DeepSpeed-MII: instant speedup on 24,000+ open-source DL models with up to 40x cheaper inference
The Deep Learning (DL) open-source community has seen tremendous growth in the last few months. Incredibly powerful text generation models such as the Bloom 176B, or image generation models such as Stable Diffusion are now available to anyone with access to a handful or even a single GPU through platforms such as Hugging Face. While open-sourcing has democratized access to AI capabilities, their application is still restricted by two critical factors: 1) inference latency and 2) cost.
There has been significant progress in system optimizations for DL model inference that can drastically reduce both latency and cost, but those are not easily accessible. The main reason for this limited accessibility is that the DL model inference landscape is diverse with models varying in size, architecture, system performance characteristics, hardware requirements, etc. Identifying the appropriate set of system optimizations applicable to a given model and applying them correctly is often beyond the scope of most data scientists, making low latency and low-cost inference mostly inaccessible.
DeepSpeed Model Implementations for Inference (MII) is a new open-source python library from DeepSpeed, aimed towards making low-latency, low-cost inference of powerful models not only feasible but also easily accessible.
- MII offers access to highly optimized implementations of thousands of widely used DL models.
- MII supported models achieve significantly lower latency and cost compared to their original implementation.
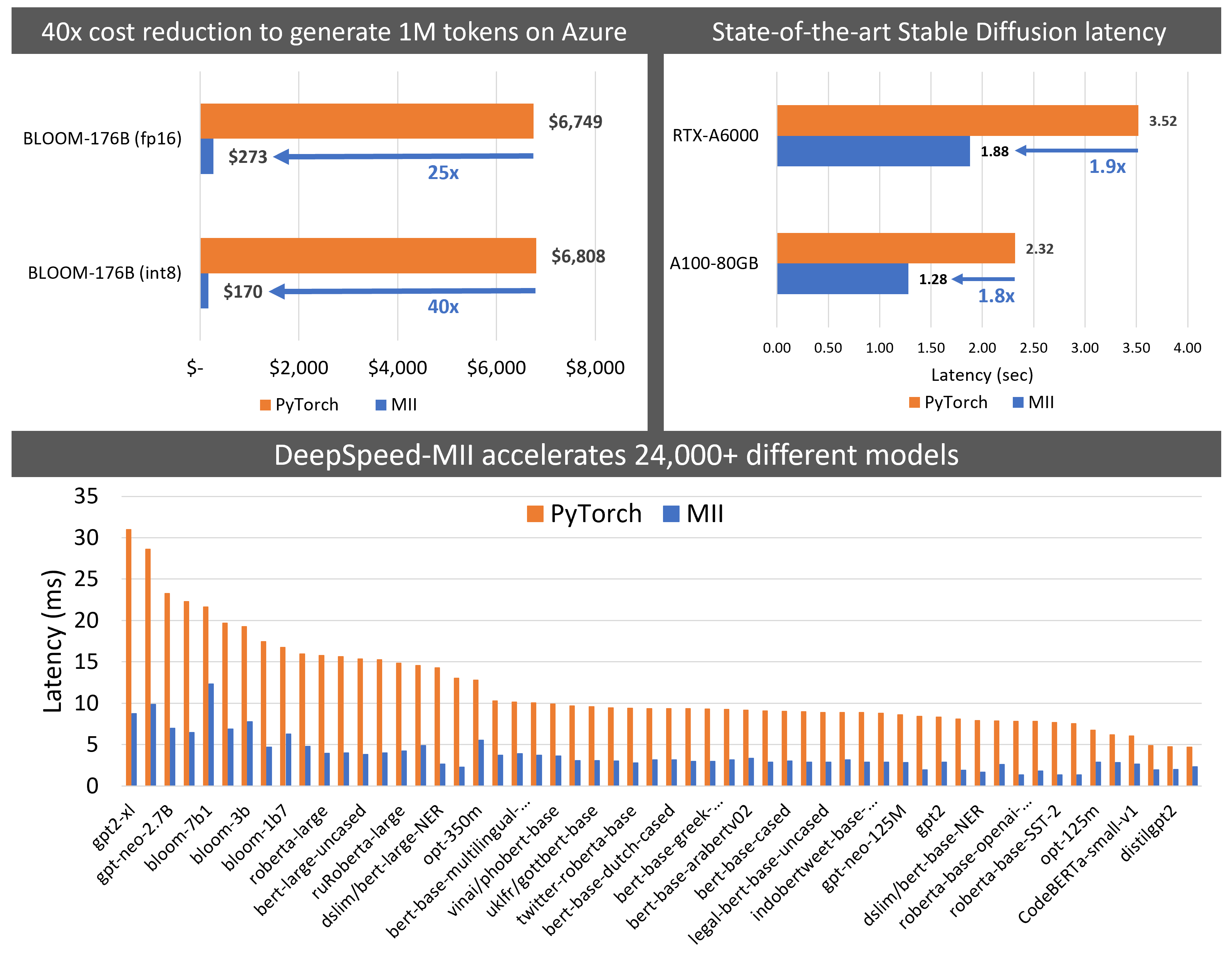
- MII reduces the latency of Big-Science Bloom 176B model by 5.7x, while reducing the cost by over 40x as shown in Figures 2 (left) and 8.
- MII reduces the latency and cost of deploying Stable Diffusion by 1.9x as shown in Figure 2 (right).
- To enable low latency/cost inference, MII leverages an extensive set of optimizations from DeepSpeed-Inference such as deepfusion for transformers, automated tensor-slicing for multi-GPU inference, on-the-fly quantization with ZeroQuant, and several others (see below for more details).
- With state-of-the-art performance, MII supports low-cost deployment of these models both on-premises and on Azure via AML with just a few lines of codes.
How does MII work?
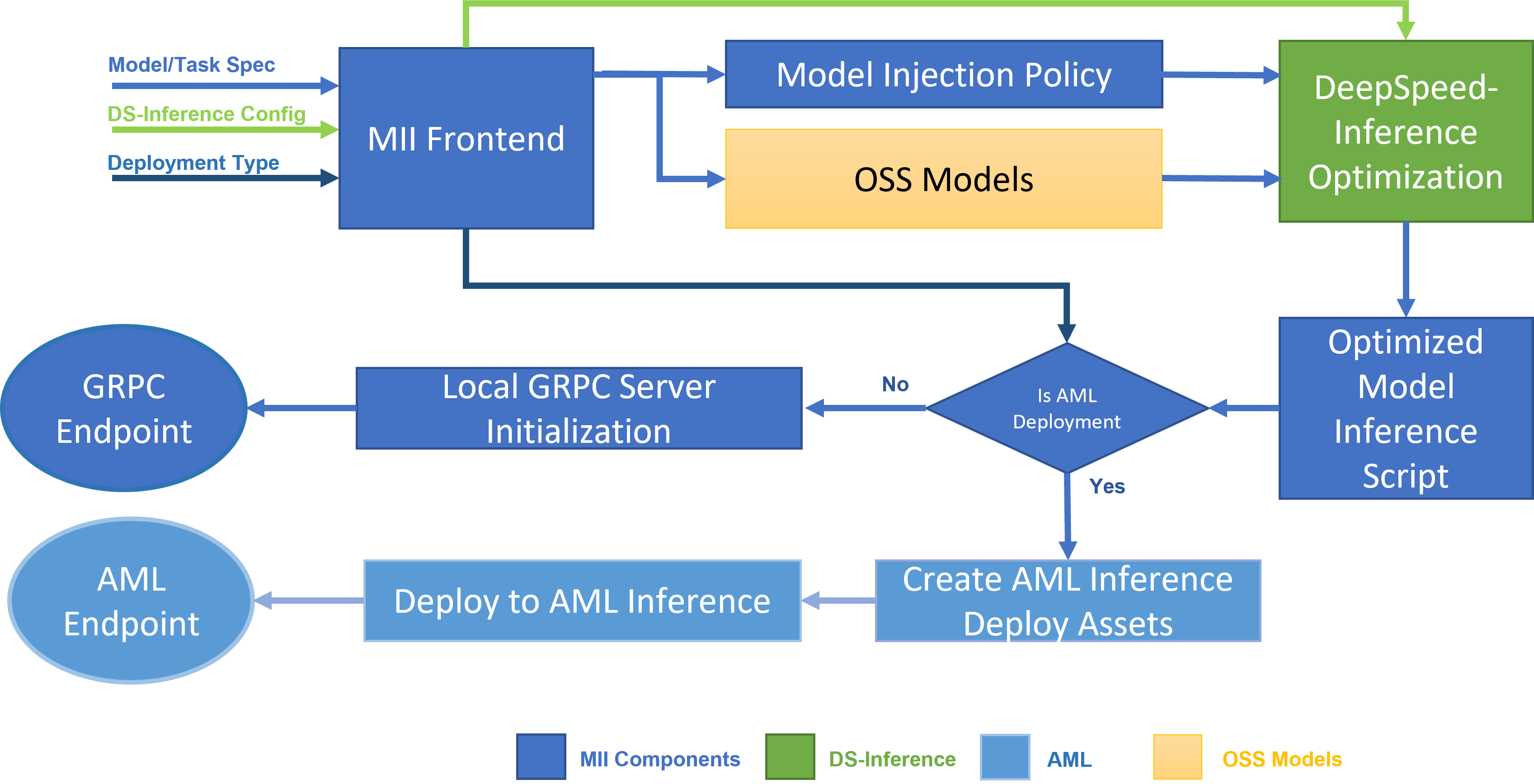
Figure 1: MII Architecture, showing how MII automatically optimizes OSS models using DS-Inference before deploying them on-premises using GRPC, or on Microsoft Azure using AML Inference.
Under-the-hood MII is powered by DeepSpeed-Inference. Based on the model type, model size, batch size, and available hardware resources, MII automatically applies the appropriate set of system optimizations from DeepSpeed-Inference to minimize latency and maximize throughput. It does so by using one of many pre-specified model injection policies, that allows MII and DeepSpeed-Inference to identify the underlying PyTorch model architecture and replace it with an optimized implementation (see Figure 1). In doing so, MII makes the expansive set of optimizations in DeepSpeed-Inference automatically available for thousands of popular models that it supports.
Supported Models and Tasks
MII supports a growing list of tasks such as text generation, question-answering, text classification, etc, across thousands of transformer models available through multiple open-sourced model repositories such as Hugging Face, FairSeq, EluetherAI, etc. It supports dense models based on BERT, RoBERTa, GPT, OPT, and BLOOM architectures ranging from a few hundred million parameters in size to hundreds of billions of parameters in size. At the same time, it supports recent image generation models such as Stable Diffusion.
See the MII GitHub repo for an up-to-date list of models and tasks supported by MII.
Inference Optimizations with MII
Here we provide a summary of the expansive set of optimizations from DeepSpeed-inference made available via MII. For more details, please refer to [1, 2]:
DeepFusion for Transformers: For transformer-based models such as Bert, Roberta, GPT-2, and GPT-J, MII leverages the transformer kernels in DeepSpeed-Inference that are optimized to achieve low latency at small batch sizes and high throughput at large batch sizes using DeepFusion.
Multi-GPU Inference with Tensor-Slicing: For massive models such as Bloom 176B, MII automatically enables tensor-parallelism within a node to leverage aggregate memory bandwidth and compute across multiple GPUs to achieve the lowest latency and throughput compared to anything else that is currently available.
INT8 Inference with ZeroQuant: For massive models with tens or hundreds of billions of parameters, MII supports INT8 Inference with ZeroQuant. Using this feature not only reduces the memory footprint and the number of GPUs required for inference but also increases the inference throughput by supporting larger batch sizes and using INT8 compute, thus lowering cost compared to FP16.
ZeRO-Inference for Resource Constrained Systems: Models such as Bloom 176B, require over 176 GB of memory to just fit the model even with INT8 support. In the absence of the aggregate GPU memory across multiple GPUs required to deploy such models, MII enables ZeRO-Inference that can leverage the system CPU memory to deploy these massive models with a single GPU with limited memory.
Compiler Optimizations: When applicable, MII automatically applies compiler-based optimizations via TorchScript, nvFuser, and CUDA graph, in addition to the above optimizations, to further lower latency and improve throughput.
MII-Public and MII-Azure
MII can work with two variations of DeepSpeed-Inference. The first, referred to as ds-public, contains most of the optimizations discussed above and is also available via our open-source DeepSpeed library. The second referred to as ds-azure, offers tighter integration with Azure, and is available via MII to all Microsoft Azure customers. We refer to MII running the two DeepSpeed-Inference variants as MII-Public and MII-Azure, respectively.
Both MII-Public and MII-Azure offer significant latency and cost reduction compared to open-sourced PyTorch implementation (Baseline). However for certain generative workloads, they can have differentiated performance: MII-Azure provides further improvements beyond MII-Public. We quantify the latency and cost reduction for both variations in the next section.
Quantifying Latency and Cost Reduction
Inference workloads can be either latency critical, where the primary objective is to minimize latency, or cost sensitive, where the primary objective is to minimize cost. In this section, we quantify the benefits of using MII for both latency-critical and cost-sensitive scenarios.
Latency Critical Scenarios
For latency-critical scenarios, where a small batch size of 1 is often used, MII can reduce the latency by up to 6x for a wide range of open-source models, across multiple tasks. More specifically, we show model latency reduction of 1:
-
Up to 5.7x for multi-GPU inference for text generation using massive models such as Big Science Bloom, Facebook OPT, and EluetherAI NeoX (Figure 2 (left))
-
Up to 1.9x for image generation tasks model using Stable Diffusion (Figure 2 (right))
-
Up to 3x for relatively smaller text generation models (up to 7B parameters) based on OPT, BLOOM, and GPT architectures, running on a single GPU (Figures 3 and 4)
-
Up to 9x for various text representation tasks like fill-mask, text classification, question answering, and token classification using RoBERTa- and BERT- based models (Figures 5 and 6).
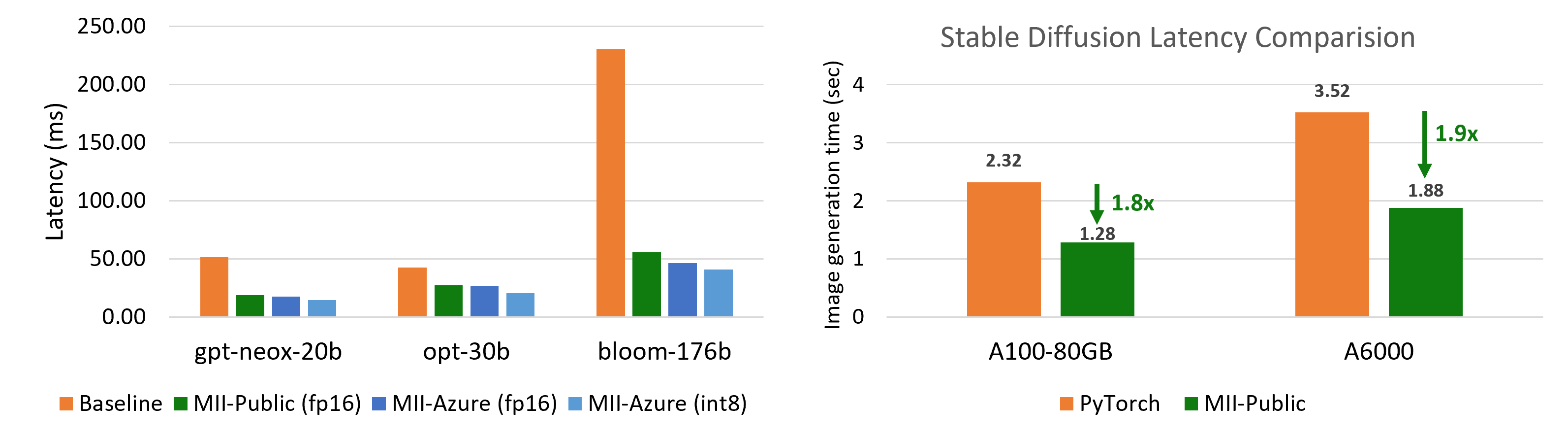 Figure 2: (left) Best achievable latency for large models. MII-Azure (int8) offers 5.7X lower latency compared to Baseline for Bloom-176B. (right) Stable Diffusion text to image generation latency comparison.
Figure 2: (left) Best achievable latency for large models. MII-Azure (int8) offers 5.7X lower latency compared to Baseline for Bloom-176B. (right) Stable Diffusion text to image generation latency comparison.
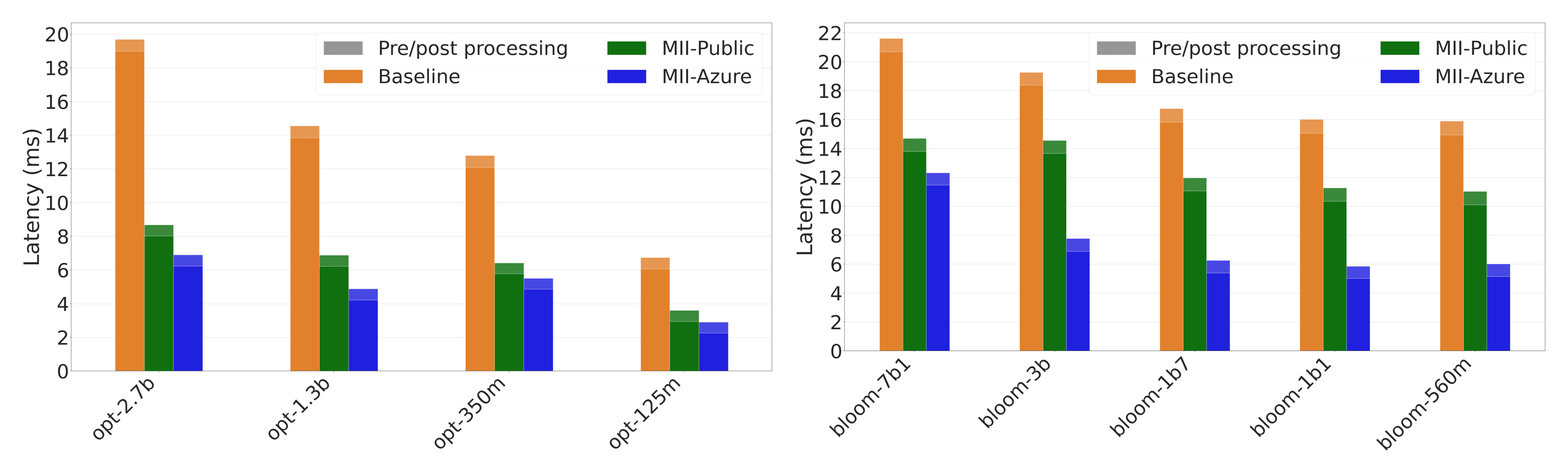 Figure 3: Latency comparison for OPT and BLOOM models. MII-Azure is up to 2.8x faster than baseline.
Figure 3: Latency comparison for OPT and BLOOM models. MII-Azure is up to 2.8x faster than baseline.
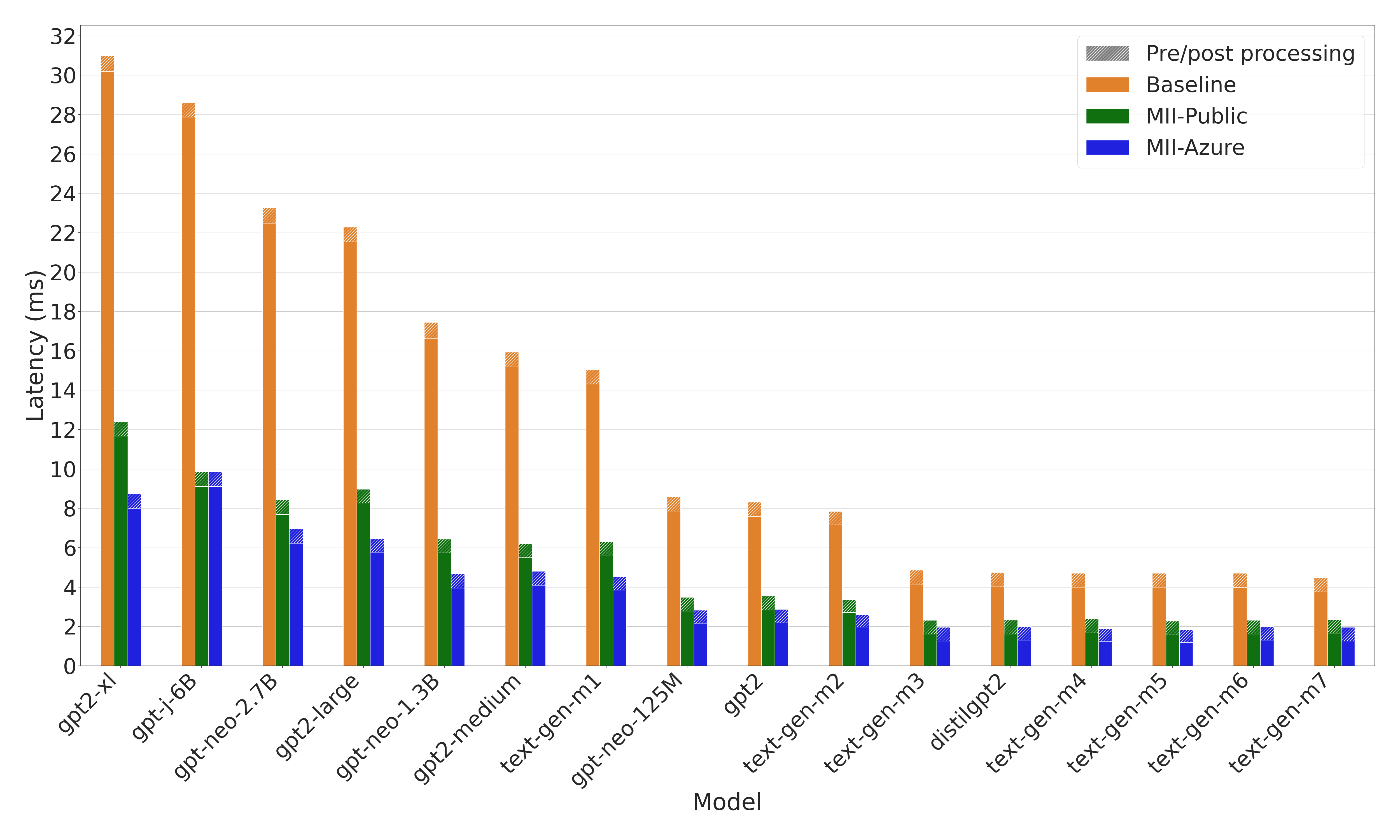 Figure 4: Latency comparison for GPT models. MII-Azure is up to 3x faster than baseline.
Figure 4: Latency comparison for GPT models. MII-Azure is up to 3x faster than baseline.
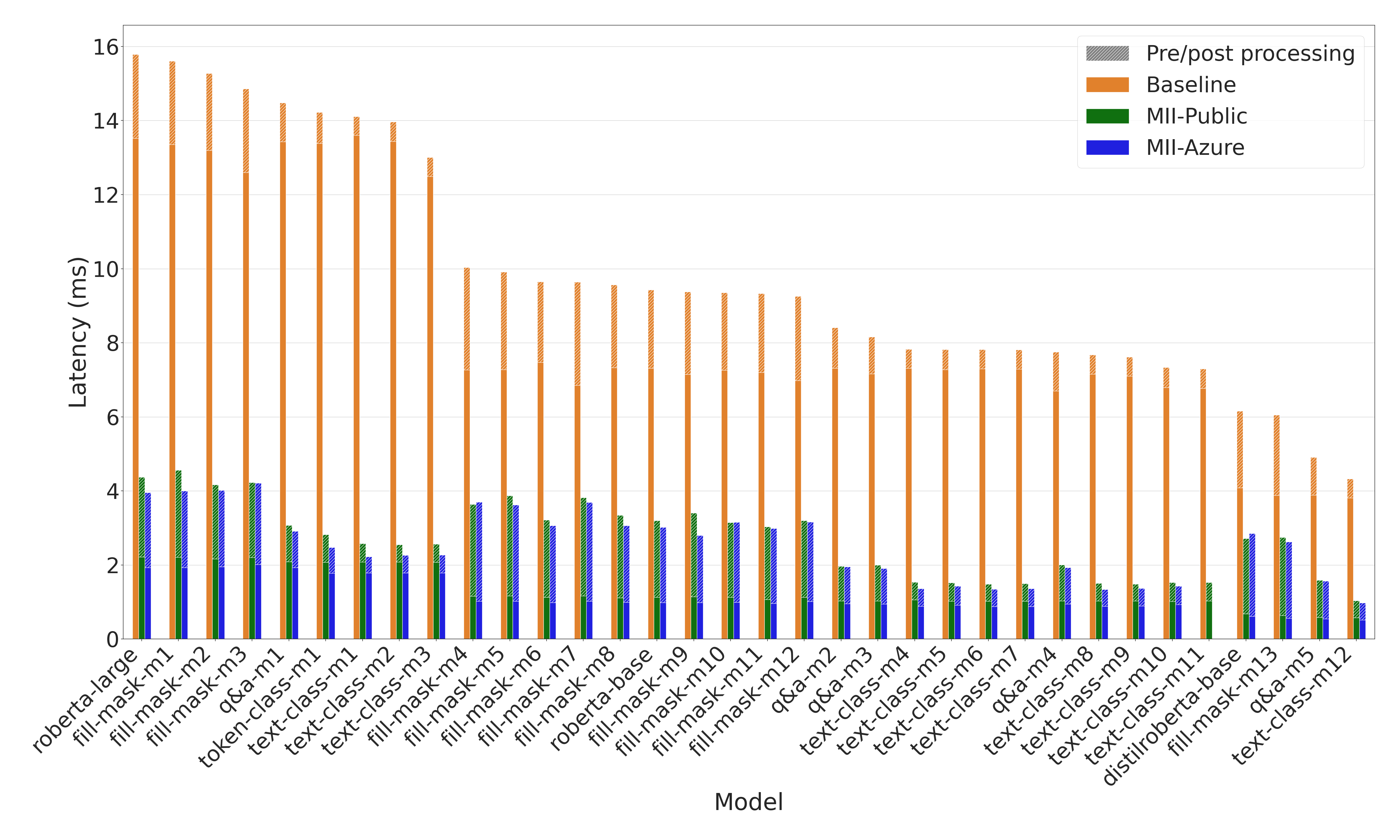 Figure 5: Latency comparison for RoBERTa models. MII offers up to 9x lower model latency and up to 3x lower end-to-end latency than baseline on several tasks and RoBERTa variants 1.
Figure 5: Latency comparison for RoBERTa models. MII offers up to 9x lower model latency and up to 3x lower end-to-end latency than baseline on several tasks and RoBERTa variants 1.
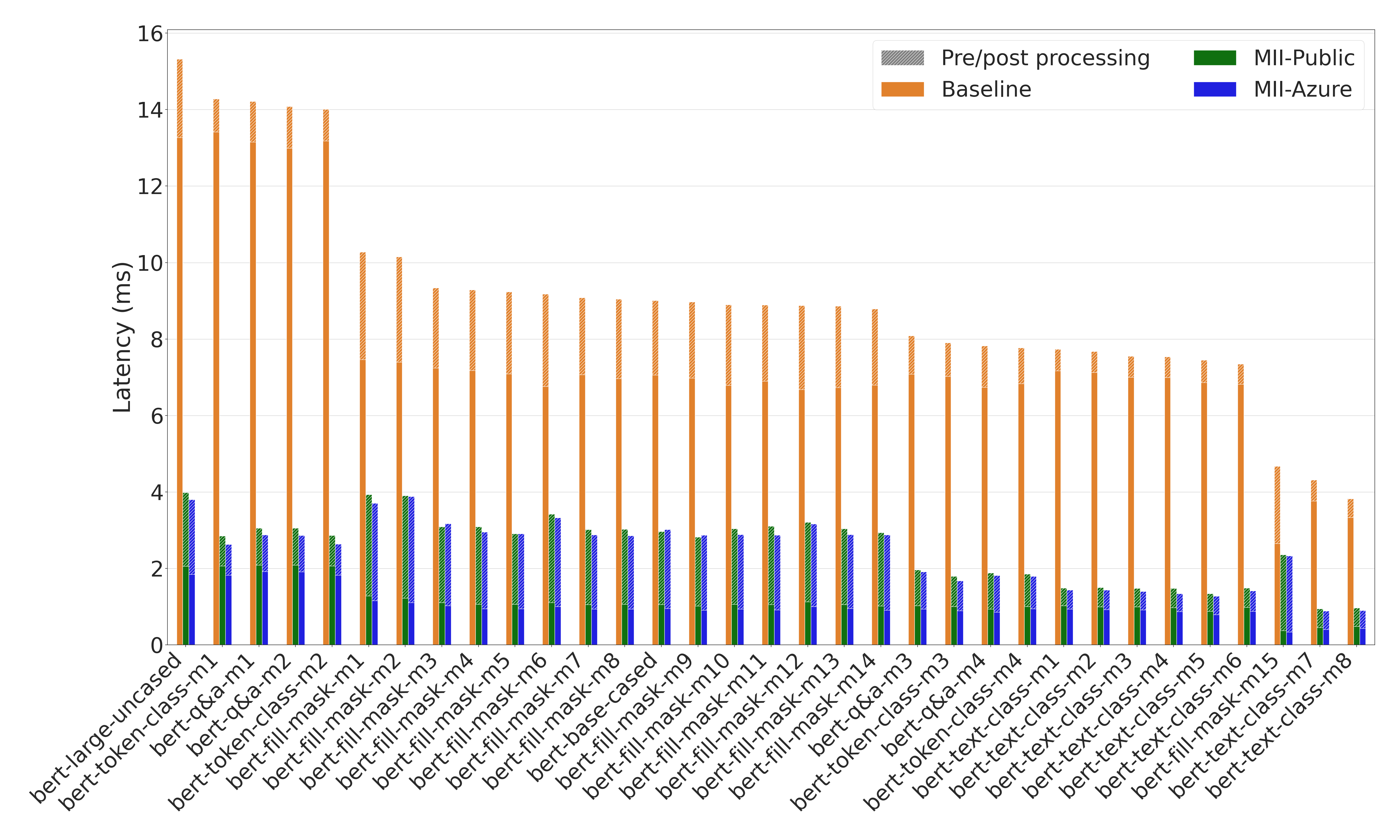 Figure 6: Latency comparison for BERT models. MII offers up to 8.9x lower model latency and up to 4.5x end-to-end latency across several tasks and BERT variants1.
Figure 6: Latency comparison for BERT models. MII offers up to 8.9x lower model latency and up to 4.5x end-to-end latency across several tasks and BERT variants1.
Cost Sensitive Scenarios
MII can significantly reduce the inference cost of very expensive language models like Bloom, OPT, etc. To get the lowest cost, we use a large batch size that maximizes throughput for both baseline and MII. Here we look at the cost reduction from MII using two different metrics: i) tokens generated per second per GPU, and ii) dollars per million tokens generated.
Figures 7 and 8 show that MII-Public offers over 10x throughput improvement and cost reduction compared to the baseline, respectively. Furthermore, MII-Azure offers over 30x improvement in throughput and cost compared to the baseline.
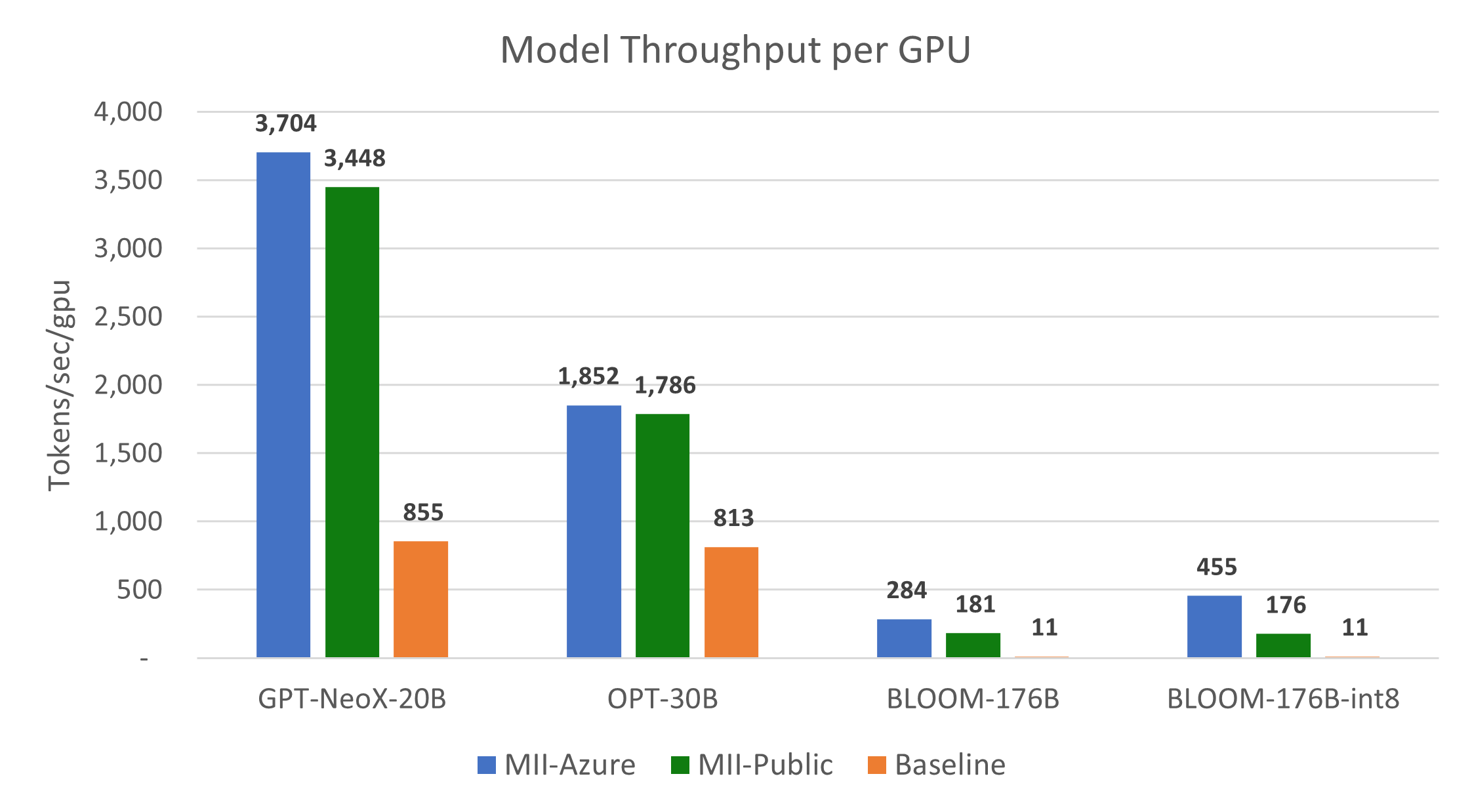 Figure 7: Throughput comparison per A100-80GB GPU for large models. MII-Public offers over 15x throughput improvement while MII-Azure offers over 40x throughput improvement.
Figure 7: Throughput comparison per A100-80GB GPU for large models. MII-Public offers over 15x throughput improvement while MII-Azure offers over 40x throughput improvement.
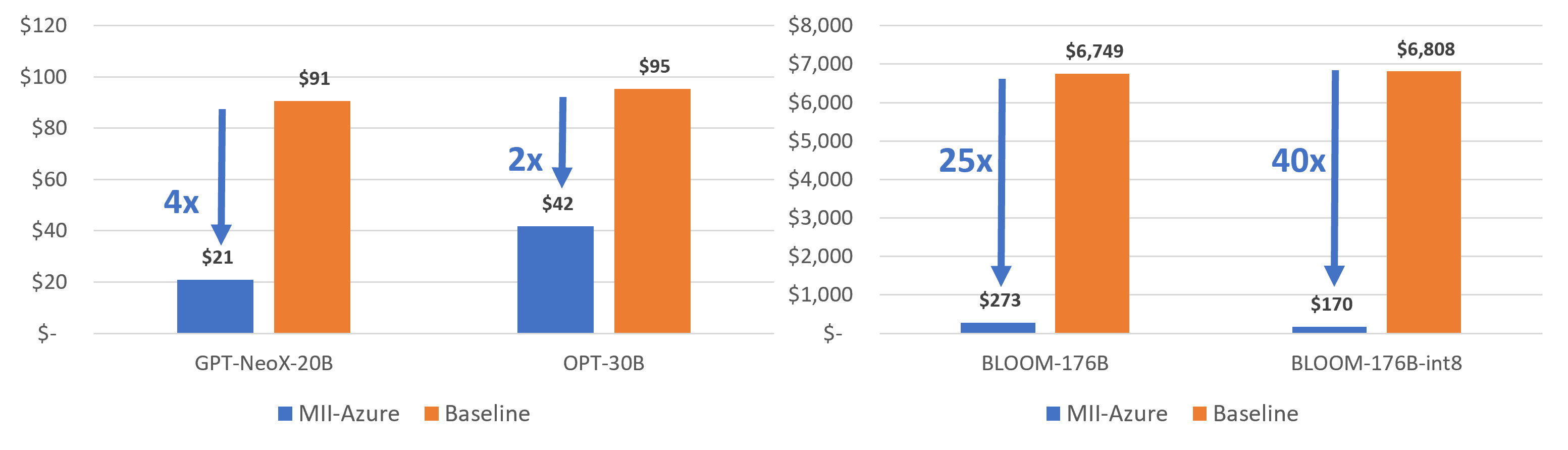 Figure 8: Cost of generating 1 million tokens on Azure with different model types. MII-Azure reduces the cost of generation by over 40x.
Figure 8: Cost of generating 1 million tokens on Azure with different model types. MII-Azure reduces the cost of generation by over 40x.
Deployment Options
MII supported models can be deployed in two different ways as shown in Figure 1 with just a few lines of code.
MII-Public Deployment
MII-Public can be deployed on-premises or on any cloud offering. MII creates a lightweight GRPC server to support this form of deployment and provides a GRPC inference endpoint for queries. The code below shows how a supported model can be deployed with MII-Public Deployment.
import mii
mii.deploy(task="text-to-image",
model="CompVis/stable-diffusion-v1-4",
deployment_name="sd-deployment")
MII-Azure Deployment
MII supports deployment on Azure via AML Inference. To enable this, MII generates AML deployment assets for a given model that can be deployed using the Azure-CLI, as shown in the code below. Furthermore, deploying on Azure, allows MII to leverage DeepSpeed-Azure as its optimization backend, which offers better latency and cost reduction than DeepSpeed-Public.
import mii
mii.deploy(task="text-to-image",
model="CompVis/stable-diffusion-v1-4",
deployment_name="sd-deployment",
deployment_type=DeploymentType.AML)
To learn more about these deployment options and get started with MII, please the MII getting started guide.
Concluding Remarks
We are very excited to share MII with the community and improve it with your feedback. We will continue to add support for more models in MII as well as enhance both MII-Public and MII-Azure for both on-premise and Azure users. Our hope is that while open sourcing has made powerful AI capabilities accessible to many, MII will allow for a wider infusion of these capabilities into a diverse set of applications and product offerings by instantly reducing the latency and cost of inferencing.
Appendix
The table below shows the mapping between model aliases used in Figures 3, 4, 5, and 6 and real model names.
-
The end-to-end latency of an inference workload is comprised of two components: i) actual model execution, and ii) pre-/post-processing before and after the model execution. MII optimizes the actual model execution but leaves the pre-/post-processing pipeline for future optimizations. We notice that text representation tasks have significant pre-/post-processing overhead (Figures G and H). We plan to address those in a future update. ↩ ↩2 ↩3