Scaling Large-Scale Generative Mixture-of-Expert Multimodal Model With VL-MoE
The field of Artificial Intelligence-Generated Content (AIGC) is rapidly growing, with the goal of making content creation more efficient and accessible. One of the most exciting areas of AIGC is the development of large-scale multi-modal models like Flamingo, BLIP, and GPT4, which can accept inputs from multiple resources, e.g., image, text, audio, etc., and generate a variety of formats as outputs. For example, image creation can be made through stable diffusion and DALLE using the prompt text, and the new feature in the coming Office can create slides with texts, images, animations, etc., by leveraging the power of the new Microsoft Office Copilot.
Scaling up the model size is one common approach to boost usability and capability of AIGC tasks. However, simply scaling up dense architectures (e.g., from GPT-1 to GPT-3) is usually extremely resource-intensive and time-consuming for both model training and inference. One effective way to tackle this challenge is to apply mixture of experts (MoE). In particular, recent text-based MoE and vision-based MoE studies have demonstrated that MoE models can significantly reduce the training and resource cost as compared to a quality-equivalent dense model, or produce a higher quality model under the same training budget. Up to now, the effectiveness of jointly training MoE for multi-modal models remains not well understood. To explore this important capability, DeepSpeed team is proud to announce our first large-scale generative mixture-of-expert (MoE) multimodal model, named VL-MoE.
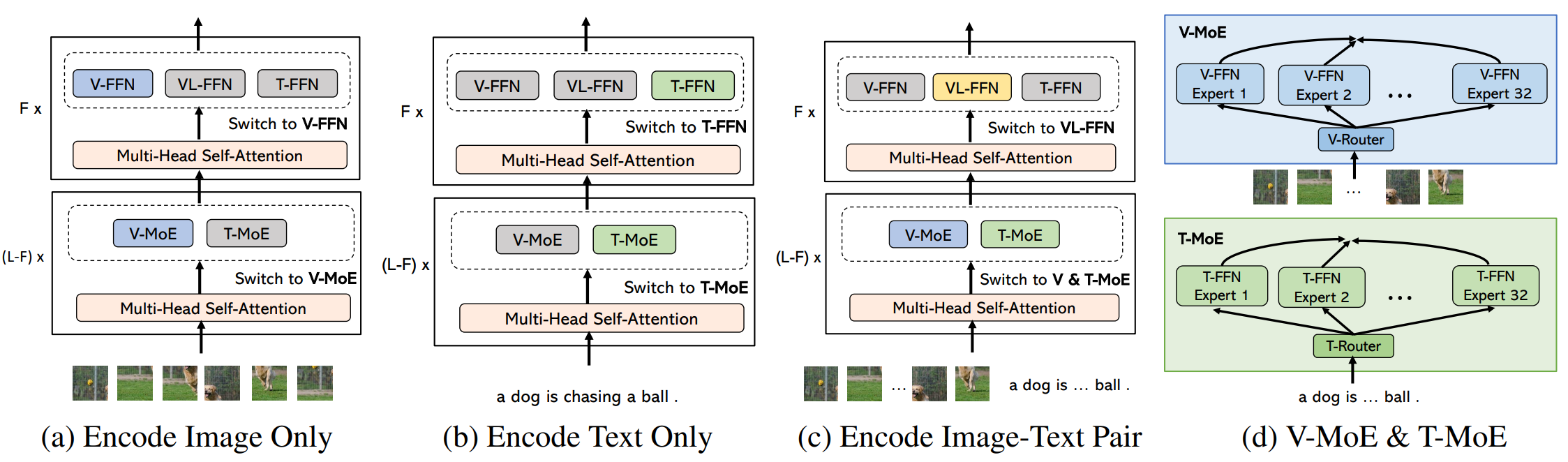
Figure 1: The new encoding process in our VL-MoE for various modality inputs, for which gray and colored blocks indicate non-activated and activated modules, respectively.
Specifically, we incorporate the MoE structure into the classical single-tower multi-modal model by comprising of the following components: (1) a shared self-attention module across modalities, (2) a pool of modality-specific experts in the feed-forward network (FFN), and (3) a sparse gated MoE extended from the dense FFN. Subsequently, under the same amount of training resources as that used in VLMO (200k training steps), we demonstrate VL-MoE’s advantages over the state-of-the-art dense counterparts in the following two aspects:
(1) VL-MoE can achieve significant accuracy improvement in comparison to its dense counterparts. Table 1 demonstrates that under the same training budget (i.e., have the same number of activated parameters for each token), VL-MoE Base with 32 experts achieves better accuracy than the VLMO-Base dense model on all four vision-language datasets.
(2) VL-MoE achieves similar model quality with a much smaller activated number of parameters compared to its dense counterparts. Our results show that the finetuning performance of our VL-MoE is similar to that of the 3.1X larger VLMO-Large dense model (i.e., 3.1X more activated number of parameters per token). This can directly translate to approximately 3.1X training cost reduction as the training FLOPs for transformers are proportional to the activated model size per token.
| Param per Token (# Total Param) | VQA | NLVR2 | COCO | Flickr30K | |
|---|---|---|---|---|---|
| test-dev / std | dev / test-P | TR / IR | TR / IR | ||
| Dense Counterparts | |||||
| VLMO-dense Base | 180M (180M) | 76.64 / 76.89 | 82.77 / 83.34 | 74.8 / 57.2 | 92.3 / 79.3 |
| VLMO-dense Large | 560M (180M) | 79.94 / 79.98 | 85.64 / 86.86 | 78.2 / 60.6 | 95.3 / 84.5 |
| Ours (VL-MoE with 32 Experts) | |||||
| VL-MoE | 180M (1.9B) | 78.23 / 78.65 | 85.54 / 86.77 | 79.4 / 61.2 | 96.1 / 84.9 |
Table 1: Comparison of finetuning accuracy results for different models used in vision-language classification tasks and image-text retrieval tasks.
A sophisticated MoE model design requires a highly efficient and scalable training system that can support multi-dimensional parallelism and efficient memory management. DeepSpeed MoE training system offers such advanced capabilities including easy-to-use APIs enabling flexible combinations of data, tensor, and expert parallelism. Furthermore, DeepSpeed MoE enables larger model scale than state-of-the-art systems by exploiting expert parallelism and ZeRO optimizations together. By leveraging the DeepSpeed MoE system, VL-MoE Base with 32 experts achieves similar model quality as VLMO-dense Large with about 2.5x training speedup.
DeepSpeed MoE system is already open-sourced and can be easily used as plug-and-play component to achieve high-performance low-cost training for any large-scale MoE models. The tutorial of how to use DeepSpeed MoE is available here. VL-MoE is currently in the process of being integrated as a model example of DeepSpeed Examples. Please stay tuned for our upcoming updates on this thread.