DeepSpeed Data Efficiency: A composable library that makes better use of data, increases training efficiency, and improves model quality
Recently, large-scale deep learning models are empowering us to achieve more in many ways, such as improving programming efficiency by code generation and providing art inspiration by text-to-image generation. To enable these services and keep improving the quality, deep learning model architecture evolves rapidly, and the model size is also growing at a tremendous speed. For example, from GPT to GPT-3 the model size increased 1500x in 2 years. The increasing model size leads to unprecedented training cost, making it challenging for many AI practitioners to train their own models. On the other hand, a less-emphasized perspective is that data scale is actually increasing at a similar speed as model scale, and the training cost is proportional to both of them. In Figure 1 below we plot the model and data scales of several representative language models in the last 5 years. From the oldest model on the left to the newest models on the right, both the model and data scales increase at similar speed. This demonstrates the importance of improving data efficiency: achieve same model quality with less data and reduced training cost, or achieve better model quality with the same amount of data and similar training cost.
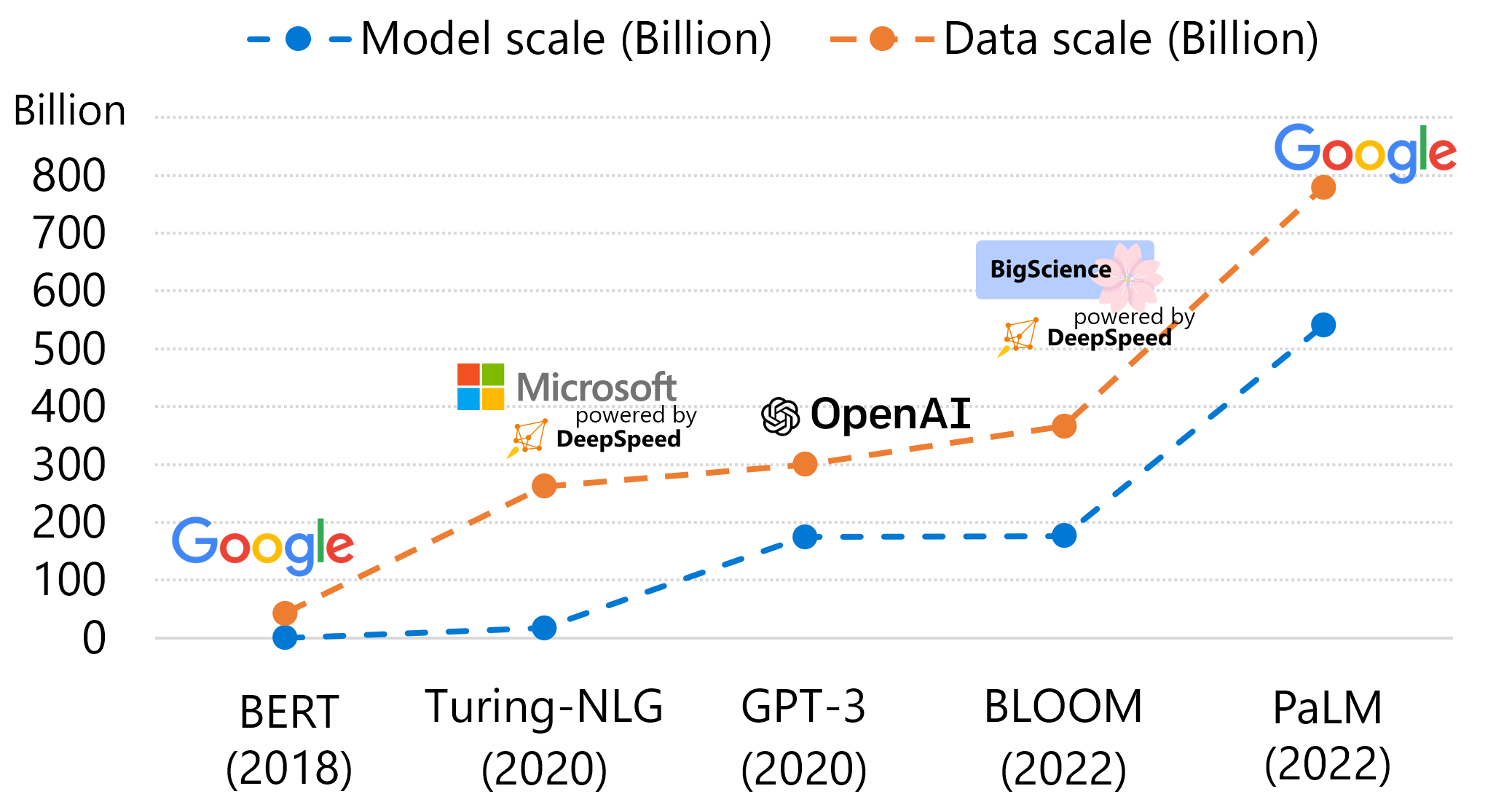
Figure 1: Model scale (number of parameters) and data scale (number of tokens consumed during training) of representative language models in the last 5 years.
There are two popular research directions among existing data efficiency techniques: Data sampling techniques aim to improve the convergence speed by sampling the most suitable next data batch from the whole data pool; Data routing techniques aim to reduce the computation by routing each data to only a subset of the model components. These techniques improve data and training efficiency, but existing solutions on them have limitations on extensibility, flexibility, and composability. They are commonly designed for specific training tasks, making them hard to be extended with customized strategies and making them less flexible to be applied on diverse workloads from different users. Furthermore, different techniques are implemented separately, making it challenging to compose multiple solutions to further improve data and training efficiency.
To address these challenges, we, the DeepSpeed team as part of Microsoft’s AI at Scale initiative, are proud to announce DeepSpeed Data Efficiency Library – a composable framework that makes better use of data, increases training efficiency, and improves model quality. DeepSpeed Data Efficiency takes extensibility, flexibility, and composability into consideration, and it specifically demonstrates the following innovations:
Efficient data sampling via curriculum learning. Curriculum learning (CL) improves data efficiency by sampling from easier data. We present a general curriculum learning library which enables users to employ curriculum learning to their models at maximum extensibility: users can easily analyze, index, and sample their training data based on various customizable strategies. Using this library, we were able to explore different CL strategies for GPT-3 and BERT pretraining and identify the best solution that provides up to 1.5x data saving while still maintaining similar model quality.
Efficient data routing via random layerwise token dropping. We present a novel data routing technique called random layerwise token dropping (random-LTD) to skip the computation of a subset of the input tokens at all middle layers. Random-LTD employs a simple yet effective routing strategy and requires minimal model architecture change. It is flexible to apply random-LTD to various tasks (GPT-3/BERT pretraining and GPT/ViT finetuning), and we achieve great data efficiency improvement (up to 1.5x data saving while still maintaining the model quality).
Seamlessly composing multiple methods. The proposed DeepSpeed Data Efficiency framework seamlessly composes the curriculum learning and random-LTD techniques, and only requires minimal changes on the user code side. Furthermore, by composing both methods we can achieve even better data and training efficiency: for GPT-3 1.3B pretraining, we achieve 2x data and 2x time savings together with better or similar model quality compared to the baseline training. When using the same amount of data, our approach further improves the model quality over the baseline. Users can also extend and contribute to the library by adding additional data efficiency techniques to compose together.
Each of these advances is explored further in the blog post below. For more about the technical details, please read our papers, “Random-LTD: Random and Layerwise Token Dropping Brings Efficient Training for Large-scale Transformers” which describes the random-LTD technique, and “DeepSpeed Data Efficiency: Improving Deep Learning Model Quality and Training Efficiency via Efficient Data Sampling and Routing” which describes the curriculum learning technique and overall DeepSpeed Data Efficiency framework.
Efficient Data Sampling via Curriculum Learning
Motivation
Curriculum learning aims to improve training convergence speed by presenting relatively easier or simpler examples earlier during training. Building a curriculum learning solution usually requires two components: the difficulty metric (i.e., how to quantify the difficulty of each data sample) and the pacing function (i.e., how to decide the curriculum difficulty range when sampling next training data batch). Curriculum learning has been successfully applied to various training tasks, and last year we also released a specific curriculum learning technique (sequence length warmup) for GPT-style model pretraining (see technical details in our paper “The Stability-Efficiency Dilemma: Investigating Sequence Length Warmup for Training GPT Models” published in NeurIPS 2022). However, one common limitation among existing works is that there does not exist a generalized and extensible curriculum learning library, which allows practitioners to easily apply custom curriculum difficulty metrics, the combination of metrics, and pacing functions.
Design
To solve the limitation of existing solutions, we design and implement a general curriculum learning library emphasizing the extensibility. It consists of three components as shown in Figure 2 below (top part). First, we use a data analyzer to perform the offline CPU-only data analysis which indexes the whole data pool based on any difficulty metric such as the sequence length, the vocabulary rarity, or anything defined by user. Next, during training, the curriculum scheduler determines the difficulty threshold for the current step based on a pacing function such as linear, rooted, or any strategy provided by users. Then the data sampler will sample the data with desired difficulty from the indexed data pool. Overall, this general implementation would enable users to explore curriculum learning on their workloads with maximum customizability (more technical details in our DeepSpeed Data Efficiency paper).
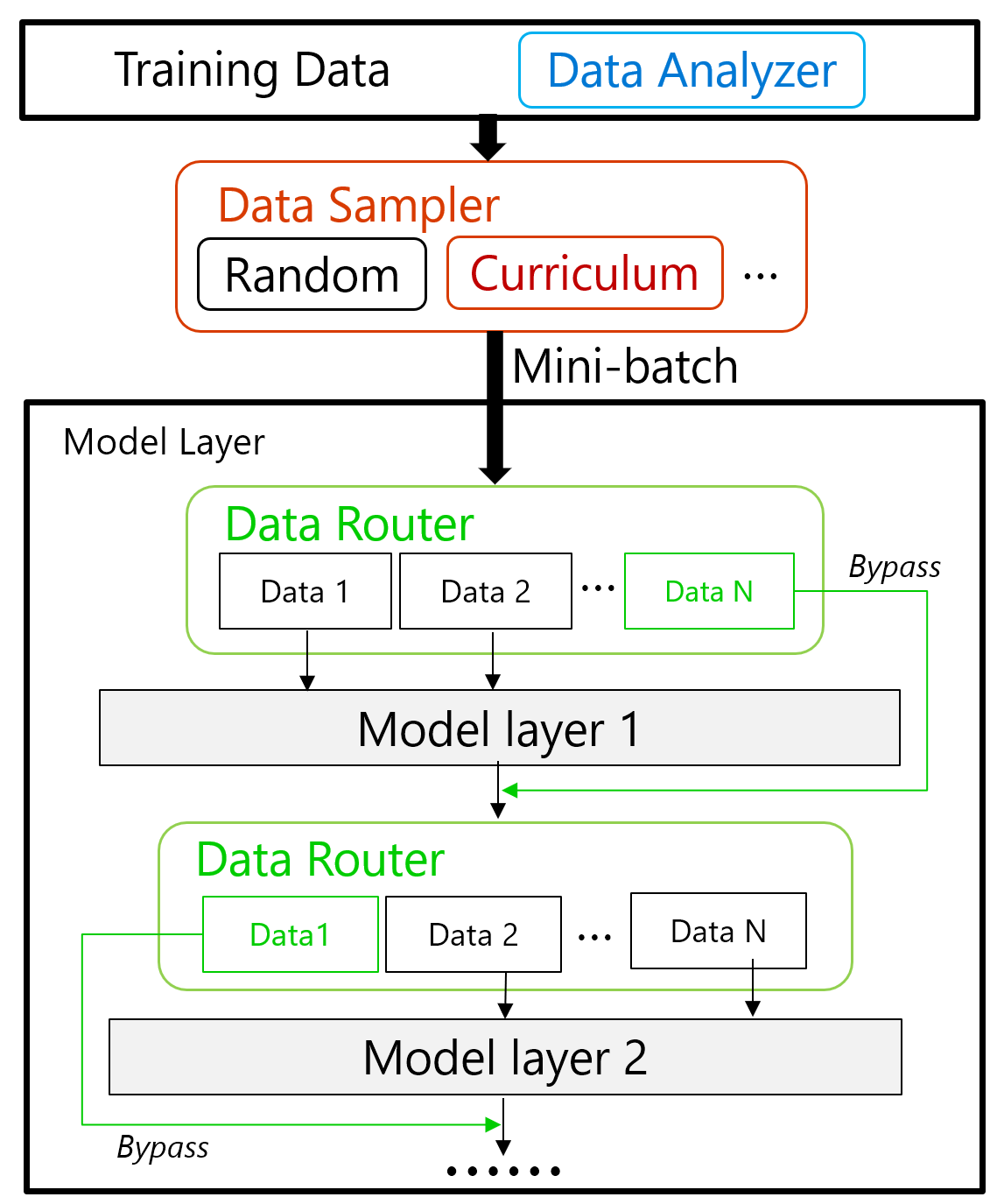
Figure 2: Design of the DeepSpeed Data Efficiency framework.
Evaluation Results
Using this general and extensible curriculum learning solution for GPT-3 and BERT-Large model pretraining, we are able to easily analyze and index the huge training data based on up to 7 difficulty metrics and enable better data and training efficiency. For GPT-3 pretraining, our solution with the best difficulty metric (combination of truncation-based sequence length and vocabulary rarity) achieves 1.5x data and training cost saving while still maintaining model quality as baseline (Table 1 Case (8) vs. (1)). For BERT-Large pretraining, our solution with the best difficulty metric (vocabulary rarity) achieves 1.5x saving while still maintaining model quality (Table 2 Case (8) vs. (1)). On the other hand, our solutions can further improve model quality when using the same amount of data as baseline (Table 1 Case (2) to (6), Table 2 Case (2) to (6)).
| Case | Pretrain data | Avg 0-shot accuracy | Avg 10-shot accuracy |
|---|---|---|---|
| (1) Baseline | 300B | 42.5 | 44.0 |
| (2) CL truncation-based sequence length | 300B | 43.4 | 44.8 |
| (3) CL reshape-based sequence length | 300B | 43.0 | 44.5 |
| (4) CL vocabulary rarity | 300B | 42.3 | 44.5 |
| (5) CL combining (2) and (4) | 300B | 43.6 | 44.9 |
| (6) CL combining (3) and (4) | 300B | 43.0 | 44.4 |
| (7) Baseline | 200B (1.5x) | 41.9 | 44.0 |
| (8) CL combining (2) and (4) | 200B (1.5x) | 42.7 | 44.5 |
Table 1: GPT-3 1.3B pretraining data consumption and average evaluation accuracy on 19 tasks.
| Case | Pretrain data | GLUE finetune score |
|---|---|---|
| (1) Baseline | 1049B | 87.29 |
| (2) CL truncation-based sequence length | 1049B | 87.31 |
| (3) CL reorder-based sequence length | 1049B | 87.48 |
| (4) CL vocabulary rarity | 1049B | 87.36 |
| (5) CL combining (2) and (4) | 1049B | 87.60 |
| (6) CL combining (3) and (4) | 1049B | 87.06 |
| (7) Baseline | 703B (1.5x) | 87.19 |
| (8) CL combining (2) and (4) | 703B (1.5x) | 87.29 |
Table 2: BERT-Large pretraining data consumption and average GLUE finetuning score on 8 tasks.
Efficient Data Routing via Random Layerwise Token Dropping
Motivation
Standard data routing usually feeds the full images/sequences into all layers of a model. However, this process may not be optimal for training efficiency since some parts of an image (or words of a sentence) do not require a frequent feature update. As such, the token dropping method has been proposed, which is illustrated in Figure 3 (b) below, to skip the compute of some tokens/words (i.e., G-2 tokens in Figure 3 (b)) of a sentence in order to save the compute cost.
Although existing methods show promising results, they also exhibit several caveats: (1) most works solely focus on BERT (encoder-only on text data) pretraining and do not include decoder pretraining and/or other modalities (e.g., images); (2) the ability to skip layers is limited, which bounds the total amount of compute saving. By analyzing existing methods, we found out the potential main issue that limits their skipping and coverage abilities is the loss of attention mechanism for G-2 tokens for all skipped layers, since multi-head attention focuses on different tokens at different layer depths and the attention map aligns with the dependency relation most strongly in the middle of transformer architectures.
Design
To resolve this main issue, we propose random-LTD, a random and layerwise token dropping mechanism, which processes only a subset of tokens among the entire data batch for all middle layers in order to save compute cost (see more details in our Random-LTD paper). As such, each token rarely bypasses all middle layers and its dependency with other tokens can be captured by the model. The illustration of random-LTD compared to baseline is shown in Figure 3 below, where random-LTD splits the input tokens into two groups and only the first group involves the compute.
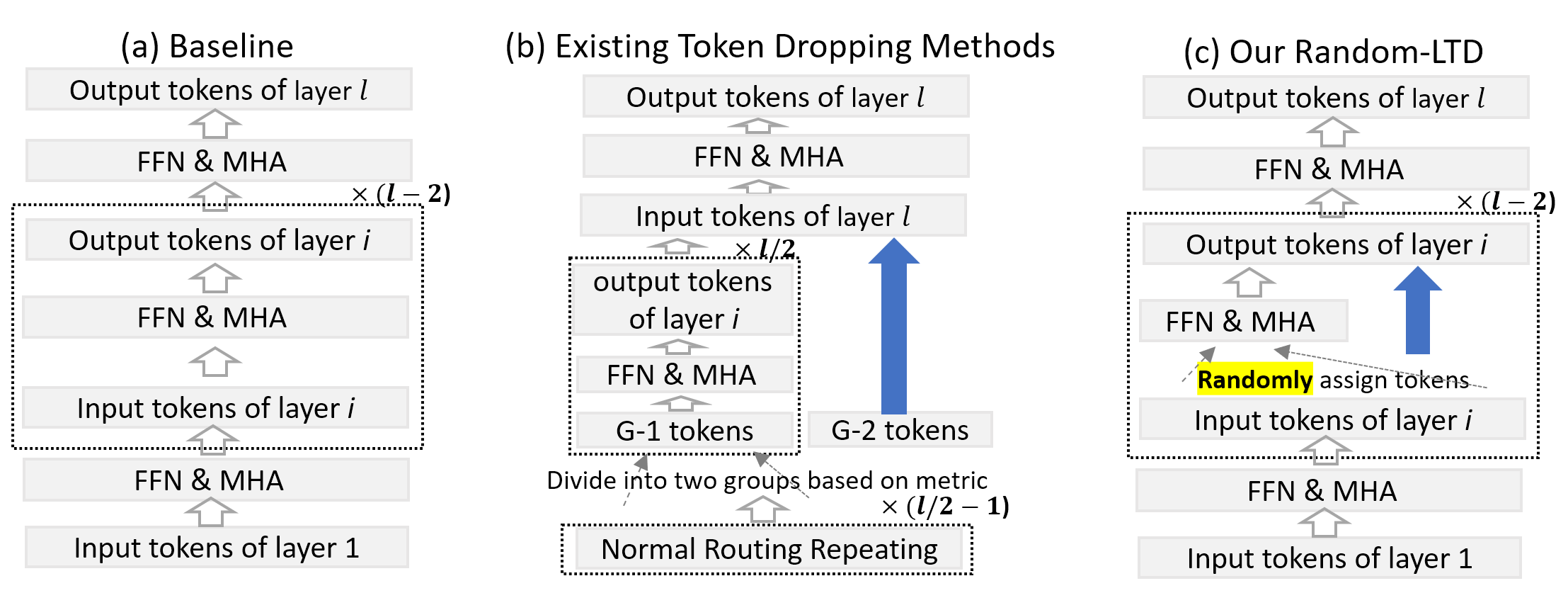
Figure 3: Comparison between baseline, existing token dropping methods, and random-LTD. Note that for random-LTD, only part of the inputs (Group 1) is used for Layer i.
Random-LTD is simple yet very effective. Particularly, compared to other existing token dropping methods, random-LTD (1) does a purely random selection for each layer for two different groups, as such we do not require any expert design for the selection criterion; (2) is able to apply to all middle layers to achieve better saving ratio; (3) demonstrates great generalizability for both encoder and decoder models; and (4) is easy to use without much modeling change. These advantages enable maximum flexibility when applying random-LTD to various workloads.
Evaluation Results
Thanks to its great flexibility, we were able to apply random-LTD method to broader applications, including BERT and GPT pretraining as well as ViT and GPT finetuning tasks. For all cases, random-LTD achieves similar model quality as baseline while using less data, and/or achieve better model quality while using the same amount of data (Table 3 to 6). For GPT-3 and BERT-Large pretraining, random-LTD achieves 1.5-2x data saving while still maintaining the same model quality. For GPT-3 we also tested random-LTD with full data which further improves the model quality compared to baseline.
| Case | Pretrain data | Avg 0-shot accuracy |
|---|---|---|
| (1) Baseline | 300B | 42.5 |
| (2) Random-LTD | 300B | 43.7 |
| (3) Random-LTD | 200B (1.5x) | 42.5 |
Table 3: GPT-3 1.3B pretraining data consumption and average evaluation accuracy on 19 tasks.
| Case | Pretrain data | GLUE finetune score |
|---|---|---|
| (1) Baseline | 1049B | 87.29 |
| (2) Random-LTD | 524B (2x) | 87.32 |
Table 4: BERT-Large pretraining data consumption and average GLUE finetuning score on 8 tasks.
| Case | Train data | ImageNet Top-1 Acc |
|---|---|---|
| (1) Baseline | 100% | 84.65 |
| (2) Random-LTD | 77.7% (1.3x) | 84.70 |
Table 5: Finetuning result of ViT on ImageNet.
| Case | Train data | PTB PPL |
|---|---|---|
| (1) Baseline | 100% | 16.11 |
| (2) Random-LTD | 100% | 15.9 |
Table 6: GPT-2 350M finetuning result on the PTB task.
Composing Data Efficiency Techniques to Achieve More
The curriculum learning and random-LTD techniques are complementary. Inside DeepSpeed Data Efficiency framework, we seamlessly compose the two techniques as shown in Figure 2 above, where curriculum learning helps to sample the next data batch and random-LTD helps to decide how to route each sampled data inside the model. DeepSpeed Data Efficiency solves several complexities when composing the two techniques so that users can easily apply each technique or both to their training pipeline. The composability of DeepSpeed Data Efficiency also applies to data sampling and routing techniques in general, so that it provides a platform to implement and compose additional data efficiency techniques.
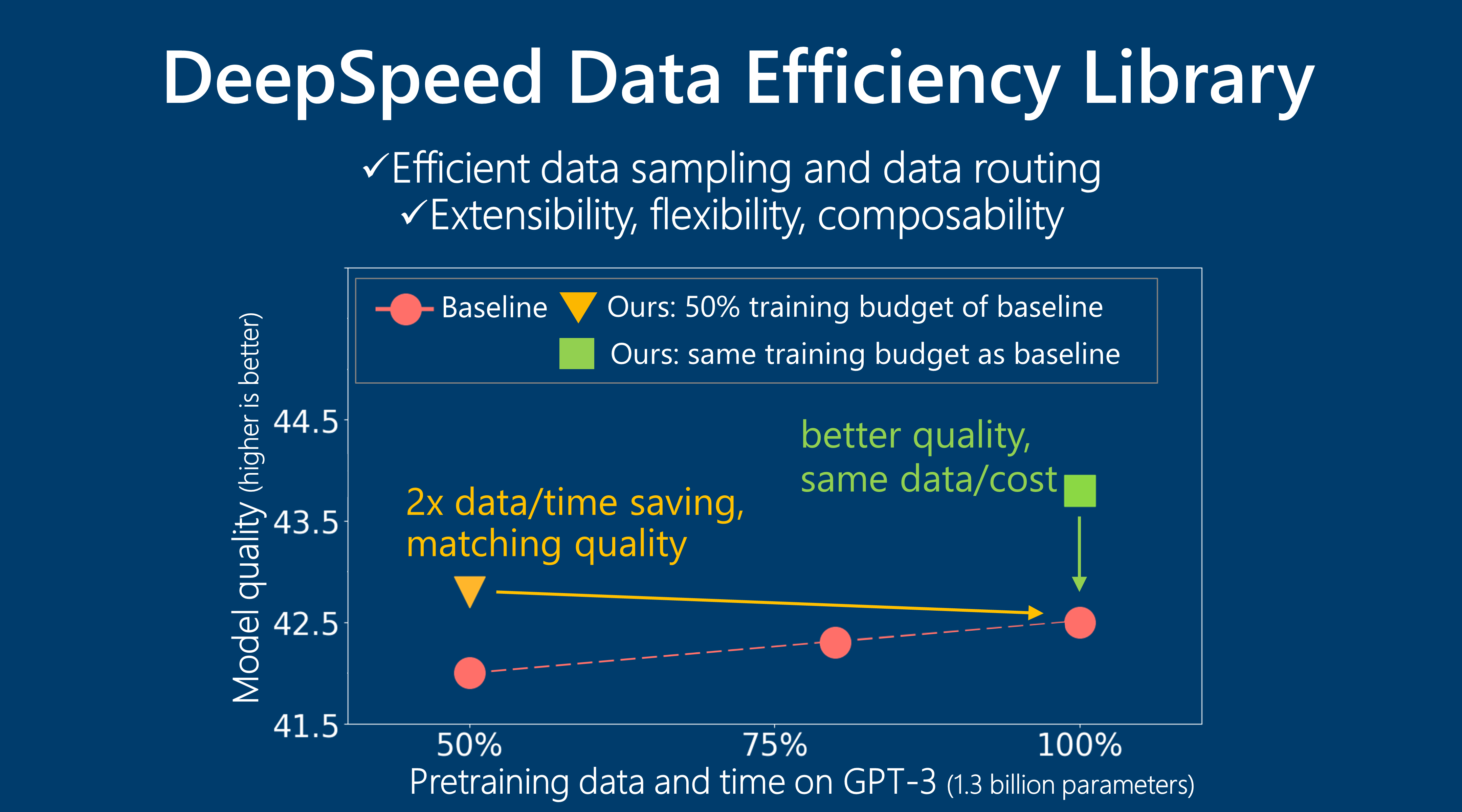
The composed DeepSpeed Data Efficiency solution leverages both data efficiency techniques and achieves even better data and training efficiency. Take the GPT-3 pretraining task as an example, composing CL and random-LTD, with 100% data, leads to the best model quality in our experiments (Table 7 Case (1) to (4)). When pretraining with 50% data, the baseline training results in worse zero-shot and 10-shot evaluation accuracy, and using either CL or random-LTD can only recover part of the 10-shot accuracy loss. On the other hand, the composed data efficiency solution achieves the same or better accuracy results as baseline with 100% data, demonstrating a 2x data and 2x time saving (Case (5) to (8)). Similar benefit such as 2x data saving was also observed when applying our solution to BERT pretraining.
| Case | Pretrain data | Pretrain time (on 64 V100) | Avg 0-shot accuracy | Avg 10-shot accuracy |
|---|---|---|---|---|
| (1) Baseline | 300B | 260hr | 42.5 | 44.0 |
| (2) CL best metric | 300B | 259hr | 43.6 | 44.9 |
| (3) random-LTD | 300B | 263hr | 43.7 | 44.9 |
| (4) CL + random-LTD | 300B | 260hr | 43.8 | 45.1 |
| (5) Baseline | 150B (2x) | 130hr (2x) | 42.0 | 42.7 |
| (6) CL best metric | 150B (2x) | 129hr (2x) | 42.6 | 43.7 |
| (7) random-LTD | 150B (2x) | 131hr (2x) | 42.7 | 43.5 |
| (8) CL + random-LTD | 150B (2x) | 130hr (2x) | 42.8 | 44.0 |
Table 7: GPT-3 1.3B pretraining data/time consumption and average evaluation accuracy on 19 tasks.
Concluding Remarks
We are very excited to share DeepSpeed Data Efficiency library with the community and improve it with your feedback. Please find the code, tutorial, and documents at the DeepSpeed GitHub, and website. And for more technical details please read our Random-LTD paper and DeepSpeed Data Efficiency paper. We believe that our composable library and novel data efficiency techniques will help users reduce training cost while maintaining model quality or achieve better quality under similar cost. And we hope DeepSpeed Data Efficiency could become a platform that motivates and accelerates future research on deep learning data efficiency.