine Scale Sets (VMSS) to provision the desired number of compute nodes running the new Azure HPAI VM image specialized for extreme-scale deep learning applications using the software stack listed in Table 1.
| Name | Description (Version) |
|---|---|
| PyTorch | 1.10.2 (installed from source) |
| DeepSpeed | 0.6.2 (installed from source) |
| Megatron-LM | https://github.com/deepspeedai/Megatron-DeepSpeed |
| Apex | 0.1 |
| NCCL | 2.12.10 |
| CUDNN | 8.2.4.15 |
| CUDA | 11.4 |
| CUDA Driver | R470.82 |
| VM Image | Ubuntu-HPC 20.04 Image |
Table 1: Detailed version information of the software packages in the Azure HPC VM image
Users can create a VMSS with up to 600 VM instances enabling up to 4,800 A100 GPUs. In addition to the VMSS for the compute nodes, we provision a distinct login node using an inexpensive D4s v4 (or similar) instance with 4-core Intel VCPU, running the same image, for compiling, launching, and monitoring jobs. The login node, compute nodes, and a shared storage filesystem are grouped within an Azure Virtual Network (vnet) allowing VMs to connect to each other over SSH and to shared NFS volume shown in Figure 4.
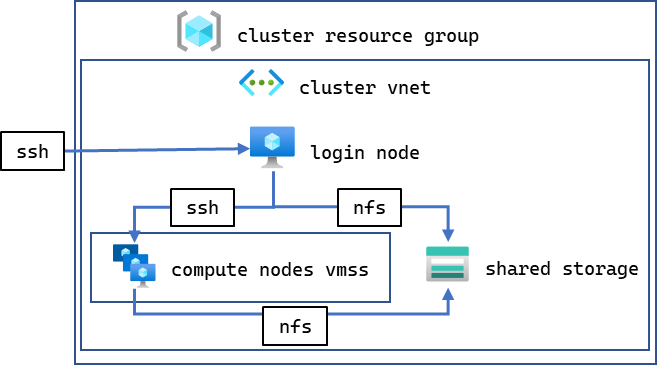
Figure 4: Organization of our VMSS-based experimental setup
Performance Evaluation on Various Model Configurations
We ran our experiments with four different model sizes – 175B, 530B, 1T, and 2T – using the configurations shown in Table 2.
| Model Size | 175B | 530B | 1T | 2T |
|---|---|---|---|---|
| Number of layers | 96 | 105 | 128 | 160 |
| Hidden Dimension | 12,288 | 20,480 | 25,600 | 32,768 |
| Attention Heads | 96 | 128 | 160 | 128 |
Table 2: Model configuration
For each of these configurations, we report peak throughput of the system using TFLOPs/GPU as the main performance metric. To calculate TFLOPs, we use the formula used by the Megatron paper as shown below.
FLOPs/GPU = 96 * B * s * l * h2 * (1 + s/6h + V/(16*l*h))
B is batch size, s is sequence length, l is the number of layers, h is hidden size, and V is vocabulary size.
Scaling the 175B and 530B models
Figures 5a and 5b show the results of 175B model with sequence length 512 and 1024, respectively. We only scale to 512 GPUs for seq-length 512 as adding more GPUs shows similar performance. On the other hand, with sequence length 1024, we saw linear performance increase to 1024 GPUs. Overall, the peak throughput of 204.49 TFLOPs/GPU was achieved on 256 GPUs with a micro batch size of 32 and sequence length of 512.
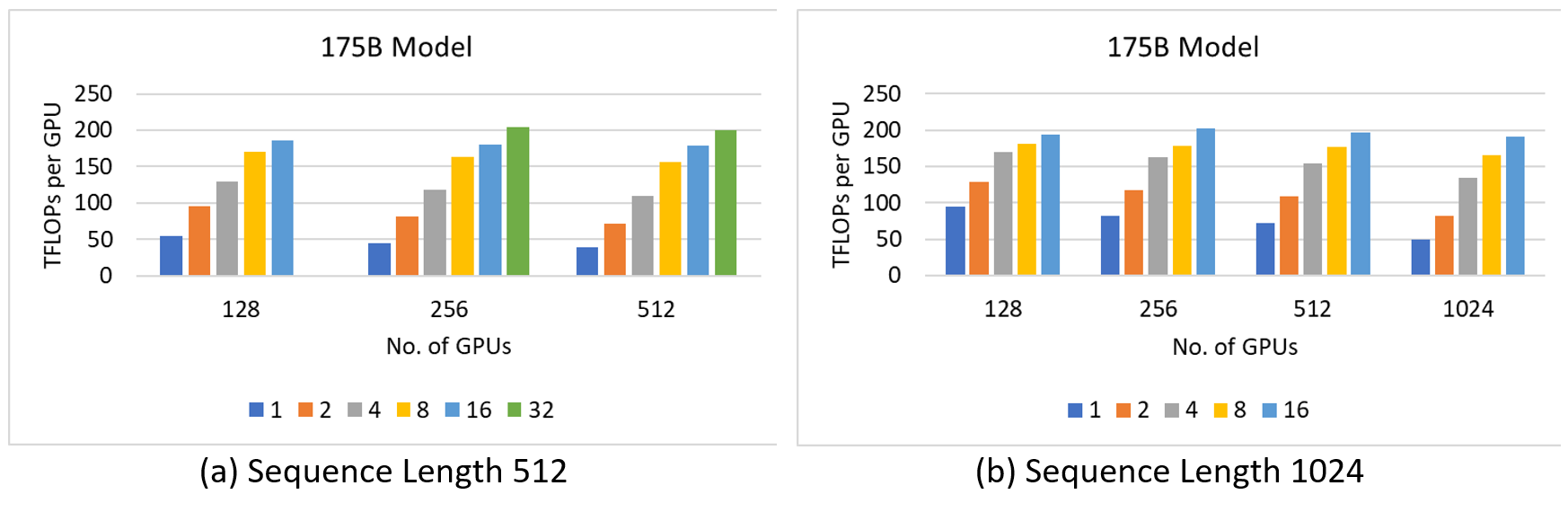
Figure 5: Performance characteristics of 175B model on 512 and 1K GPUs respectively. The colored columns signify different micro batch sizes.
Next, we report the 530B model scaling. Previous results on the 530B MT-NLG model using DeepSpeed and Megatron-LM on 280 DGX A100 servers on the Selene supercomputer showed the peak throughput of 126 TFLOPS/GPU. However, we were able to surpass that throughput and achieved up to 171.37 TFLOPs/GPU on 128 NDm A100 v4-series A100 systems (i.e., 1024 GPUs) as shown in Figure 6.
The benefit of this 530B model is its simpler parallelization configuration as there is no tensor/pipeline parallelism. With ZeRO powered data parallelism, there are fewer heuristics required to optimally configure the distributed model. In addition, the consistent steady state performance of more than 140 TFLOPs/GPU for micro batch sizes >1 demonstrates a robust software and hardware platform.
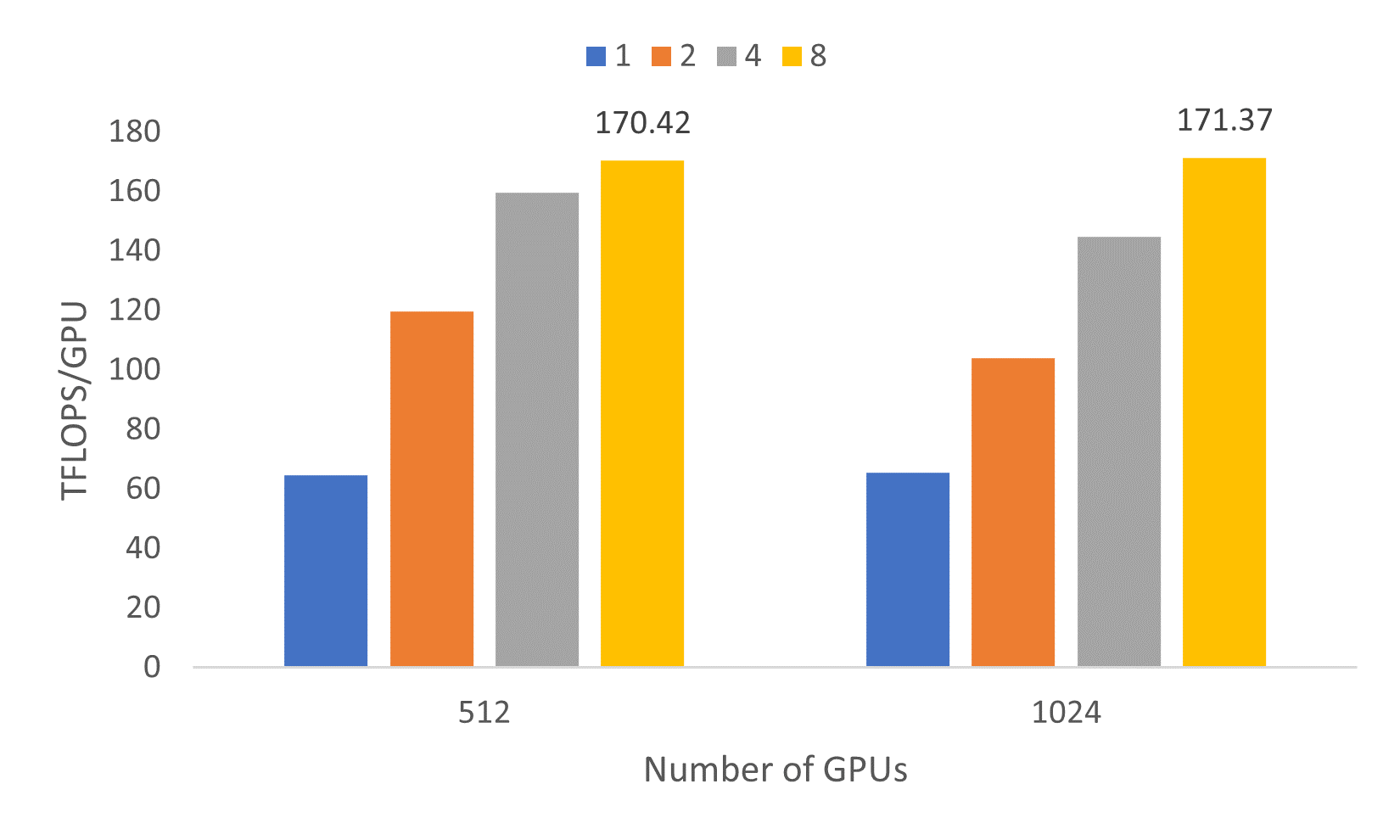
Figure 6: Throughput achieved with a 530B parameter model on 512 and 1024 GPUs for micro-batch sizes per GPU of 1, 2, 4, and 8, with sequence length 1,024.
Scaling the 1T and 2T models
The 1T parameter model contains 128 layers with 160 attention heads. Training such an extreme-scale model is not an easy task. Figure 7 shows the throughput achieved for each of the model configurations we explored on 512 and 1024 GPUs. Peak throughput achieved was 165.36 TFLOPs/GPU for micro batch size of 8 across 1024 GPUs and the model reached steady state performance within the first 3-4 iterations.
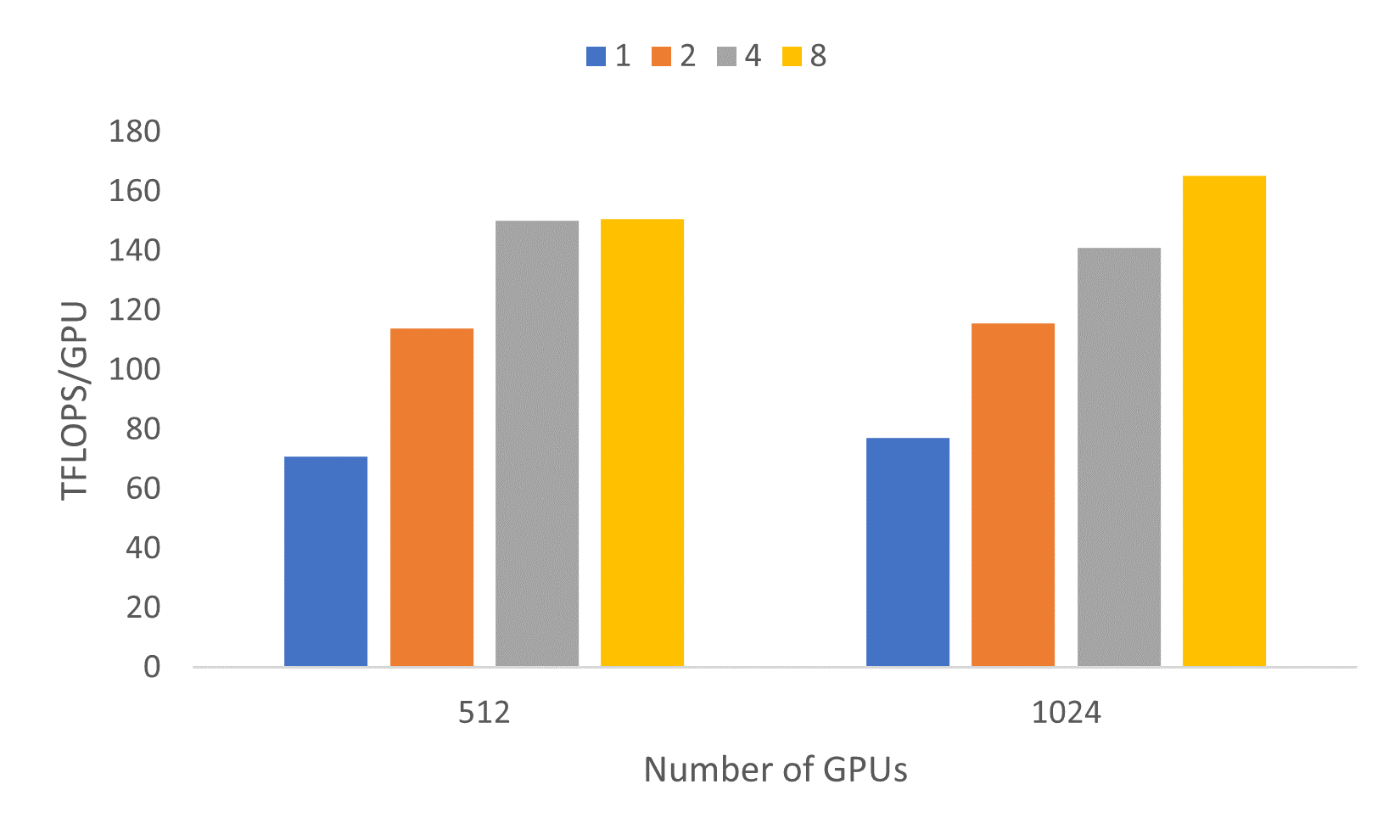
Figure 7: Performance characteristics of 1T parameter model on 512 and 1024 GPUs with 1, 2, 4, and 8 micro batch sizes, with sequence length 1,024.
The 2T parameter model consists of 160 layers, 32k hidden dimension, and 128 attention heads. Given the large size of the model and the significant time required on 1024 GPUs, we limited our benchmark runs for the 2T model to a batch size of 8 per GPU with a sequence length of 1024. We were able to achieve 157 TFLOPs/GPU on 1,024 GPUs.
How to run training experiments on Azure?
We recognize that DeepSpeed users are diverse and have different environments. In this tutorial, our focus is on making things simpler for users who plan to run large model training experiments on Azure.
The easiest way to do model training on Azure is via the Azure ML recipes. The job submission and data preparation scripts have been made available here. Users simply need to setup their Azure ML workspace following the guide and submit experiment using the aml_submit.py file.
Some users have customized environments built on top of Azure VMs and VMSS based clusters. To simplify training on such setups, we are working on an easy-to-use cluster setup script that will be published in the next few weeks. If you already have a cluster setup running, you can use the azure recipes for the 175B and the 1T model. The recipes can easily be modified to train other model configurations.
Acknowledgement
This blog post was written by the DeepSpeed team in collaboration with the AzureML and the AzureHPC team. We would like to acknowledge several individuals who made this work possible:
- AzureHPC team: Russell J. Hewett, Kushal Datta, Prabhat Ram, Jithin Jose, and Nidhi Chappell
- AzureML team: Vijay Aski, Razvan Tanase, Miseon Park, Savita Mittal, Ravi Shankar Kolli, Prasanth Pulavarthi, and Daniel Moth
- DeepSpeed team: Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Martin Cai, and Yuxiong He
- CTO office: Gopi Kumar and Luis Vargas