ZeRO-Inference: Democratizing massive model inference
Introduction
The current trends in artificial intelligence (AI) domains such as image, speech, and natural language, demonstrate that model quality can be improved by increasing model size. In natural language processing, for example, the state-of-the-art (SOTA) model has grown from 300 million parameters (Bert-Large) to 500 billion parameters (Megatron-Turing-530B) in less than four years. However, this dramatic growth in model sizes has significantly increased the GPU cost to train, finetune or inference these models, making them unaffordable to most users. To democratize access to AI innovations, large organizations, such as Hugging Face (BigScience), Meta, and Yandex have recently publicly released pre-trained massive models. Unfortunately, even these publicly available models are not broadly usable because many users cannot afford the dozens of GPUs required to fit them for inference computation. For example, half-precision inference computation on Megatron-Turing-530B (SOTA model for natural language) requires at least 40 A100-40GB GPUs, which is unaffordable to many students, model scientists, hobbyists, and small businesses that could benefit from using these powerful models. And so, a real concern is that if the dramatic increase in model sizes continues, then a growing fraction of users could be excluded from the benefits of these AI innovations.
DeepSpeed, a part of Microsoft’s AI at Scale Initiative, has developed the ZeRO-Inference technology to address these obstacles to AI democratization. ZeRO-Inference comes from the family of ZeRO technologies, which are a collection of powerful memory and parallelism optimizations for efficient large scale model training and inference on modern GPU clusters. DeepSpeed had previously developed ZeRO-Infinity, a technology that leverages heterogeneous memory (GPU, CPU, and NVMe) to efficiently scale model training to extreme levels. ZeRO-Inference adapts and optimizes ZeRO-Infinity techniques for model inference on GPUs by hosting the model weights in CPU or NVMe memory, thus hosting no (zero) weights in GPU. This approach is inspired by the observation that the aggregate capacity of CPU and NVMe memories in most commodity computing devices (e.g., laptops, desktops, workstations, etc.) is on the order of terabytes and sufficient to host the largest known models for inference computation. By leveraging this non-GPU memory, ZeRO-Inference enables inference computation of massive models (with hundreds of billions of parameters) on as few as a single GPU, thereby making massive model inference accessible to almost everyone. Moreover, by dramatically reducing GPU memory requirements with CPU or NVMe memory which are significantly cheaper, it significantly reduces the cost of massive model inference, offering an affordable inference path to SOTA models.
How ZeRO-Inference works
The massive computational requirements of large model inference means that accelerators like GPUs are required for efficient execution. Therefore, an important design decision for large model inference on limited GPU budget is how to apportion GPU memory among model weights, inference inputs, and intermediate results.
Offload all model weights
ZeRO-Inference pins the entire model weights in CPU or NVMe (whichever is sufficient to accommodate the full model) and streams the weights layer-by-layer into the GPU for inference computation. After computing a layer, the outputs are retained in GPU memory as inputs for the next layer, while memory consumed by the layer weights is released for use by the next layer. Thus, model inference time is composed of the time to compute the layers on GPU, and the time to fetch the layers over PCIe. For large model inference, this approach provides scaling and efficiency benefits, as explained below.
ZeRO-Inference offers scaling benefits in two ways. First, by keeping just one (or a few) model layers in GPU memory at any time, ZeRO-Inference significantly reduces the amount of GPU memory required to inference massive models. For current SOTA models which have about a hundred layers (e.g., 96 and 105 layers in GPT3-175B and Megatron-Turing-530B respectively), ZeRO-Inference reduces the GPU memory requirements by up to two orders of magnitude. For example, with ZeRO-Inference, GPU memory consumption of Megaton-Turing-530B for half-precision inference drops from 1TB to 10GB. Second, by fitting the model into CPU or NVMe memory which are orders of magnitude cheaper than GPU memory, ZeRO-Inference makes scaling to future SOTA models (e.g., with trillions or tens-of-trillions of parameters) more affordable compared to approaches that fit the entire model into GPU memory.
ZeRO-Inference delivers efficient computation for throughput-oriented inference applications despite the latency of fetching model weights from CPU or NVMe over PCIe interconnect. The primary reason for this is that by limiting GPU memory usage of the model to one or a few layers of weights, ZeRO-Inference can use the majority of GPU memory to support a large amount of input tokens in the form of long sequences or large batch sizes. A large model layer requires a significant amount of computation, especially when processing inputs with many input tokens. For example, one GPT3-175B layer requires about 7 TFlops to process an input of batch size 1 and sequence length of 2048. Therefore, for inference scenarios with long sequence length and large batch sizes, the computation time dominates the latency of fetching model weights, which ultimately improves efficiency. In summary, ZeRO-Inference’s strategy to utilize GPU memory to support large number of input tokens results in high performance inference for large models.
Optimizations
To further improve system efficiency, ZeRO-Inference leverages two additional optimizations to reduce the latency of fetching layer weights from CPU or NVMe memory into GPU memory.
The first optimization involves overlapping the fetch of a layer with the computation of an earlier layer, a.k.a., layer prefetching. Layer prefetching allows ZeRO-Inference to hide portions of the transfer latency of the prefetched layers. This is especially useful when computation time is not large enough or cannot be sufficiently increased (e.g., with larger batch size) to dominate the latency of fetching layer weights.
The second optimization, which is applicable for inference on multiple GPUs, involves parallelizing the fetch of each layer across multiple GPUs by using each GPU to fetch only a portion of the layer. Employing the aggregate PCIe links of the GPUs in this manner essentially increases the transfer bandwidth linearly, thus reducing the latency. With this approach, fetching layers into GPU memory occurs in two phases. First, each GPU independently fetches a partition of the layer over PCIe into its memory. At this point, only a partition of the layer will be resident on each GPU. Next, each GPU assembles the full layer for computation by fetching the missing layer pieces from other GPUs over the high-bandwidth GPU-GPU interconnect (e.g., NVLink, xGMI, etc.). Since GPU-GPU interconnect bandwidth is typically over an order of magnitude higher than PCIe bandwidth, efficient multi-GPU or multi-node communication primitives, such as NCCL or RCCL all-gather, can be used to efficiently assemble the full layer on all GPUs with negligible latency compared to the PCIe latency.
Alternative approach: Host some model weights in GPU memory
An alternative approach to ZeRO-Inference is to pin as many of the model weights as possible into GPU memory and fetch the remainder (from CPU or NVMe) when needed for computation. A benefit of this approach is avoidance of the latency of fetching weights that are already pinned in GPU memory. However, this approach has two downsides: (i) the latency savings for hundred-billion parameter models are negligible since only a small fraction of the weights can fit in GPU memory, and (ii) even when a decent portion of the model weights can fit (e.g., > 50% for ~10B models), the remaining GPU memory can only fit small batch sizes which hurts inference throughput. We later show evaluation results to demonstrate that this approach is sub-optimal.
Model Scaling on 1 GPU
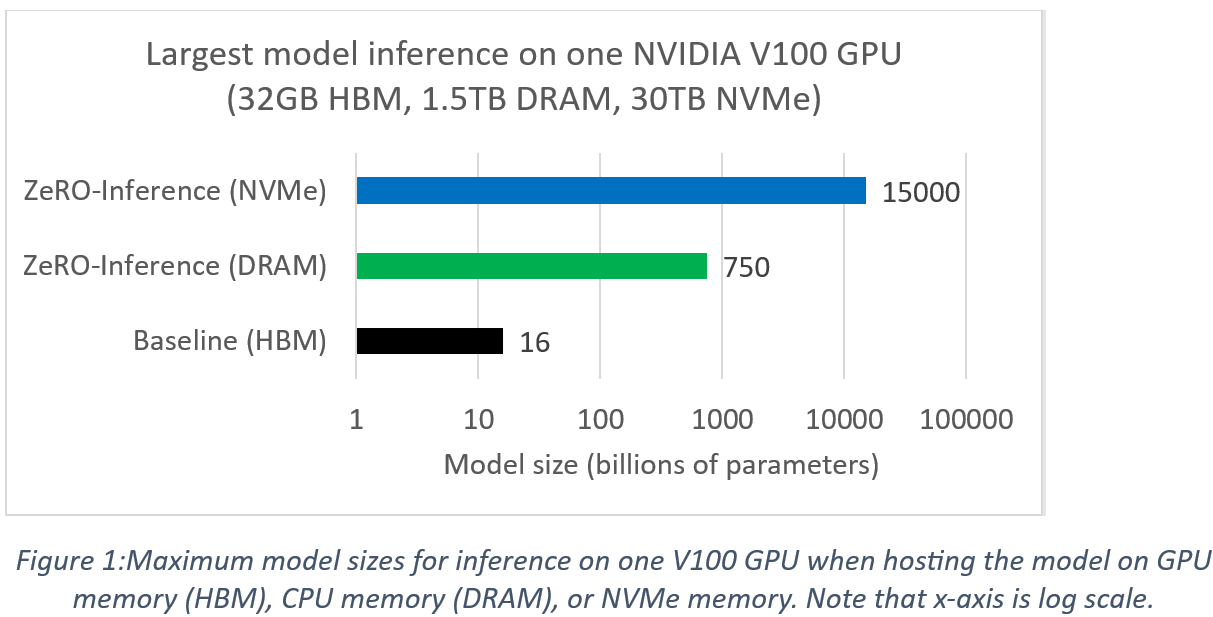
ZeRO-Inference enables significant model scaling for inference on a single GPU compared to a baseline that hosts the model in GPU memory (i.e., HBM). As an example, we consider half-precision model inference using a single NVIDIA Tesla V100 GPU in a NVIDIA DGX2 system. While the V100 GPU has 32GB of memory, the system is equipped with 1.5TB of CPU DRAM and 30TB of NVMe storage. The maximum model size supported for inference computation on GPU depends on the memory in which the model is hosted. Figure 1 below shows the achievable model scales in this system for GPU inference with ZeRO-Inference. In comparison, the baseline cannot support models larger than 16 billion parameters for GPU inference1. In contrast, ZeRO-Inference has the flexibility to host the model in a different memory (DRAM or NVMe) than HBM. This flexibility allows ZeRO-Inference to support much larger models than baseline. For example, by hosting a model on NVMe memory, Zero-Inference can support models with up to 15 trillion parameters for GPU inference, which is almost a thousand times larger compared to baseline. A practical takeaway from Figure 1 is that ZeRO-Inference enables single GPU inference computation of current SOTA models, since they are smaller than 15 trillion parameters.
Token Generation Performance
An important inference workload is token generation based on an input prompt. In this workload the model is provided a text sequence as input prompt, and based on this prompt, the model generates output text of configurable length. We use this workload to demonstrate the performance of ZeRO-Inference. This workload consists of two phases: (1) the prompt processing phase where the model processes the input prompt, and (2) the generation phase where the model generates the output tokens.
ZeRO-Inference is targeted for throughput-oriented inference applications, and so the performance metric that we use for this workload is the number of tokens generated per second in the generation phase. We use the Hugging Face token generation pipeline in our experiments to measure the performance of using a greedy search algorithm to generate ten output tokens given an input prompt of four tokens. The generation pipeline in our experiments uses KV-caching optimization to improve performance by caching generated tokens to avoid re-computation. We consider the performance impact of three aspects of ZeRO-Inference design choices and optimizations: (1) full offloading model weights as opposed to partial offloading, (2) prefetching layer weights ahead of use, and (3) using multiple GPUs to parallelize layer fetching over PCIe. Additionally, we measure the performance impact of varying the number of output tokens.
Models
For our experiments, we use the three publicly available massive language models listed in Table 1. We configure these models for half-precision inference computations. ZeRO-Inference is required to inference these models on a single V100-32GB since they are bigger than GPU memory.

Full Offload vs. Partial Offload of model weights
A key design choice in ZeRO-Offload is to offload all the weights of models larger than GPU memory rather than host a subset of the weights in GPU memory. Our intuition for this approach is that for throughput-oriented inference applications, the larger batch sizes enabled by full offload yields better performance than partial offload. In Table 2, we present results for OPT-30B token generation on a single V100-32GB that compare fully offloading the model weights versus hosting a portion (i.e., 10 and 12 billion parameters2) in GPU memory. The results show that full offload delivers the best performance for both CPU memory (43 tokens per second) and NVMe memory (30 tokens per second). With both CPU and NVMe memory, full offload is over 1.3x and 2.4x faster than partial offload of 18 and 20 billion parameters respectively. The performance advantage of full offload comes from the larger batch sizes compared to the partial offload options. Thus when a model does not fit in GPU, using GPU memory to increase batch size rather than to partially fit the model leads to faster token generation.

Prefetching layer weights
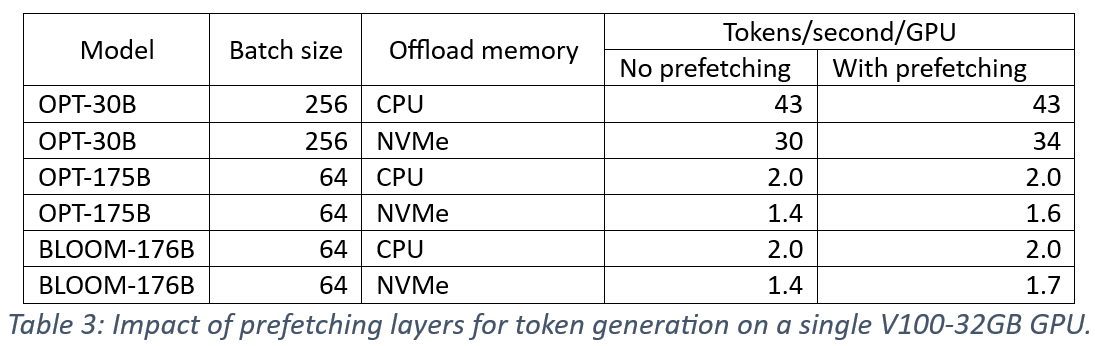
ZeRO-Inference fetches layers ahead of use, overlapping with current layer computation, to hide layer transfer latency. We measure the impact of prefetching on token generation performance on a single V100-32GB and summarize the results in Table 3. We observe that prefetching did not improve CPU offload. This is because the relatively short sequences in token generation (i.e., less than 50 tokens) resulted in layer computation time that is insufficient to hide a significant portion of layer fetch time from CPU. In contrast, prefetching improves NVMe offloading performance by 1.13x, 1.14x and 1.21x for OPT-30B, OPT-175B, and BLOOM-176B respectively. This is because transferring weights from NVMe through CPU memory allows prefetching to overlap transfers from CPU to GPU memory with transfers from NVMe to CPU boosting the effective transfer bandwidth.
Parallelizing layer fetching on multiple GPUs
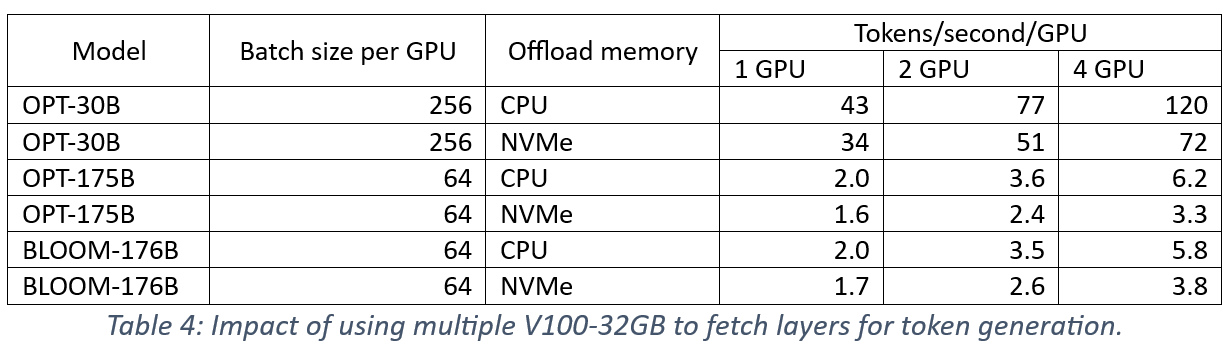
ZeRO-Inference leverages the four PCIe interconnects between GPUs and CPU memory to parallelize layer fetching for faster inference computations on multiple GPUs. In Table 4, we report the throughput improvements for token generation on two and four GPUs compared to a single GPU3 . These results were collected with layer prefetching enabled. The reported throughput numbers are per GPU showing that token generation becomes faster on each GPU as the aggregated PCIe links reduce the layer fetch latencies. The improved per GPU throughput translates to super-linear scaling performance. Additionally, these results suggest improved bandwidths of future PCIe generations could help to improve ZeRO-Inference performance.
Impact of generation output length
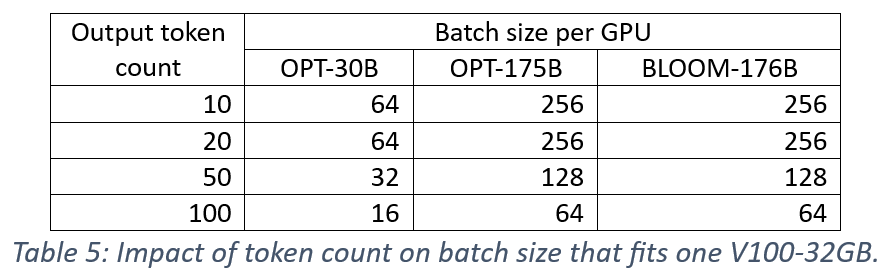
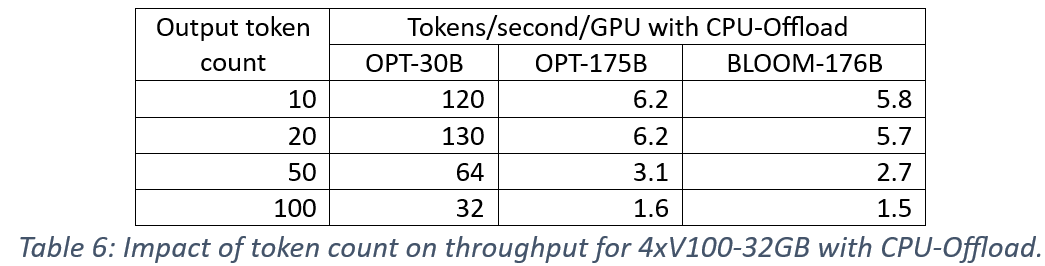
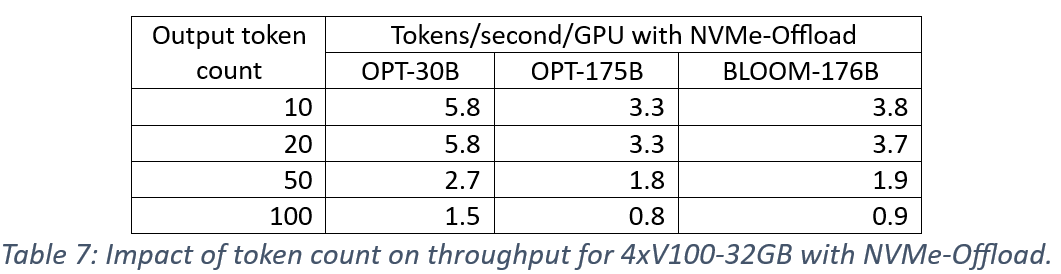
We measure the performance impact of the number of output tokens since the memory overhead of KV-caching optimization increases with longer output tokens and could limit batch size. First, we consider the impact of token lengths 10, 20, 50, and 100 on batch size that can fit one V100-32GB GPU. The results in Table 5 show a 2X reduction in batch size for a 5X increase in token count (compared to baseline count of 10).
Next, we measure the impact on generation throughput using four V100-32GB GPUs. The results are presented in Table 6 for CPU offload, and Table 7 for NVMe-Offload. We observe an impact that is consistent across models and offload memory, which is that increasing the number of output tokens reduces throughput proportionally to batch size reduction. These results also demonstrate the importance of large batch sizes to the performance of ZeRO-Inference.
Using ZeRO-Inference
We briefly discuss how users can determine when ZeRO-Inference is suitable for their application and how to enable ZeRO-Inference in DeepSpeed.
When to use ZeRO-Inference
ZeRO-Inference is designed for inference applications that require GPU acceleration but lack sufficient GPU memory to host the model. Also, ZeRO-Inference is optimized for inference applications that are throughput-oriented and allow large batch sizes. Alternative techniques, such as Accelerate, DeepSpeed-Inference, and DeepSpeed-MII that fit the entire model into GPU memory, possibly using multiple GPUs, are more suitable for inference applications that are latency sensitive or have small batch sizes.
How to use ZeRO-Inference
ZeRO-Inference is available in the DeepSpeed library versions >= 0.6.6. Integrating ZeRO-Inference into token generation pipelines, such as Hugging Face generate, requires updating the DeepSpeed configuration to set ZeRO optimization to stage 3 and parameter offloading to CPU or NVMe.
Below is a configuration snippet for enabling ZeRO-Inference with offloading to CPU memory.
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
...
},
...
}
Below is a configuration snippet for offloading to a NVMe device mounted on “/local_nvme”.
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme",
...
},
...
}
Conclusion
Recent advances in AI technology have primarily come from extreme scaling of model sizes. However, extreme model scaling has also made the hardware cost of training and inferencing prohibitive for all but the largest organizations, severely restricting access to AI innovations. To help democratize AI, we developed ZeRO-Inference, a technology that enables inference computations of massive models on as few as a single GPU. ZeRO-Inference reduces the GPU cost of SOTA model inference by hosting the model on CPU or NVMe memory and streaming the model layers into GPU memory for inference computation. ZeRO-Inference complements the democratization efforts of large organizations that publicly release pre-trained SOTA models by ensuring that inference computation of these models is affordable for most users (e.g., students, hobbyists, model scientists, etc.).
Acknowledgement
The DeepSpeed team would like to acknowledge Stas Bekman for previewing this blog and providing valuable feedback.
-
16 billion parameters model won’t fit in V100-32GB for half-precision inference since no memory will be left for inputs and intermediate results. ↩
-
Pinning more parameters in GPU memory resulted in out of memory errors for small batch sizes. ↩
-
For multiple GPU runs, we select GPUs with independent PCIe interconnects to CPU memory. ↩