Training Overview and Features
Overview
Training advanced deep learning models is challenging. Beyond model design, model scientists also need to set up the state-of-the-art training techniques such as distributed training, mixed precision, gradient accumulation, and checkpointing. Yet still, scientists may not achieve the desired system performance and convergence rate. Large model sizes are even more challenging: a large model easily runs out of memory with pure data parallelism and it is difficult to use model parallelism. DeepSpeed addresses these challenges to accelerate model development and training.
Distributed, Effective, and Efficient Training with Ease
The DeepSpeed API is a lightweight wrapper on PyTorch. This means that you can use everything you love in PyTorch and without learning a new platform. In addition, DeepSpeed manages all of the boilerplate state-of-the-art training techniques, such as distributed training, mixed precision, gradient accumulation, and checkpoints so that you can focus on your model development. Most importantly, you can leverage the distinctive efficiency and effectiveness benefit of DeepSpeed to boost speed and scale with just a few lines of code changes to your PyTorch models.
Speed
DeepSpeed achieves high performance and fast convergence through a combination of efficiency optimizations on compute/communication/memory/IO and effectiveness optimizations on advanced hyperparameter tuning and optimizers. For example:
-
DeepSpeed trains BERT-large to parity in 44 mins using 1024 V100 GPUs (64 DGX-2 boxes) and in 2.4 hours using 256 GPUs (16 DGX-2 boxes).
BERT-large Training Times
Devices Source Training Time 1024 V100 GPUs DeepSpeed 44 min 256 V100 GPUs DeepSpeed 2.4 hr 64 V100 GPUs DeepSpeed 8.68 hr 16 V100 GPUs DeepSpeed 33.22 hr BERT code and tutorials will be available soon.
-
DeepSpeed trains GPT2 (1.5 billion parameters) 3.75x faster than state-of-art, NVIDIA Megatron on Azure GPUs.
Read more: GPT tutorial
Memory efficiency
DeepSpeed provides memory-efficient data parallelism and enables training models without model parallelism. For example, DeepSpeed can train models with up to 13 billion parameters on a single GPU. In comparison, existing frameworks (e.g., PyTorch’s Distributed Data Parallel) run out of memory with 1.4 billion parameter models.
DeepSpeed reduces the training memory footprint through a novel solution called Zero Redundancy Optimizer (ZeRO). Unlike basic data parallelism where memory states are replicated across data-parallel processes, ZeRO partitions model states and gradients to save significant memory. Furthermore, it also reduces activation memory and fragmented memory. The current implementation (ZeRO-2) reduces memory by up to 8x relative to the state-of-art. You can read more about ZeRO in our paper, and in our blog posts related to ZeRO-1 and ZeRO-2.
With this impressive memory reduction, early adopters of DeepSpeed have already produced a language model (LM) with over 17B parameters called Turing-NLG, establishing a new SOTA in the LM category.
For model scientists with limited GPU resources, ZeRO-Offload leverages both CPU and GPU memory for training large models. Using a machine with a single GPU, our users can run models of up to 13 billion parameters without running out of memory, 10x bigger than the existing approaches, while obtaining competitive throughput. This feature democratizes multi-billion-parameter model training and opens the window for many deep learning practitioners to explore bigger and better models.
Scalability
DeepSpeed supports efficient data parallelism, model parallelism, pipeline parallelism and their combinations, which we call 3D parallelism.
- 3D parallelism of DeepSpeed provides system support to run models with trillions of parameters, read more in our press-release and tutorial.
-
DeepSpeed can run large models more efficiently, up to 10x faster for models with various sizes spanning 1.5B to hundred billion. More specifically, the data parallelism powered by ZeRO is complementary and can be combined with different types of model parallelism. It allows DeepSpeed to fit models using lower degree of model parallelism and higher batch size, offering significant performance gains compared to using model parallelism alone.
Read more: ZeRO paper, and GPT tutorial.
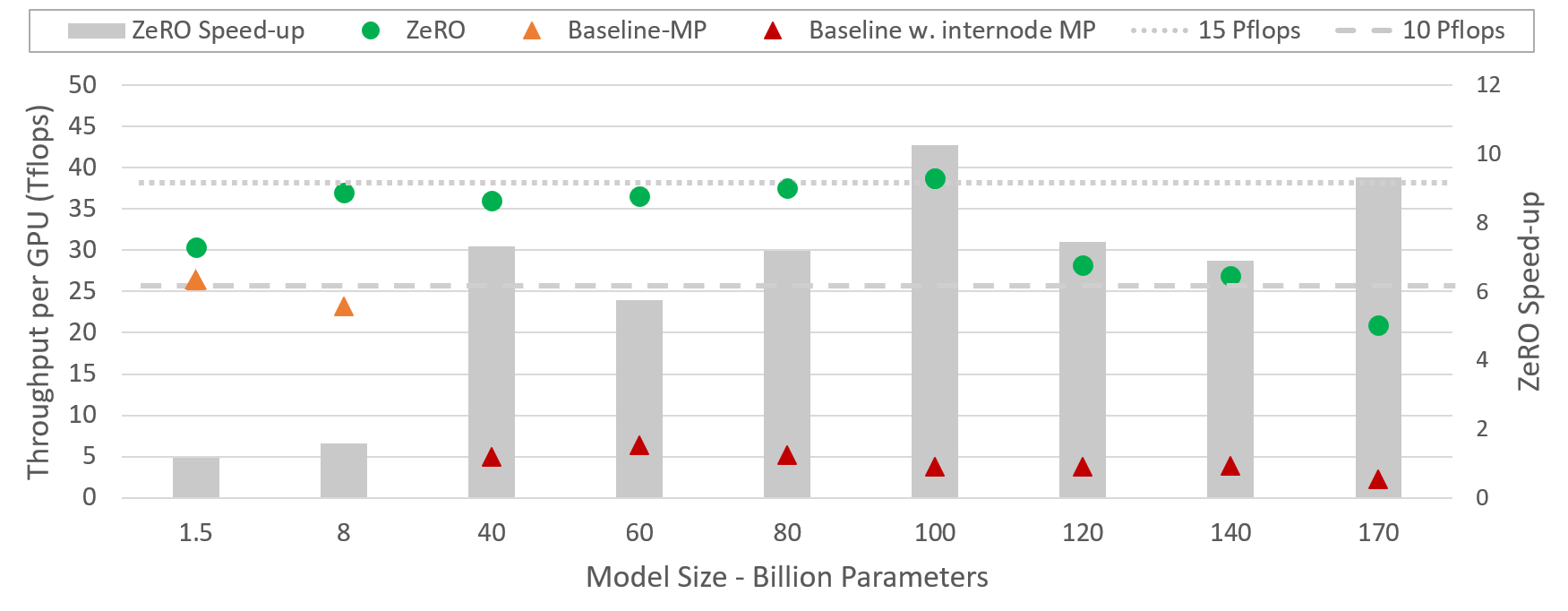
The figure depicts system throughput improvements of DeepSpeed (combining ZeRO-powered data parallelism with model parallelism of NVIDIA Megatron-LM) over using Megatron-LM alone.
Communication efficiency
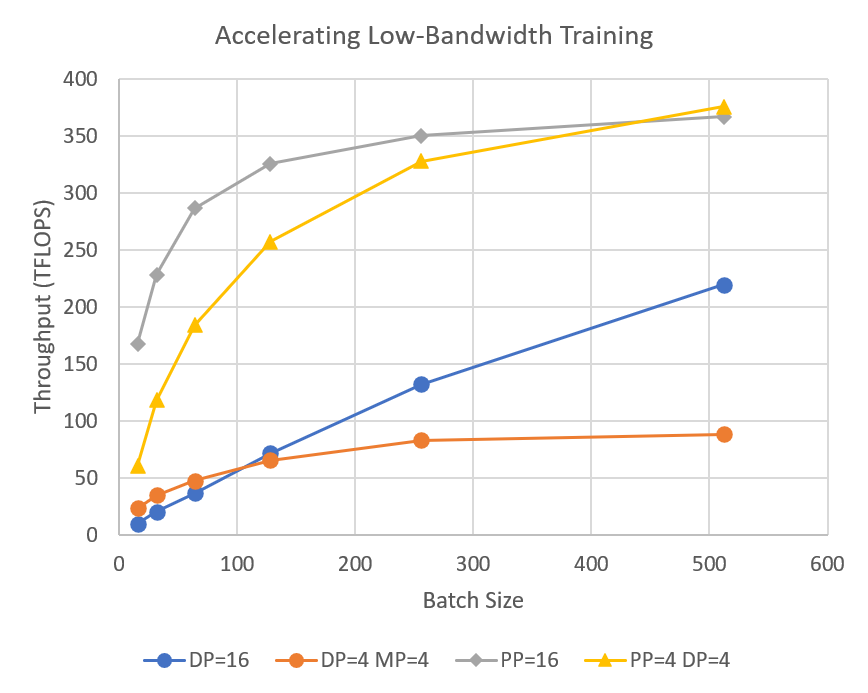
Pipeline parallelism of DeepSpeed reduce communication volume during distributed training, which allows users to train multi-billion-parameter models 2–7x faster on clusters with limited network bandwidth.
1-bit Adam, 0/1 Adam and 1-bit LAMB reduce communication volume by up to 26x while achieving similar convergence efficiency to Adam, allowing for scaling to different types of GPU clusters and networks. 1-bit Adam blog post, 1-bit Adam tutorial, 0/1 Adam tutorial, 1-bit LAMB tutorial.
Data efficiency
DeepSpeed Data Efficiency Library provides efficient data sampling via curriculum learning and efficient data routing via random layerwise token dropping. The composed solution enables up to 2x data and 2x time saving during GPT-3/BERT pretraining and GPT/ViT finetuning, or further improve model quality under the same data/time. See more in the tutorial.
Supporting long sequence length
DeepSpeed offers sparse attention kernels—an instrumental technology to support long sequences of model inputs, whether for text, image, or sound. Compared with the classic dense Transformers, it powers an order-of-magnitude longer input sequence and obtains up to 6x faster execution with comparable accuracy. It also outperforms state-of-the-art sparse implementations with 1.5–3x faster execution. Furthermore, our sparse kernels support efficient execution of flexible sparse format and empower users to innovate on their custom sparse structures. Read more here.
Fast convergence for effectiveness
DeepSpeed supports advanced hyperparameter tuning and large batch size optimizers such as LAMB. These improve the effectiveness of model training and reduce the number of samples required to convergence to desired accuracy.
Read more: Tuning tutorial.
Good Usability
Only a few lines of code changes are needed to enable a PyTorch model to use DeepSpeed and ZeRO. Compared to current model parallelism libraries, DeepSpeed does not require a code redesign or model refactoring. It also does not put limitations on model dimensions (such as number of attention heads, hidden sizes, and others), batch size, or any other training parameters. For models of up to 13 billion parameters, you can use ZeRO-powered data parallelism conveniently without requiring model parallelism, while in contrast, standard data parallelism will run out of memory for models with more than 1.4 billion parameters. In addition, DeepSpeed conveniently supports flexible combination of ZeRO-powered data parallelism with custom model parallelisms, such as tensor slicing of NVIDIA’s Megatron-LM.
Features
Below we provide a brief feature list, see our detailed feature overview for descriptions and usage.
- Distributed Training with Mixed Precision
- 16-bit mixed precision
- Single-GPU/Multi-GPU/Multi-Node
- Model Parallelism
- Support for Custom Model Parallelism
- Integration with Megatron-LM
- Pipeline Parallelism
- 3D Parallelism
- The Zero Redundancy Optimizer
- Optimizer State and Gradient Partitioning
- Activation Partitioning
- Constant Buffer Optimization
- Contiguous Memory Optimization
- ZeRO-Offload
- Leverage both CPU/GPU memory for model training
- Support 10B model training on a single GPU
- Ultra-fast dense transformer kernels
- Sparse attention
- Memory- and compute-efficient sparse kernels
- Support 10x long sequences than dense
- Flexible support to different sparse structures
- 1-bit Adam, 0/1 Adam and 1-bit LAMB
- Custom communication collective
- Up to 26x communication volume saving
- Additional Memory and Bandwidth Optimizations
- Smart Gradient Accumulation
- Communication/Computation Overlap
- Training Features
- Simplified training API
- Gradient Clipping
- Automatic loss scaling with mixed precision
- Training Optimizers
- Fused Adam optimizer and arbitrary
torch.optim.Optimizer - Memory bandwidth optimized FP16 Optimizer
- Large Batch Training with LAMB Optimizer
- Memory efficient Training with ZeRO Optimizer
- CPU-Adam
- Fused Adam optimizer and arbitrary
- Training Agnostic Checkpointing
- Advanced Parameter Search
- Learning Rate Range Test
- 1Cycle Learning Rate Schedule
- Simplified Data Loader
- Data Efficiency
- Efficient data sampling via curriculum learning and efficient data routing via random layerwise token dropping
- Up to 2x data and 2x time saving during GPT-3/BERT pretraining and GPT/ViT finetuning
- Or further improve model quality under the same data/time
- Curriculum Learning
- A curriculum learning-based data pipeline that presents easier or simpler examples earlier during training
- Stable and 3.3x faster GPT-2 pre-training with 8x/4x larger batch size/learning rate while maintaining token-wise convergence speed
- Complementary to many other DeepSpeed features
- Note that the Data Efficiency Library above provides more general curriculum learning support. This legacy curriculum learning feature is still supported but we recommend to use the Data Efficiency Library.
- Progressive Layer Dropping
- Efficient and robust compressed training
- Up to 2.5x convergence speedup for pre-training
- Performance Analysis and Debugging
- Mixture of Experts (DeepSpeed MoE)
title: “Feature Overview” layout: single permalink: /features/ toc: true toc_label: “Contents” —
Distributed Training with Mixed Precision
Mixed Precision Training
Enable 16-bit (FP16) training by in the deepspeed_config JSON.
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"consecutive_hysteresis": false,
"min_loss_scale": 1
}
Single-GPU, Multi-GPU, and Multi-Node Training
Easily switch between single-GPU, single-node multi-GPU, or multi-node multi-GPU execution by specifying resources with a hostfile.
deepspeed --hostfile=<hostfile> \
<client_entry.py> <client args> \
--deepspeed --deepspeed_config ds_config.json
The script <client_entry.py> will execute on the resources specified in
<hostfile>.
Pipeline Parallelism
DeepSpeed provides pipeline parallelism for memory- and communication- efficient training. DeepSpeed supports a hybrid combination of data, model, and pipeline parallelism and has scaled to over one trillion parameters using 3D parallelism. Pipeline parallelism can also improve communication efficiency and has accelerated training by up to 7x on low-bandwidth clusters.
Model Parallelism
Support for Custom Model Parallelism
DeepSpeed supports all forms of model parallelism including tensor slicing
based approaches such as the
Megatron-LM. It does so by only
requiring the model parallelism framework to provide a model parallelism
unit (mpu) that implements a few bookkeeping functionalities:
mpu.get_model_parallel_rank()
mpu.get_model_parallel_group()
mpu.get_model_parallel_world_size()
mpu.get_data_parallel_rank()
mpu.get_data_parallel_group()
mpu.get_data_parallel_world_size()
Integration with Megatron-LM
DeepSpeed is fully compatible with Megatron. Please see the Megatron-LM tutorial for details.
The Zero Redundancy Optimizer
The Zero Redundancy Optimizer (ZeRO) is at the heart of DeepSpeed and enables large model training at a scale that is simply not possible with model parallelism alone. When enabled, ZeRO allows training models with over 13 billion parameters without any model parallelism, and up to 200 billion parameter models with model parallelism on current generation hardware.
For more details see the ZeRO paper, GPT tutorial on integration with DeepSpeed.
Optimizer State and Gradient Partitioning
Optimizer State and Gradient Partitioning in ZeRO reduces the memory consumption of the model states (optimizer states, gradients and parameters) by 8x compared to standard data parallelism by partitioning these states across data parallel process instead of replicating them.
Activation Partitioning
Activation Partitioning is a memory optimization in ZeRO that can reduce the memory consumed by activations during model parallel training (MP). In MP certain activations maybe required by all MP processes, resulting in a replication of activations across MP GPUs. Activation Partitioning stores these activations in a partitioned state once they are used for computation in the forward propagation. These activations are allgathered right before they are needed again during the backward propagation. By storing activations in a partitioned state, ZeRO in DeepSpeed can reduce the activation memory footprint proportional to the MP degree.
Constant Buffer Optimization (CBO)
CBO enables high network and memory throughput while restricting memory usage to a constant size. For memory- and network-bound operations such as normalization or allreduce collectives, the performance depends on the size of the operand. Simply fusing all operands into a single large operand can enable great throughput at the expense of unnecessary memory overhead. CBO in DeepSpeed fuses smaller operands into approximately a pre-defined sized buffer large enough to achieve great performance without the unnecessary memory overhead.
Contiguous Memory Optimization (CMO)
CMO reduces memory fragmentation during training, preventing out of memory errors due to lack of contiguous memory. Memory fragmentation is a result of interleaving between short lived and long lived memory objects. During the forward propagation activation checkpoints are long lived but the activations that recomputed are short lived. Similarly, during the backward computation, the activation gradients are short lived while the parameter gradients are long lived. CMO transfers activation checkpoints and parameter gradients to contiguous buffers preventing memory fragmentation.
ZeRO-Offload
ZeRO-Offload pushes the boundary of the maximum model size that can be trained efficiently using minimal GPU resources, by exploiting computational and memory resources on both GPUs and their host CPUs. It allows training up to 13-billion-parameter models on a single NVIDIA V100 GPU, 10x larger than the state-of-the-art, while retaining high training throughput of over 30 teraflops per GPU.
For more details see the ZeRO-Offload release blog, and tutorial on integration with DeepSpeed.
Additional Memory and Bandwidth Optimizations
Smart Gradient Accumulation
Gradient accumulation allows running larger batch size with limited memory by breaking an
effective batch into several sequential micro-batches, and averaging the parameter
gradients across these micro-batches. Furthermore, instead of averaging the gradients of
each micro-batch across all GPUs, the gradients are averaged locally during each step of
the sequence, and a single allreduce is done at the end of the sequence to produce the
averaged gradients for the effective batch across all GPUs. This strategy significantly
reduces the communication involved over the approach of averaging globally for each
micro-batch, specially when the number of micro-batches per effective batch is large.
Communication Overlapping
During back propagation, DeepSpeed can overlap the communication required for averaging parameter gradients that have already been computed with the ongoing gradient computation. This computation-communication overlap allows DeepSpeed to achieve higher throughput even at modest batch sizes.
Training Features
Simplified training API
The DeepSpeed core API consists of just a handful of methods:
- initialization:
initialize - training:
backwardandstep - argument parsing:
add_config_arguments - checkpointing :
load_checkpointandstore_checkpoint
DeepSpeed supports most of the features described in this document, via the use of these API,
along with a deepspeed_config JSON file for enabling and disabling the features.
Please see the core API doc for more details.
Activation Checkpointing API
DeepSpeed’s Activation Checkpointing API supports activation checkpoint partitioning, cpu checkpointing, and contiguous memory optimizations, while also allowing layerwise profiling. Please see the core API doc for more details.
Gradient Clipping
{
"gradient_clipping": 1.0
}
DeepSpeed handles gradient clipping under the hood based on the max gradient norm specified by the user. Please see the core API doc for more details.
Automatic loss scaling with mixed precision
DeepSpeed internally handles loss scaling for mixed precision training. The parameters
for loss scaling can be specified in the deepspeed_config JSON file.
Please see the core API doc for more details.
Training Optimizers
1-bit Adam, 0/1 Adam and 1-bit LAMB optimizers with up to 26x less communication
DeepSpeed has three communication-efficient optimizers called 1-bit Adam, 0/1 Adam and 1-bit LAMB. They offer the same convergence as Adam/LAMB, incur up to 26x less communication that enables up to 6.6x higher throughput for BERT-Large pretraining and up to 2.7x higher throughput for SQuAD fine-tuning on bandwidth-limited clusters. For more details on usage and performance, please refer to the 1-bit Adam tutorial, 1-bit Adam blog post, 0/1 Adam tutorial and 1-bit LAMB tutorial. For technical details, please refer to the 1-bit Adam paper, 0/1 Adam paper and 1-bit LAMB paper.
Fused Adam optimizer and arbitrary torch.optim.Optimizer
With DeepSpeed, the user can choose to use a high performance implementation of ADAM from
NVIDIA, or any training optimizer that extends torch’s torch.optim.Optimizer class.
CPU-Adam: High-Performance vectorized implementation of Adam
We introduce an efficient implementation of Adam optimizer on CPU that improves the parameter-update
performance by nearly an order of magnitude. We use the AVX SIMD instructions on Intel-x86 architecture
for the CPU-Adam implementation. We support both AVX-512 and AVX-2 instruction sets. DeepSpeed uses
AVX-2 by default which can be switched to AVX-512 by setting the build flag, DS_BUILD_AVX512 to 1 when
installing DeepSpeed. Using AVX-512, we observe 5.1x to 6.5x speedups considering the model-size between
1 to 10 billion parameters with respect to torch-adam.
Memory bandwidth optimized FP16 Optimizer
Mixed precision training is handled by the DeepSpeed FP16 Optimizer. This optimizer not only handles FP16 training but is also highly efficient. The performance of weight update is primarily dominated by the memory bandwidth, and the achieved memory bandwidth is dependent on the size of the input operands. The FP16 Optimizer is designed to maximize the achievable memory bandwidth by merging all the parameters of the model into a single large buffer, and applying the weight updates in a single kernel, allowing it to achieve high memory bandwidth.
Large Batch Training with LAMB Optimizer
DeepSpeed makes it easy to train with large batch sizes by enabling the LAMB Optimizer. For more details on LAMB, see the LAMB paper.
Memory-Efficient Training with ZeRO Optimizer
DeepSpeed can train models with up to 13 billion parameters without model parallelism, and models with up to 200 billion parameters with 16-way model parallelism. This leap in model size is possible through the memory efficiency achieved via the ZeRO Optimizer. For more details see ZeRO paper .
Training Agnostic Checkpointing
DeepSpeed can simplify checkpointing for you regardless of whether you are using data parallel training, model parallel training, mixed-precision training, a mix of these three, or using the zero optimizer to enable larger model sizes. Please see the Getting Started guide and the core API doc for more details.
Advanced parameter search
DeepSpeed supports multiple Learning Rate Schedules to enable faster convergence for large batch scaling.
Learning Rate Range Test
Please refer to the Learning Rate Range Test tutorial.
1Cycle Learning Rate Schedule
Please refer to the 1Cycle Learning Rate Schedule tutorial.
Simplified Data Loader
DeepSpeed abstracts away data parallelism and model parallelism from the user when it comes to data loading. Users simply provide a PyTorch dataset, and DeepSpeed data loader can automatically handle batch creation appropriately.
Data Efficiency
Please refer to the Data Efficiency tutorial.
Curriculum Learning
Please refer to the Curriculum Learning tutorial. Note that the Data Efficiency Library above provides more general curriculum learning support. This legacy curriculum learning feature is still supported but we recommend to use the Data Efficiency Library.
Performance Analysis and Debugging
DeepSpeed provides a set of tools for performance analysis and debugging.
Wall Clock Breakdown
DeepSpeed provides a detailed breakdown of the time spent
in different parts of the training.
This can be enabled by setting the following in the deepspeed_config file.
{
"wall_clock_breakdown": true,
}
Timing Activation Checkpoint Functions
When activation checkpointing is enabled, profiling the forward and backward time of each checkpoint function can be enabled in the deepspeed_config file.
{
"activation_checkpointing": {
"profile": true
}
}
Flops Profiler
The DeepSpeed flops profiler measures the time, flops and parameters of a PyTorch model and shows which modules or layers are the bottleneck. When used with the DeepSpeed runtime, the flops profiler can be configured in the deepspeed_config file as follows:
{
"flops_profiler": {
"enabled": true,
"profile_step": 1,
"module_depth": -1,
"top_modules": 3,
"detailed": true,
}
}
The flops profiler can also be used as a standalone package. Please refer to the Flops Profiler tutorial for more details.
Autotuning
The DeepSpeed Autotuner uses model information, system information, and heuristics to efficiently tune Zero stage, micro batch size, and other Zero configurations. Using the autotuning feature requires no code change from DeepSpeed users. While "autotuning": {"enabled": true} is the minimal required to enable autotuning, there are other parameters users can define to configure the autotuning process. Below shows major parameters and their default values in the autotuning configuration. Please refer to the Autotuning tutorial for more details.
{
"autotuning": {
"enabled": true,
"results_dir": null,
"exps_dir": null,
"overwrite": false,
"metric": "throughput",
"num_nodes": null,
"num_gpus": null,
"start_profile_step": 3,
"end_profile_step": 5,
"fast": true,
"num_tuning_micro_batch_sizes": 3,
"tuner_type": "model_based",
"tuner_early_stopping": 5,
"tuner_num_trials": 50,
"arg_mappings": null
}
}
The flops profiler can also be used as a standalone package. Please refer to the Flops Profiler tutorial for more details.
Monitor
The DeepSpeed Monitor logs live training metrics to one or more monitoring backends, including PyTorch’s TensorBoard, WandB, or simply to CSV files. The Monitor can be configured with one or more backends in the deepspeed_config file as follows:
{
"tensorboard": {
"enabled": true,
"output_path": "output/ds_logs/",
"job_name": "train_bert"
}
"wandb": {
"enabled": true,
"team": "my_team",
"group": "my_group",
"project": "my_project"
}
"csv_monitor": {
"enabled": true,
"output_path": "output/ds_logs/",
"job_name": "train_bert"
}
}
The Monitor can also be added to log custom metrics and client codes. Please refer to the Monitor tutorial for more details.
Communication Logging
DeepSpeed provides logging of all communication operations launched within deepspeed.comm. The communication logger can be configured in the deepspeed_config file as follows:
{
"comms_logger": {
"enabled": true,
"verbose": false,
"prof_all": true,
"debug": false
}
}
Client codes can then print a summary with a call to deepspeed.comm.log_summary(). For more details and example usage, see the Communication Logging tutorial.
Sparse Attention
DeepSpeed offers sparse attention to support long sequences. Please refer to the Sparse Attention tutorial.
--deepspeed_sparse_attention
"sparse_attention": {
"mode": "fixed",
"block": 16,
"different_layout_per_head": true,
"num_local_blocks": 4,
"num_global_blocks": 1,
"attention": "bidirectional",
"horizontal_global_attention": false,
"num_different_global_patterns": 4
}
Mixture of Experts (MoE)
To learn more about training Mixture of Experts (MoE) models with DeepSpeed, see our tutorial for more details.